
Excel là một công cụ quản lý và phân tích dữ liệu mạnh mẽ. Nó hoàn hảo để báo cáo và tính toán nhanh chóng, nhưng Python sẽ hữu ích khi công việc trở nên lộn xộn, lặp đi lặp lại hoặc quá lớn. Python mở ra khả năng tự động hóa, phân tích nâng cao và tích hợp vượt xa các tính năng tích hợp sẵn của Excel. Thư viện Python như gấu trúc để thao tác dữ liệu và openpyxl để xử lý tệp Excel trực tiếp, hãy thực hiện việc này một cách liền mạch.
Trong hướng dẫn này, chúng tôi sẽ chỉ ra 5 điều bạn có thể làm với Excel + Python.
Hãy xem xét dữ liệu bán hàng mẫu để khám phá 5 điều bạn có thể làm với Excel và Python.
1. Dọn dẹp và chuẩn hóa dữ liệu Excel lộn xộn (Lặp lại)
Dữ liệu trong Excel lộn xộn là điều thường thấy vì dữ liệu trong thế giới thực hiếm khi sạch sẽ. Thông thường, dữ liệu chứa khoảng trắng thừa, viết hoa hỗn hợp, số được lưu dưới dạng văn bản, định dạng không nhất quán, thiếu giá trị, mục nhập trùng lặp hoặc dữ liệu cần cơ cấu lại trước khi phân tích. Vấn đề này làm hỏng các công thức và phân tích.
Python vượt trội trong các nhiệm vụ làm sạch dữ liệu. Bạn có thể viết các tập lệnh chuẩn hóa định dạng dữ liệu trên các tệp khác nhau, điền vào các giá trị còn thiếu bằng các phương pháp thông minh, xóa các bản sao, tách hoặc kết hợp các cột dựa trên mẫu và xác thực dữ liệu theo các quy tắc kinh doanh. Các bước này có thể yêu cầu nhiều giờ thao tác tìm và thay thế thủ công trong Excel. Bằng cách sử dụng Python, bạn có thể tạo một tập lệnh có thể lặp lại để xử lý hàng nghìn hàng trong vài giây.
Giả sử bạn nhận được dữ liệu bán hàng lộn xộn. Hãy sử dụng tập lệnh Python để đọc dữ liệu lộn xộn, dọn dẹp và chuẩn hóa các cột cũng như thêm các trường được tính toán.
- Doanh thu =Đơn vị * Đơn giá
- NetRevenue =Doanh thu * (1 – Chiết khấuPct)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
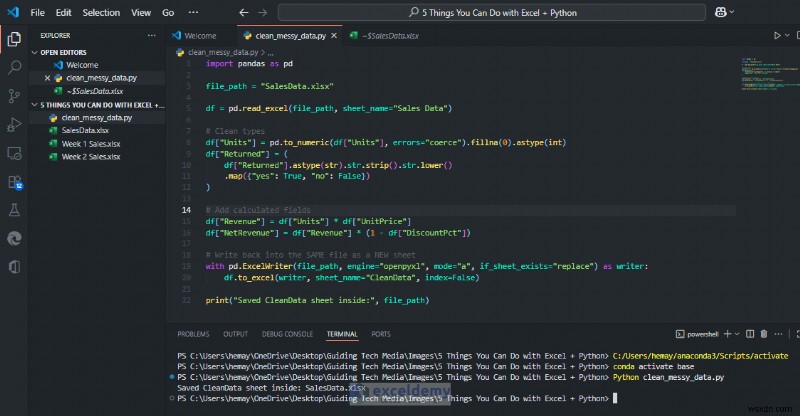
Bạn sẽ nhận được một trang tính mới với tập dữ liệu sạch sẽ không làm hỏng các trục, biểu đồ hoặc tra cứu. Trong Excel, bạn có thể tiếp tục sử dụng các trục/biểu đồ từ dữ liệu đã được làm sạch vì nó nhất quán trong mỗi lần chạy.
2. Tự động tạo tóm tắt (Báo cáo lặp lại)
Excel có giới hạn hàng và có thể làm chậm các phép tính phức tạp. gấu trúc của Python thư viện xử lý các tập dữ liệu lớn một cách hiệu quả và thực hiện các phép tính nhanh hơn nhiều.
Với gấu trúc , bạn có thể làm việc với các tập dữ liệu chứa hàng triệu bản ghi, thực hiện các thao tác nhóm và tổng hợp phức tạp cũng như thực hiện các phân tích thống kê có thể không thực tế trong Excel. Python có thể tạo các bản tóm tắt kiểu trục và xuất chúng sang Excel. Giả sử bạn muốn có một bản tóm tắt nhanh theo Khu vực và Danh mục, nhưng bạn không muốn mỗi lần xây dựng lại các trụ cột.
import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
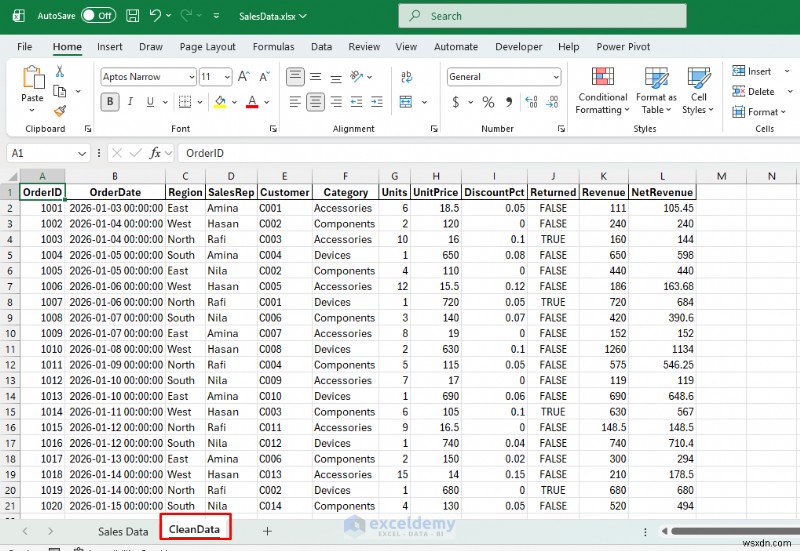
Bạn sẽ nhận được bản tóm tắt doanh thu theo khu vực—một bảng kiểu tổng hợp sẵn sàng chia sẻ, cập nhật bất cứ khi nào bạn chạy lại tập lệnh.
3. Tạo biểu đồ từ dữ liệu Excel (Không cần định dạng thủ công)
Biểu đồ thường là phần tốn nhiều thời gian nhất của báo cáo. Excel cung cấp các biểu đồ tiêu chuẩn nhưng các thư viện trực quan hóa của Python như Matplotlib , Sinh ra ở biển và Có âm mưu mang lại sự linh hoạt và tinh tế hơn rất nhiều. Bạn có thể tạo hình ảnh trực quan tùy chỉnh tự động cập nhật khi dữ liệu của bạn thay đổi, tạo trang tổng quan tương tác mà người dùng có thể khám phá hoặc tạo đồ họa chất lượng xuất bản với khả năng kiểm soát chính xác mọi thành phần.
Hãy trực quan hóa hiệu suất theo khu vực (NetRevenue theo khu vực).
import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
print(f"✅ Chart Created: {output_sheet}")
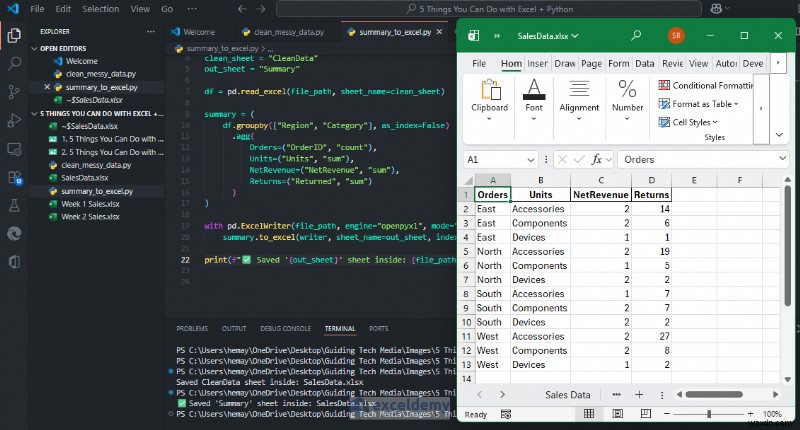
Bây giờ bạn có bản tóm tắt doanh thu theo khu vực cùng với biểu đồ thanh.
4. Hợp nhất nhiều tệp Excel vào một bảng chính
Việc hợp nhất dữ liệu hàng tuần, hàng tháng hoặc hàng quý từ các nguồn khác nhau là điều phổ biến. Việc hợp nhất các tệp Excel từ những người hoặc nhóm khác nhau diễn ra chậm và dễ xảy ra lỗi. Python có thể kết hợp chúng trong vài giây và theo dõi tệp nguồn.
Hãy hợp nhất các tệp hàng tuần vào một thư mục có tên Báo cáo hàng tuần/ (tất cả đều có cùng cột).
import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
Bạn sẽ nhận được một bảng tổng hợp có SourceFile cột để kiểm tra. Hàng tuần bạn chỉ cần chạy script.
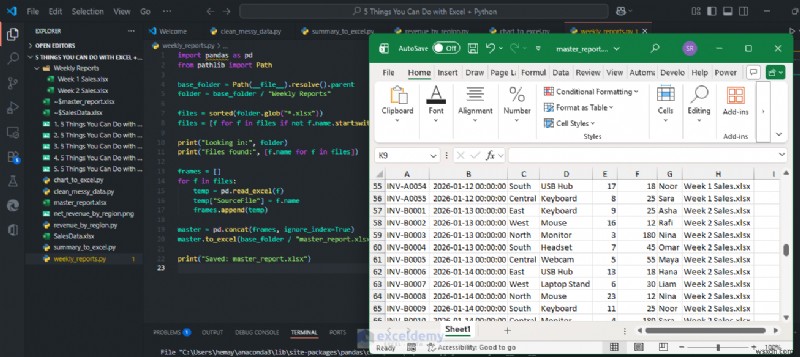
5. Dự đoán điều gì đó Excel không thể thực hiện dễ dàng (Ví dụ về học máy)
Bạn có thể ước tính rủi ro hoàn trả bằng cách sử dụng các mẫu (chiết khấu, danh mục, đơn vị, giá), sau đó viết lại xác suất để người dùng Excel có thể lọc và sắp xếp. Python có thể thực hiện các hoạt động học máy như vậy một cách dễ dàng.
Của chúng tôi là một tập dữ liệu nhỏ; tuy nhiên, nó vẫn hiển thị quy trình làm việc.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
Trong Excel, hãy khám phá WithReturnRisk và lọc ReturnProb từ cao xuống thấp để xem lệnh nào có vẻ rủi ro.
Python trong Excel (Nếu có trong Excel của bạn)
Nếu Excel trên máy tính của bạn có Python (Preview), bạn có thể chạy Python trực tiếp trong một ô và trả kết quả ra sheet. (Xem phần tổng quan của Microsoft về Python trong Excel .) Đây là một ví dụ đơn giản đọc một phạm vi nhỏ, xóa văn bản, tính toán Doanh thu và trả về một bảng sạch.
- Trong Excel, nhập tập dữ liệu của bạn
- Nhấp vào ô trống
- Chuyển tới Công thức tab>> chọn Chèn Python
- Dán tập lệnh Python
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
Nó sẽ trả về DataFrame , đó là đối tượng bảng của Python. Excel hiển thị nó dưới dạng bản xem trước bảng (và thẻ).
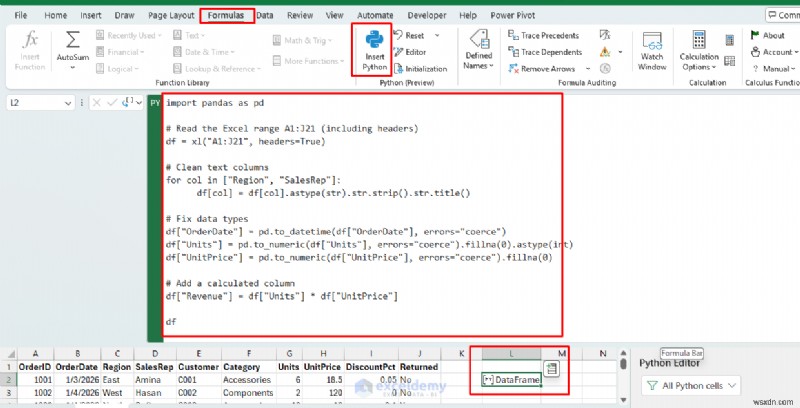
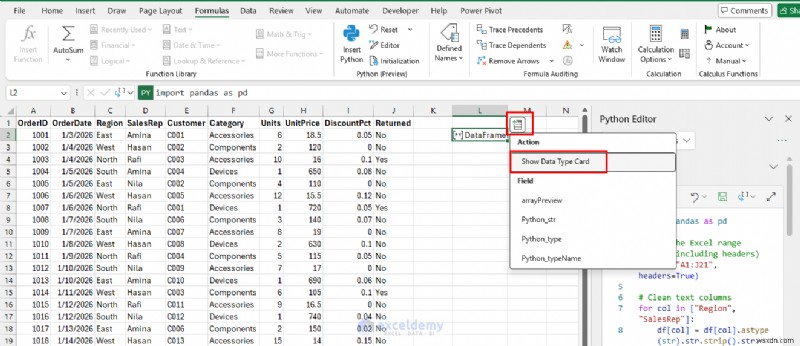
Bây giờ, hãy “đổ” kết quả đầu ra vào các ô dưới dạng một bảng sạch.
- Nhấp vào Chèn dữ liệu từ DataFrame>> chọn Hiển thị thẻ DataType để xem trước bảng
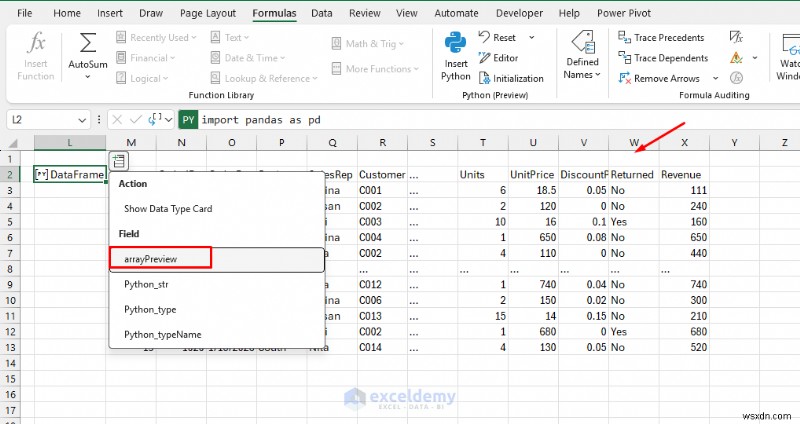
- Chọn xem trước mảng để đưa bảng vào Excel
- Bây giờ bạn có văn bản được chuẩn hóa và Doanh thu mới cột
Kết luận
Bài viết này trình bày năm điều bạn có thể làm với Excel + Python. Excel trở nên mạnh mẽ hơn với Python; việc dọn dẹp các tập dữ liệu lộn xộn, tạo các bản tóm tắt kiểu trục, tự động hóa biểu đồ, hợp nhất nhiều tệp Excel và thêm thông tin chi tiết về máy học trở nên dễ dàng hơn. Việc kết hợp Excel và Python giúp hợp lý hóa quy trình làm việc, từ nhập/xuất dữ liệu đến tự động hóa và trực quan hóa. Bắt đầu với các tập lệnh nhỏ và thử nghiệm với nhiều thư viện hơn.
Nhận MIỄN PHÍ Bài tập Excel nâng cao có Giải pháp!