Theo tôi, bài đăng này nói về hai trong số những điều thú vị nhất trên thế giới:cấu trúc dữ liệu xác suất và mô-đun Redis. Nếu bạn đã nghe về điều này hay điều khác thì chắc chắn bạn có thể liên tưởng đến sự nhiệt tình của tôi, nhưng trong trường hợp bạn muốn cập nhật những điều thú vị nhất trên trái đất, hãy tiếp tục đọc.
Tôi sẽ bắt đầu với tuyên bố này:xử lý dữ liệu quy mô lớn với độ trễ thấp là một thách thức. Khối lượng và vận tốc của dữ liệu liên quan có thể làm cho phân tích thời gian thực trở nên cực kỳ khắt khe. Do hiệu suất cao và tính linh hoạt của nó, Redis thường được sử dụng để giải quyết những thách thức như vậy. Khả năng lưu trữ, thao tác và phân phát nhiều dạng dữ liệu với độ trễ dưới mili giây khiến nó trở thành vùng chứa dữ liệu lý tưởng trong nhiều trường hợp cần tính toán trực tuyến.
Nhưng mọi thứ đều là tương đối và có những quy mô cực đoan đến mức chúng khiến việc phân tích thời gian thực chính xác trở thành điều không thể thực hiện được. Các vấn đề phức tạp chỉ trở nên khó hơn khi chúng lớn hơn, nhưng chúng ta có xu hướng quên rằng các vấn đề đơn giản cũng tuân theo quy luật tương tự. Ngay cả những thứ cơ bản như tính tổng các số cũng có thể trở thành một nhiệm vụ lớn khi dữ liệu quá lớn, quá nhanh hoặc khi chúng ta không có đủ tài nguyên để xử lý. Và trong khi tài nguyên luôn hữu hạn và đắt đỏ, dữ liệu không ngừng phát triển như việc của riêng ai.
Bản phác thảo đếm phút là gì?
Bản phác thảo đếm phút (còn gọi là bản phác thảo CM) là một cấu trúc dữ liệu xác suất cực kỳ hữu ích khi bạn nắm được cách hoạt động của nó và quan trọng hơn là cách sử dụng nó.
May mắn thay, các đặc điểm đơn giản của CM sketch khiến những người mới làm quen tương đối dễ hiểu (hóa ra nhiều người bạn của tôi không thể theo dõi blog Top-K này).
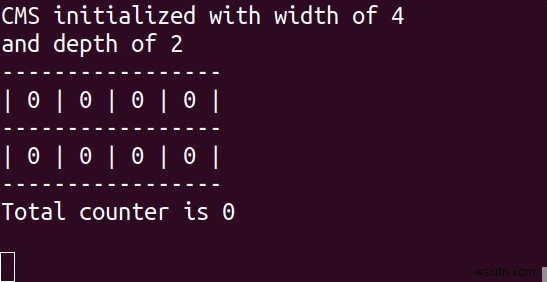
Bản phác thảo CM đã là một mô-đun Redis trong vài năm và gần đây đã được viết lại như một phần của mô-đun RedisBloom v2.0. Nhưng trước khi chúng ta đi sâu vào bản phác thảo CM, điều quan trọng là phải hiểu lý do tại sao bạn sử dụng any cấu trúc dữ liệu xác suất. Trong tam giác tốc độ, không gian và độ chính xác, cấu trúc dữ liệu xác suất hy sinh một số độ chính xác để đạt được không gian — có khả năng rất nhiều không gian ! Ảnh hưởng đến tốc độ thay đổi tùy theo thuật toán và kích thước đặt.
- Độ chính xác :Theo định nghĩa, chỉ giữ một phần dữ liệu của bạn và để xảy ra va chạm trong bộ nhớ sẽ làm giảm độ chính xác. Tuy nhiên, bạn có thể đặt tỷ lệ lỗi tối đa dựa trên trường hợp sử dụng của mình.
- Dung lượng bộ nhớ :Trong thế giới dữ liệu lớn, nơi hàng tỷ sự kiện được ghi lại, chỉ lưu trữ một phần dữ liệu có thể giúp giảm đáng kể chi phí và yêu cầu về dung lượng lưu trữ.
- Tốc độ :Một số cấu trúc dữ liệu truyền thống hoạt động tương đối kém hiệu quả, làm chậm thời gian phản hồi. (Ví dụ:Tập hợp được sắp xếp duy trì thứ tự của tất cả các phần tử trong đó, nhưng bạn có thể chỉ quan tâm đến các phần tử hàng đầu. Vì các thuật toán xác suất chỉ duy trì một phần danh sách, chúng hiệu quả hơn và thường có thể trả lời các truy vấn nhanh hơn nhiều.
Cấu trúc dữ liệu xác suất phù hợp cho phép bạn chỉ giữ một phần thông tin trong tập dữ liệu của mình để đổi lấy độ chính xác giảm. Tất nhiên, trong nhiều trường hợp (tài khoản ngân hàng chẳng hạn), độ chính xác giảm là không thể chấp nhận được. Nhưng để giới thiệu một bộ phim hoặc hiển thị quảng cáo cho người dùng trang web, chi phí cho một sai sót tương đối hiếm gặp là thấp và tiết kiệm không gian có thể đáng kể.
Về cơ bản, CM sketch hoạt động bằng cách tổng hợp số lượng tất cả các mục trong tập dữ liệu của bạn thành một số mảng bộ đếm. Theo một truy vấn, nó trả về số lượng tối thiểu của tất cả các mảng, hứa hẹn sẽ giảm thiểu lạm phát số lượng do va chạm gây ra. Các mục có tỷ lệ xuất hiện hoặc điểm thấp (“luồng chuột”) có số lượng thấp hơn tỷ lệ lỗi , vì vậy bạn sẽ mất bất kỳ dữ liệu nào về số lượng thực của chúng và chúng được coi là nhiễu. Đối với các mục có tỷ lệ xuất hiện hoặc điểm số cao (“dòng chảy của voi”), chỉ cần sử dụng số lượng nhận được. Xem xét kích thước của CM sketch là không đổi và nó có thể được sử dụng cho vô số mục, bạn có thể thấy tiềm năng tiết kiệm rất lớn không gian lưu trữ.
Đối với nền, bản phác thảo là một lớp cấu trúc dữ liệu và các thuật toán đi kèm của chúng. Họ nắm bắt bản chất của dữ liệu của bạn để trả lời các câu hỏi về nó trong khi sử dụng không gian không đổi hoặc không gian tuyến tính dưới. Bản phác thảo CM được Graham Cormode và S. Muthu Muthukrishnan mô tả trong một bài báo năm 2005 có tên là “ Tóm tắt luồng dữ liệu được cải thiện:Bản phác thảo đếm tối thiểu và các ứng dụng của nó . ”
Bản phác thảo đếm phút:Cái gì và như thế nào
CM sketch sử dụng một số mảng bộ đếm để hỗ trợ các trường hợp sử dụng chính của nó. Hãy gọi số mảng là “độ sâu” và số lượng bộ đếm trong mỗi mảng là “độ rộng”.
Bất cứ khi nào chúng tôi nhận được một mục, chúng tôi sử dụng hàm băm (biến một phần tử — một từ, câu, số hoặc nhị phân — thành một số có thể được sử dụng làm vị trí trong tập hợp / mảng hoặc dưới dạng tệp tham chiếu) để tính toán vị trí của mục và tăng bộ đếm đó cho mỗi mảng. Mỗi bộ đếm được liên kết có giá trị bằng hoặc cao hơn giá trị thực của mặt hàng. Khi chúng tôi thực hiện một yêu cầu, chúng tôi đi qua tất cả các mảng có cùng hàm băm và tìm nạp bộ đếm được liên kết với mục của chúng tôi. Sau đó, chúng tôi trả về giá trị tối thiểu mà chúng tôi gặp phải vì chúng tôi biết giá trị của chúng tôi bị tăng cao (hoặc bằng).
Mặc dù chúng tôi biết rằng nhiều mặt hàng góp phần vào hầu hết các quầy, do va chạm tự nhiên (khi các mặt hàng khác nhau nhận cùng một vị trí), chúng tôi chấp nhận 'tiếng ồn' miễn là nó vẫn nằm trong tỷ lệ lỗi mong muốn của chúng tôi.
Ví dụ về bản phác thảo đếm phút
Phép toán cho rằng với chiều sâu 10 và chiều rộng 2.000, xác suất không có lỗi là 99,9% và tỷ lệ lỗi là 0,1%. (Đây là phần trăm của tổng số gia tăng, không phải của các mục duy nhất).
Theo số thực, điều đó có nghĩa là nếu bạn thêm 1 triệu mục duy nhất, trung bình mỗi mục sẽ nhận được giá trị 500 (1M / 2K). Mặc dù điều đó có vẻ không cân xứng, nhưng tỷ lệ này nằm trong tỷ lệ sai sót của chúng tôi là 0,1%, là 1.000 trên 1 triệu mục.
Tương tự, nếu 10 con voi xuất hiện 10.000 lần mỗi con, giá trị của chúng trên tất cả các bộ sẽ là 10.000 hoặc hơn. Bất cứ khi nào chúng ta đếm chúng trong tương lai, chúng ta sẽ thấy một con voi trước mặt. Đối với tất cả các số khác (tức là tất cả các con chuột có số lượng thực là 1), chúng không có khả năng va chạm với một con voi trên tất cả các tập hợp (vì bản phác thảo CM chỉ coi là số lượng tối thiểu) vì xác suất xảy ra điều này rất nhỏ và giảm thêm nếu bạn tăng độ sâu khi bạn khởi tạo bản phác thảo CM.
Count-min Sketch tốt cho điều gì?
Bây giờ chúng ta đã hiểu về hoạt động của CM sketch, chúng ta có thể làm gì với con thú nhỏ này? Dưới đây là một số trường hợp sử dụng phổ biến:
- Truy vấn hai số và so sánh số lượng của chúng.
- Đặt tỷ lệ phần trăm các mục đến, giả sử 1%. Bất cứ khi nào số lượng tối thiểu của một mặt hàng cao hơn 1% tổng số, chúng tôi trả về true. Ví dụ:giá trị này có thể được sử dụng để xác định người chơi hàng đầu của một trò chơi trực tuyến.
- Thêm min-heap vào bản phác thảo CM và tạo cấu trúc dữ liệu Top-K. Bất cứ khi nào chúng tôi tăng một mục, chúng tôi sẽ kiểm tra xem số lượng tối thiểu mới có cao hơn mức tối thiểu trong đống và cập nhật nó cho phù hợp hay không. Không giống như mô-đun Top-K trong RedisBloom, bị phân hủy dần theo thời gian, CM sketch không bao giờ quên và do đó hành vi của nó hơi khác so với HeavyKeeper dựa trên Top-K.
Trong RedisBloom, bản phác thảo API cho CM rất đơn giản và dễ dàng:
- Để khởi tạo cấu trúc dữ liệu phác thảo CM: INITBYDIM { key } { chiều rộng } { độ sâu } hoặc CMS.INITBYPROB { key } { lỗi } { xác suất }
- Để tăng số đếm của một mặt hàng: CMS.INCRBY { key } { mục } { gia số }
- Để có được số lượng tối thiểu được tìm thấy trong bộ đếm của mặt hàng: CMS.QUERY { key } { mục }
Các lệnh sau được sử dụng để tạo ví dụ động ở đầu bài đăng này:
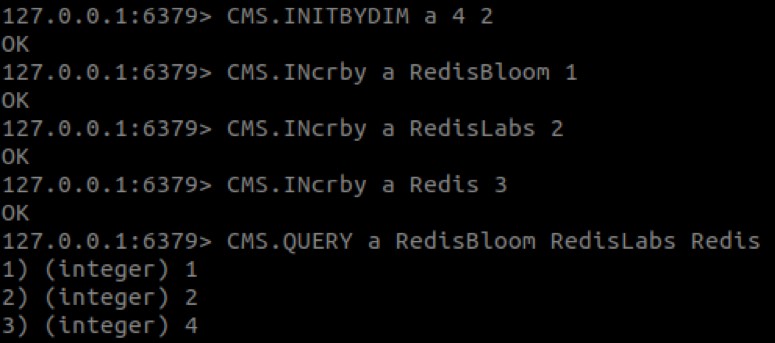
Như bạn có thể thấy, giá trị của ‘Redis’ là 4 thay vì 3. Hành vi này được mong đợi vì, trong CM sketch, số lượng một mục có thể bị tăng cao.
Công việc kinh doanh sơ sài
Kỹ thuật phần mềm là tất cả về việc đánh đổi và một cách tiếp cận phổ biến để giải quyết những thách thức như vậy một cách hiệu quả về chi phí là bỏ độ chính xác để ưu tiên hiệu quả. Cách tiếp cận này được minh chứng bằng cách triển khai HyperLogLog của Redis, một cấu trúc dữ liệu được thiết kế để cung cấp câu trả lời một cách hiệu quả cho các truy vấn về bản số đã đặt. HyperLogLog là một thành viên của nhóm cấu trúc dữ liệu được gọi là "bản phác thảo", giống như các đối tác nghệ thuật trong thế giới thực, truyền tải thông tin thông qua số liệu gần đúng về chủ thể của chúng.
Nói một cách khái quát, bản phác thảo là cấu trúc dữ liệu (và các thuật toán đi kèm của chúng) nắm bắt bản chất dữ liệu của bạn — câu trả lời cho câu hỏi của bạn về dữ liệu mà không thực sự lưu trữ dữ liệu. Được công bố chính thức, các bản phác thảo rất hữu ích vì chúng có độ phức tạp tính toán tiệm cận tuyến tính, do đó yêu cầu ít năng lực tính toán và / hoặc bộ nhớ hơn. Nhưng không có bữa trưa nào miễn phí và hiệu quả thu được được bù đắp bởi độ chính xác của các câu trả lời. Tuy nhiên, trong nhiều trường hợp, lỗi có thể chấp nhận được miễn là chúng có thể được giữ dưới một ngưỡng. Một bản phác thảo dữ liệu tốt là một bản phác thảo dữ liệu dễ dàng thừa nhận lỗi của nó và trên thực tế, nhiều bản phác thảo tham số hóa các lỗi của chúng (hoặc xác suất của các lỗi đã nói) để người dùng có thể xác định chúng.
Bản phác thảo tốt là hiệu quả và có xác suất sai nhất định, nhưng bản phác thảo xuất sắc là những bản phác thảo có thể được tính toán song song. Bản phác thảo có thể song song hóa là bản phác thảo có thể được chuẩn bị độc lập trên các phần của dữ liệu và cho phép kết hợp các phần của nó thành một tổng hợp có ý nghĩa và nhất quán. Bởi vì mỗi phần của một bản phác thảo xuất sắc có thể được tính toán ở một vị trí và / hoặc thời gian khác nhau, tính song song giúp bạn có thể áp dụng một cách tiếp cận chia để trị đơn giản để giải quyết các thách thức về quy mô.
Một sự cố thường xuyên
HyperLogLog nói trên là một bản phác thảo tuyệt vời nhưng nó chỉ phù hợp để trả lời một loại câu hỏi cụ thể. Một công cụ vô giá khác là Bản phác thảo đếm tối thiểu (CMS), như được mô tả trong bài báo “Tóm tắt luồng dữ liệu được cải thiện:Bản phác thảo đếm phút và các ứng dụng của nó” của G. Cormode và S. Muthukrishnan. Sự kết hợp khéo léo này được tạo ra để cung cấp câu trả lời về tần suất của các mẫu, một khối xây dựng phổ biến trong một tỷ lệ lớn các quy trình phân tích.
Với đủ thời gian và nguồn lực, việc tính toán tần suất của mẫu là một quá trình đơn giản - chỉ cần giữ lại số lượng quan sát (số lần nhìn thấy) cho mỗi mẫu (điều được nhìn thấy) và sau đó chia nó cho tổng số lần quan sát để có được tần suất của mẫu đó. Tuy nhiên, trong bối cảnh xử lý dữ liệu độ trễ thấp quy mô lớn, không bao giờ có đủ thời gian hoặc tài nguyên. Các câu trả lời phải được cung cấp ngay lập tức khi dữ liệu truyền vào, bất kể quy mô của nó như thế nào và kích thước tuyệt đối của không gian lấy mẫu khiến việc giữ bộ đếm cho từng mẫu là không khả thi.
Vì vậy, thay vì theo dõi chính xác từng mẫu, chúng ta có thể thử ước tính tần suất. Một cách để thực hiện điều đó là lấy mẫu ngẫu nhiên các quan sát và hy vọng rằng mẫu đó phản ánh các đặc tính của tổng thể. Vấn đề với cách tiếp cận này là việc đảm bảo tính ngẫu nhiên thực sự là một nhiệm vụ khó khăn, do đó, sự thành công của việc lấy mẫu ngẫu nhiên có thể bị giới hạn bởi quy trình lựa chọn của chúng tôi và / hoặc các thuộc tính của chính dữ liệu. Đó là lúc CMS xuất hiện với một cách tiếp cận hoàn toàn khác, thoạt đầu, nó có vẻ như ngược lại với một bản phác thảo xuất sắc:CMS không chỉ ghi lại từng quan sát, mà mỗi quan sát được ghi lại trong nhiều bộ đếm!
Tất nhiên, có một sự thay đổi, và nó rất thông minh vì nó rất đơn giản. Bài báo gốc (và phiên bản nhẹ hơn của nó có tên là “Dữ liệu gần đúng với cấu trúc dữ liệu đếm tối thiểu”) thực hiện rất tốt việc giải thích nó, nhưng dù sao thì tôi cũng sẽ cố gắng tóm tắt lại. Sự thông minh của CMS nằm ở cách nó lưu trữ các mẫu:thay vì theo dõi từng mẫu duy nhất một cách độc lập, nó sử dụng giá trị băm của nó. Giá trị băm của một mẫu được sử dụng làm chỉ số cho một mảng bộ đếm có kích thước không đổi (được tham số hóa là d trong bài báo). Bằng cách sử dụng một số (tham số w) các hàm băm khác nhau và các mảng tương ứng của chúng, bản phác thảo xử lý các xung đột băm được tìm thấy trong khi truy vấn cấu trúc bằng cách chọn giá trị nhỏ nhất trong số tất cả các bộ đếm có liên quan cho mẫu.
Một ví dụ được yêu cầu, vì vậy hãy tạo một bản phác thảo đơn giản để minh họa hoạt động bên trong của cấu trúc dữ liệu. Để giữ cho bản phác thảo đơn giản, chúng tôi sẽ sử dụng các giá trị tham số nhỏ. Chúng tôi sẽ đặt w thành 3, có nghĩa là chúng tôi sẽ sử dụng ba hàm băm - được ký hiệu lần lượt là h1, h2 và h3 và d là 4. Để lưu trữ các bộ đếm của sketch, chúng tôi sẽ sử dụng một mảng 3 × 4 với tổng số 12 các phần tử được khởi tạo thành 0.
Bây giờ chúng ta có thể kiểm tra những gì sẽ xảy ra khi các mẫu được thêm vào bản phác thảo. Giả sử các mẫu đến từng mẫu một và các băm cho mẫu đầu tiên, được ký hiệu là s1, là:h1 (s1) =1, h2 (s1) =2 và h3 (s1) =3. Để ghi lại s1 trong bản phác thảo, chúng ta Sẽ tăng bộ đếm của mỗi hàm băm tại chỉ mục liên quan lên 1. Bảng sau đây cho thấy trạng thái ban đầu và trạng thái hiện tại của mảng:

Mặc dù chỉ có một mẫu trong bản phác thảo, chúng tôi đã có thể truy vấn nó một cách hiệu quả. Hãy nhớ rằng số lượng quan sát cho một mẫu là số lượng tối thiểu trong tất cả các bộ đếm của nó, vì vậy đối với s1, số lượng quan sát được bằng:
min(array[1][h1(s1)], array[2][h2(s1)], array[3][h3(s1)]) = Bản phác thảo cũng trả lời các câu hỏi về các mẫu chưa được thêm vào. Giả sử rằng h 1 (s 2 ) =4, h 2 (s 2 ) =4, h 3 (s 2 ) =4, lưu ý rằng truy vấn cho s 2 sẽ trả về kết quả 0. Hãy tiếp tục thêm s 2 và s 3 (h 1 (s 3 ) =1, h 2 (s 3 ) =1, h 3 (s 3 ) =1) vào bản phác thảo, tạo ra như sau:
min(array[1][1], array[2][2], array[3][3]) =
min(1,1,1) = 1

Trong ví dụ có sẵn của chúng tôi, hầu hết tất cả các hàm băm của mẫu đều ánh xạ tới các bộ đếm duy nhất, với một ngoại lệ là sự va chạm của h1 (s1) và h1 (s3). Bởi vì cả hai hàm băm đều giống nhau, bộ đếm thứ nhất của h1 hiện giữ giá trị 2. Vì bản phác thảo chọn giá trị tối thiểu của tất cả các bộ đếm, các truy vấn cho s1 và s3 vẫn trả về kết quả đúng là 1. Tuy nhiên, cuối cùng, khi có đủ va chạm xảy ra, kết quả của các truy vấn sẽ trở nên kém chính xác hơn.
CMS ’hai tham số - w và d - xác định các yêu cầu về không gian / thời gian cũng như xác suất và giá trị lớn nhất của sai số. Một cách trực quan hơn để khởi tạo bản phác thảo là cung cấp xác suất và giới hạn của lỗi, cho phép nó sau đó lấy ra các giá trị cần thiết cho w và d. Có thể thực hiện song song vì bất kỳ số lượng bản phác thảo con nào cũng có thể được hợp nhất thành tổng các mảng, miễn là các tham số và hàm băm giống nhau được sử dụng để xây dựng chúng.
Một vài nhận xét về bản phác thảo Đếm phút
Tính hiệu quả của Count Min Sketch có thể được chứng minh bằng cách xem xét các yêu cầu của nó. Độ phức tạp về không gian của CMS là tích của w, d và chiều rộng của các bộ đếm mà nó sử dụng. Ví dụ:một bản phác thảo có tỷ lệ lỗi 0,01% với xác suất 0,01% được tạo bằng cách sử dụng 10 hàm băm và mảng 2000 bộ đếm. Giả sử sử dụng bộ đếm 16 bit, yêu cầu bộ nhớ tổng thể của cấu trúc dữ liệu của bản phác thảo kết quả đạt mức 40KB (cần thêm một vài byte để lưu trữ tổng số quan sát và một vài con trỏ). Khía cạnh tính toán khác của sketch cũng dễ chịu tương tự — vì các hàm băm rẻ để sản xuất và tính toán, việc truy cập cấu trúc dữ liệu, cho dù để đọc hay ghi, cũng được thực hiện trong thời gian không đổi.
Còn nhiều hơn thế nữa đối với CMS; các tác giả của bản phác thảo cũng đã chỉ ra cách nó có thể được sử dụng để trả lời các câu hỏi tương tự khác. Chúng bao gồm ước tính tỷ lệ phần trăm và xác định các điểm cao (mục thường xuyên) nhưng nằm ngoài phạm vi của bài đăng này.
CMS chắc chắn là một bản phác thảo xuất sắc, nhưng có ít nhất hai điều ngăn cản nó đạt được sự hoàn hảo. Bảo lưu đầu tiên của tôi về CMS là nó có thể bị sai lệch, và do đó đánh giá quá cao tần số của các mẫu với một số lượng quan sát nhỏ. Sự thiên vị của CMS đã được biết đến nhiều và một số cải tiến đã được đề xuất. Gần đây nhất là Bản phác thảo nhật ký đếm tối thiểu (“Đếm gần đúng với bộ đếm gần đúng” của G. Pitel và G. Fouquier), về cơ bản thay thế các thanh ghi tuyến tính của CMS bằng các thanh ghi logarit để giảm sai số tương đối và cho phép số đếm cao hơn mà không tăng chiều rộng đăng ký bộ đếm.
Mặc dù đặt chỗ ở trên được chia sẻ bởi tất cả mọi người (mặc dù chỉ những người tìm kiếm cấu trúc dữ liệu), đặt chỗ thứ hai của tôi là dành riêng cho cộng đồng Redis. Để giải thích, tôi sẽ phải giới thiệu Mô-đun Redis.
Một mô-đun Redis
Mô-đun Redis đã được antirez công bố vào đầu năm nay tại RedisConf và đã thực sự làm đảo lộn thế giới của chúng ta. Không hơn không kém so với các thư viện động có thể tải của máy chủ, Mô-đun cho phép người dùng Redis di chuyển nhanh hơn chính Redis và đi những nơi chưa từng mơ tới trước đây. Và mặc dù bài đăng này không phải là phần giới thiệu về Mô-đun là gì hoặc cách tạo ra chúng, nhưng bài đăng này là (cũng như bài đăng này và hội thảo trên web này).
Có một số lý do tôi muốn viết mô-đun Count Min Sketch Redis, ngoài tính hữu dụng cực kỳ của nó. Một phần là trải nghiệm học tập và một phần là đánh giá API mô-đun, nhưng chủ yếu là tạo mô hình cấu trúc dữ liệu mới vào Redis rất thú vị. Mô-đun cung cấp giao diện Redis để thêm các quan sát vào bản phác thảo, truy vấn nó và hợp nhất nhiều bản phác thảo thành một.
Mô-đun lưu trữ dữ liệu của bản phác thảo trong Chuỗi Redis và sử dụng quyền truy cập bộ nhớ trực tiếp (DMA) để ánh xạ nội dung của khóa với cấu trúc dữ liệu bên trong của nó. Tôi vẫn chưa tiến hành đánh giá hiệu suất toàn diện trên nó, nhưng ấn tượng ban đầu của tôi khi kiểm tra nó cục bộ là nó hoạt động hiệu quả như bất kỳ lệnh Redis cốt lõi nào. Giống như các mô-đun khác của chúng tôi, countminsketch là mã nguồn mở và tôi khuyến khích bạn dùng thử và sử dụng nó.
Trước khi đăng ký, tôi muốn giữ lời hứa của mình và chia sẻ thông tin đặt trước dành riêng cho Redis của tôi về CMS. Vấn đề, cũng áp dụng cho các bản phác thảo và cấu trúc dữ liệu khác, là CMS yêu cầu bạn thiết lập / khởi tạo / tạo nó trước khi sử dụng. Yêu cầu giai đoạn khởi tạo bắt buộc, chẳng hạn như thiết lập tham số CMS, phá vỡ một trong các mẫu cơ bản của Redis — cấu trúc dữ liệu không cần phải được khai báo rõ ràng trước khi sử dụng vì chúng có thể được tạo theo yêu cầu. Để làm cho mô-đun có vẻ Redis-ish hơn và hoạt động xung quanh việc chống lại mẫu đó, mô-đun sử dụng các giá trị tham số mặc định khi một bản phác thảo mới được ngụ ý một cách ngầm (tức là sử dụng lệnh CMS.ADD trên một khóa không tồn tại) nhưng cũng cho phép tạo mới bản phác thảo trống với các thông số đã cho.
Cấu trúc dữ liệu xác suất, hoặc bản phác thảo, là những công cụ tuyệt vời cho phép chúng ta theo kịp tốc độ phát triển của dữ liệu lớn và thu hẹp ngân sách độ trễ một cách hiệu quả và đủ chính xác. Hai bản phác thảo được đề cập trong bài đăng này và các bản phác thảo khác như Bộ lọc Bloom và Bộ lọc chữ T, đang nhanh chóng trở thành công cụ không thể thiếu trong kho vũ khí của người monger dữ liệu hiện đại. Các mô-đun cho phép bạn mở rộng Redis với các loại dữ liệu tùy chỉnh và các lệnh hoạt động ở tốc độ gốc và có quyền truy cập cục bộ vào dữ liệu. Khả năng là vô tận và không có gì là không thể.
Bạn muốn tìm hiểu thêm về các mô-đun Redis và cách phát triển chúng? Có cấu trúc dữ liệu nào, cho dù có xác suất hay không, mà bạn muốn thảo luận hoặc thêm vào Redis? Vui lòng liên hệ với tôi bằng bất cứ thứ gì tại tài khoản Twitter của tôi hoặc qua email - tôi rất sẵn lòng 🙂