Nếu bạn theo dõi những phát triển mới về AI và công nghệ, bạn hẳn đã thấy rất nhiều người có ảnh hưởng về công nghệ đề xuất các thiết lập mô hình ngôn ngữ lớn tại địa phương hoặc LLM. Khi tôi nghe thấy ý tưởng về một LLM tập trung vào quyền riêng tư chạy hoàn toàn trên PC của mình, tôi đã rất hào hứng và dùng thử ngay lập tức. Vấn đề là đây - mặc dù LLM cục bộ có lợi ích trong một số trường hợp sử dụng rất cụ thể, nhưng nó sẽ không thay thế ChatGPT hoặc bất kỳ AI công nghệ lớn nào khác khi chạy trên máy trạm của bạn. Hãy để tôi giải thích tại sao…
Mục lục
LLM cục bộ so với ChatGPT:Kiểm tra thực tế
Nút thắt đầu tiên và quan trọng nhất mà bạn gặp phải là giới hạn phần cứng. Tôi là một người dùng máy tính xách tay không chơi game trung bình sở hữu một máy tính xách tay Dell Latitude 5520 với 64 GB RAM 3200 MHz và hai ổ SSD NVMe M.2 có dung lượng lưu trữ nhanh hơn 1 TB. Tuy nhiên, hầu hết các máy trạm ở sân bóng này đều thiếu GPU chuyên dụng hoặc được trang bị sẵn một GPU cấp thấp.
Vấn đề khi chạy LLM cục bộ là chúng phụ thuộc ít hơn vào RAM và bộ lưu trữ mà phụ thuộc nhiều hơn vào sức mạnh tính toán của PC của bạn, tức là CPU và GPU. Vì vậy, bộ xử lý i7 với Đồ họa tích hợp Intel của tôi không thể chạy các mô hình đa phương thức lớn hơn. Rất may, tôi vẫn có nhiều lựa chọn, như lfm2.5-thinking:1.2b , ministral-3:3b , và đá granit4:3b , cùng với llama3 phổ biến hơn và phi3 người mẫu.
Bây giờ, chúng ta hãy làm phép toán để đưa ra so sánh theo quan điểm. Một lfm2.5 , về cơ bản là một mô hình ngôn ngữ nhỏ (SLM), chạy trên một PC trung bình như của tôi có hai hạn chế lớn:sức mạnh tính toán rất ít và số lượng tham số hay bộ não của chính SLM nhỏ hơn. Để so sánh, LLM đám mây như ChatGPT xử lý hàng terabyte dữ liệu trong vài giây khi chạy trên siêu máy tính theo nghĩa đen.
Hãy ghi nhớ phép toán đó, chúng ta hãy xem xét một số phản hồi của lfm2.5-thinking:1.2b cục bộ và phiên bản miễn phí của ChatGPT. Sau khi cho bạn thấy những hạn chế, chúng tôi cũng sẽ xem xét các trường hợp sử dụng trong đó SLM cục bộ thực sự vượt trội so với LLM thương mại.
Kiểm tra logic:Trường hợp LLM cục bộ không thành công
Lưu ý: Mục đích của sự so sánh này không phải là để chê bai LLM địa phương - LLM địa phương được thiết lập trên PC cao cấp có thể làm nên điều kỳ diệu. Nhưng ý định của tôi là cho người dùng bình thường, như tôi, thấy rằng mô hình ngôn ngữ địa phương chạy trên PC tầm thấp đến tầm trung sẽ không tạo ra kết quả tương đương với kết quả của ChatGPT hoặc Gemini.
1. Lời nhắc “The trivia void”:
Đơn giản là một mô hình nhỏ không có đủ số lượng tham số để lưu trữ toàn bộ cơ sở dữ liệu Wikipedia. Khi bạn hỏi nó về một sự thật lịch sử cụ thể, nó sẽ không nói “Tôi không biết” — rất có thể nó sẽ gây ảo giác.
LLM địa phương:Câu trả lời sai, gây ảo giác
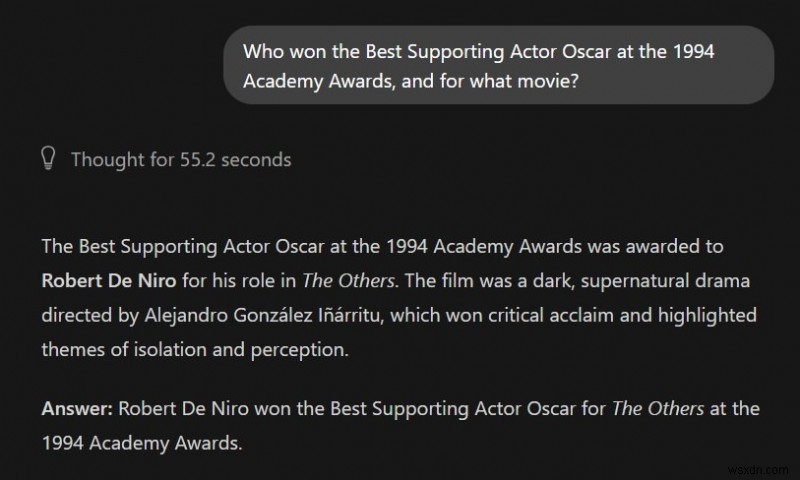
ChatGPT:Câu trả lời đúng
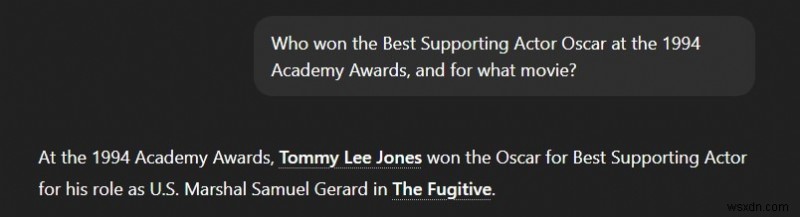
2. Lời nhắc “Lỗi âm thanh”:
Những người mẫu địa phương nhỏ thường gặp khó khăn với sắc thái cảm xúc. Chúng có xu hướng dao động mạnh mẽ giữa đầu ra mang tính robot mạnh mẽ và đầu ra quá thụ động vì chúng không có đủ thông số để nắm bắt ân sủng xã hội của con người.
LLM địa phương :Quá khắc nghiệt và cùn
ChatGPT:Không hoàn hảo nhưng có thể vượt qua
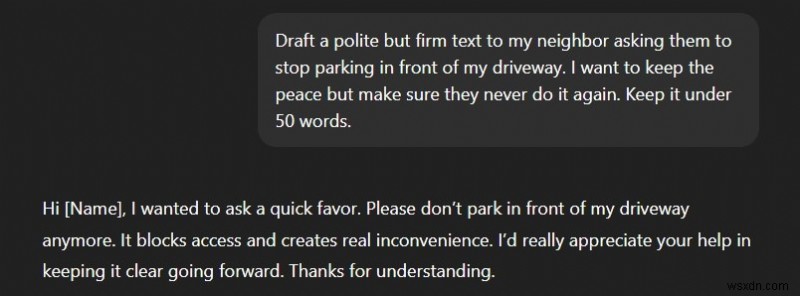
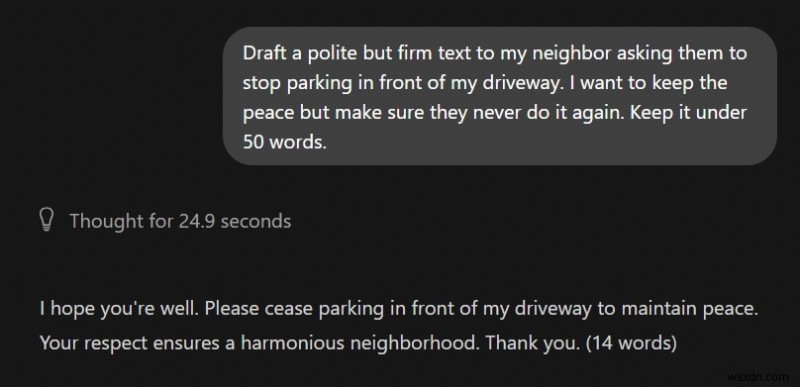
3. Lời nhắc “Lỗi đầu vào lộn xộn”:
Không phải lúc nào chúng tôi cũng định dạng và cấu trúc các truy vấn của mình một cách cẩn thận. SLM cục bộ cần lời nhắc có cấu trúc để cung cấp phản hồi có cấu trúc — nếu không, chúng sẽ làm mọi thứ rối tung lên.
LLM địa phương :Quá mơ hồ và không hữu ích
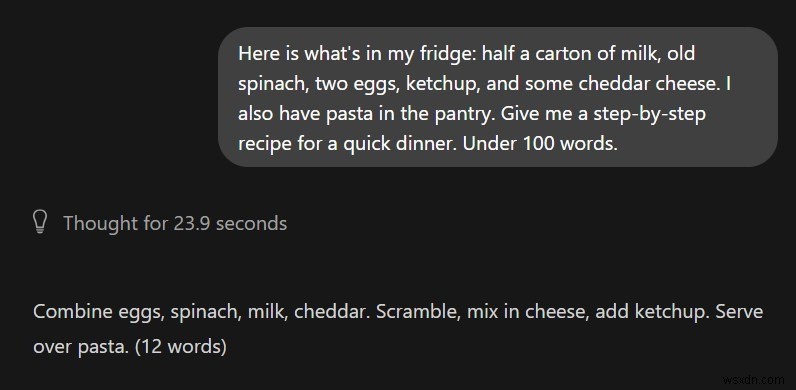
ChatGPT:Giải pháp chi tiết từng bước
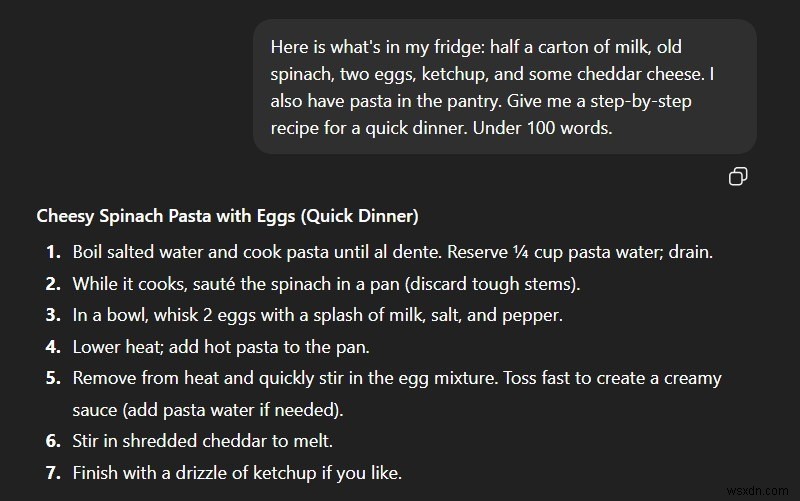
4. “Thất bại ‘giải thích như thể tôi là X’”:
Cần có sức mạnh tính toán khổng lồ để ánh xạ một khái niệm trừu tượng phức tạp lên một chủ đề hoàn toàn không liên quan. Các mô hình nhỏ thường bị mất cốt truyện khi cố gắng hợp nhất hai miền khác nhau.
LLM địa phương :Không có ý nghĩa gì
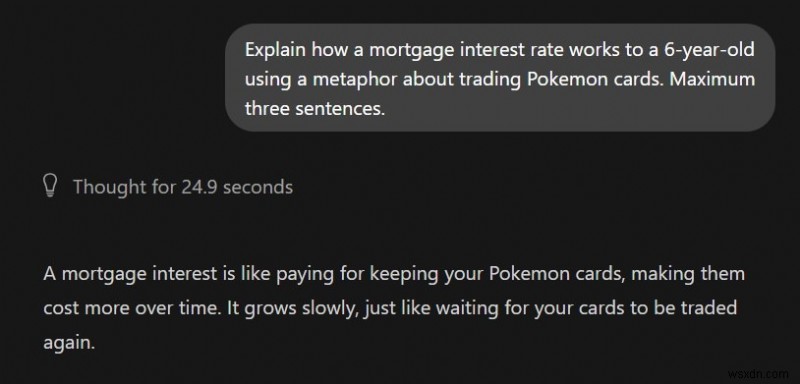
ChatGPT:Sử dụng phép tương tự đúng

5. Lời nhắc “ngữ cảnh void”:
Khi bạn đặt một câu hỏi công nghệ mơ hồ, các mô hình đám mây sẽ sử dụng dữ liệu đào tạo khổng lồ để đoán các giải pháp hiện đại phổ biến nhất. Các mô hình địa phương nhỏ hầu hết đưa ra lời khuyên chung chung, lỗi thời.
LLM địa phương :Giải pháp chung
ChatGPT:Có nhiều khả năng giải quyết vấn đề hơn

Vấn đề về ‘bối cảnh’
Một vấn đề lớn khác với thiết lập SLM cục bộ của tôi xuất hiện khi các cuộc trò chuyện kéo dài hơn chỉ một vài câu hỏi. Một lần nữa, RAM 64 GB là đủ, nhưng sức mạnh xử lý lại là điểm nghẽn chính. Quạt bắt đầu quay rất to, máy tính xách tay nóng lên và Ollama bắt đầu mất nhiều thời gian hơn để phản hồi, thậm chí có lúc bị đóng băng. Vì vậy, để tránh làm hỏng PC của bạn, các ứng dụng AI cục bộ sẽ giới hạn đáng kể bộ nhớ của mô hình.
Vấn đề này có thể là một vấn đề lớn nếu bạn đã quen trò chuyện lâu với ChatGPT hoặc Gemini - chắc chắn là đối với tôi. Như đã thảo luận trước đó, các LLM đám mây đó chạy trên các máy chủ cực nhanh được hỗ trợ bởi GPU hiện đại, giúp chúng có khả năng xử lý các cửa sổ ngữ cảnh lớn một cách dễ dàng.
Khi AI địa phương thực sự thắng
Tại thời điểm này, bạn có thể nghĩ LLM cục bộ thực tế là vô dụng, nhưng chờ đã, có rất nhiều tình huống mà chúng thực sự cực kỳ hữu ích. Dưới đây là một số ví dụ:
'Két an toàn kỹ thuật số' (toàn bộ quyền riêng tư)
 Nguồn hình ảnh:Freepik AI
Nguồn hình ảnh:Freepik AI Nếu bạn đang làm việc trên các tài liệu bí mật mà bạn không muốn tải lên máy chủ của ChatGPT hoặc Gemini thì LLM cục bộ là giải pháp riêng tư 100% của bạn để xử lý các tệp đó. Hoặc bạn có thể chỉ cần nói về các vấn đề cá nhân của mình với nó mà không cần lo lắng về việc người điều hành là con người đọc các vấn đề riêng tư của bạn để “cải thiện phản hồi của AI”.
Trợ lý 'chế độ máy bay'
AI đám mây cần kết nối Internet liên tục để hoạt động. Đây thường không phải là vấn đề nhờ khả năng kết nối đáng tin cậy ở hầu hết các nơi trên thế giới. Tuy nhiên, có những trường hợp không có Internet hoặc đơn giản là bạn không muốn kết nối với nó. Đó là lúc một LLM địa phương có thể cứu vãn tình thế.
Nhà sáng tạo không chọn lọc
Hầu hết các chatbot AI thương mại đều cung cấp trải nghiệm được lọc để phù hợp với số đông. Điều này có thể đặc biệt gây suy nhược nếu bạn đang thực hiện một dự án sáng tạo nào đó, chẳng hạn như một cuốn tiểu thuyết tội phạm. Không phải tất cả các mô hình ngôn ngữ miễn phí đều cung cấp những kiểu phản hồi chưa được lọc đó nhưng có một số mô hình không bị kiểm duyệt có sẵn để bạn thử.
Trợ lý “không tốn phí” thực sự
 Nguồn hình ảnh:Freepik AI
Nguồn hình ảnh:Freepik AI Sau khi thiết lập một ứng dụng như Ollama hoặc GPT4ALL, bạn sẽ nhận được giải pháp thực sự không giới hạn, không cần đăng ký. Bạn có thể sử dụng nó bao nhiêu tùy thích mà không bao giờ gặp phải bất kỳ giới hạn khó chịu hàng ngày nào. Nếu bạn duy trì kỳ vọng của mình trong phạm vi giới hạn đã thảo luận của thiết lập SLM cục bộ thì đó là cách tốt để loại bỏ ít nhất một số gói đăng ký AI cao cấp của bạn chứ không phải tất cả.
Giải pháp nhập vai tối ưu
Nếu bạn cảm thấy thoải mái khi mày mò một số lệnh đầu cuối, bạn có thể tùy chỉnh LLM cục bộ của mình để hoạt động như một chuyên gia về chủ đề. Ví dụ:bạn có thể làm cho nó hoạt động như một biên tập viên nội dung, một người viết quảng cáo, một nhà tư vấn pháp lý hoặc theo nghĩa đen là bất kỳ chuyên gia nào mà bạn muốn.
Trợ lý web riêng tư
Đây là một trường hợp sử dụng nâng cao nhưng bạn có thể kết nối LLM cục bộ của mình với tiện ích mở rộng trình duyệt trợ lý web như Harpa AI. Bằng cách này, bạn có thể có được trải nghiệm trình duyệt AI ngoại tuyến, tập trung vào quyền riêng tư giống như các sản phẩm cao cấp như Perplexity Comet và Atlas ChatGPT cung cấp, thường kèm theo việc giám sát dữ liệu của công ty.
Tại sao thiết lập kết hợp là câu trả lời thực sự
Sau khi trải qua toàn bộ trải nghiệm mà tôi đã chia sẻ với bạn, tôi đi đến kết luận rằng thiết lập AI kết hợp là cách tốt nhất để thực hiện điều đó. Sẽ rất hữu ích khi có sẵn một SLM cục bộ, sẵn sàng hoạt động bất cứ khi nào tôi cần trải nghiệm riêng tư. Tuy nhiên, đối với các nhiệm vụ có mục đích chung, nặng về nghiên cứu, tôi thích sử dụng Gemini Pro hơn. Bằng cách này, tôi tận dụng tối đa cả hai thế giới, tận dụng tối đa cả hai công nghệ tuyệt vời.
Nhân tiện, Ollama và GPT4ALL không phải là lựa chọn duy nhất của bạn. Mở WebUI là một cách dễ dàng khác để thiết lập LLM cục bộ.