Giới thiệu
- Nền tảng phân khúc đóng vai trò quan trọng trong việc hiểu và phân loại khách hàng, sản phẩm và các dữ liệu liên quan khác.
- Phân đoạn bao gồm việc chia một nhóm lớn hơn thành các nhóm nhỏ hơn, đồng nhất hơn dựa trên các tiêu chí nhất định.
- Dưới đây là một số ví dụ về nền tảng phân khúc trong các lĩnh vực khác nhau, ví dụ:phân khúc khách hàng cho chiến lược tiếp thị được cá nhân hóa, khuyến mại có mục tiêu và trải nghiệm mua sắm tùy chỉnh hơn.
Mục lục
- Hiểu các yêu cầu
- Kiến trúc cơ bản
- Thành phần kiến trúc
- Những thách thức về thiết kế
- Giải pháp được đề xuất
- Ghi chú kết thúc
1. Tìm hiểu yêu cầu
Việc thiết kế nền tảng phân khúc có độ trễ thấp cho các phân khúc khách hàng trong thương mại điện tử đưa ra những thách thức cụ thể liên quan đến xử lý thời gian thực, trải nghiệm người dùng và tính chất năng động của hành vi khách hàng. Dưới đây là một số thách thức bạn có thể gặp phải trong bối cảnh này:
-
Bộ dữ liệu lớn và động
- Nền tảng thương mại điện tử xử lý các tập dữ liệu lớn và thay đổi liên tục, bao gồm hồ sơ khách hàng, danh mục sản phẩm và lịch sử giao dịch.
- Việc quản lý và xử lý các tập dữ liệu khổng lồ này theo thời gian thực trong khi vẫn duy trì độ trễ thấp là một thách thức đáng kể.
-
Khả năng mở rộng
- Việc thiết kế để có khả năng mở rộng là điều cần thiết để xử lý các khối lượng công việc khác nhau. Việc đảm bảo rằng hệ thống có thể mở rộng theo chiều ngang bằng cách bổ sung thêm nhiều đơn vị xử lý mà không làm giảm độ trễ đòi hỏi phải lập kế hoạch kiến trúc cẩn thận.
-
Xử lý không đồng bộ
- Tận dụng quá trình xử lý không đồng bộ có thể giúp tách rời các thành phần và cải thiện khả năng phản hồi tổng thể của hệ thống. Tuy nhiên, việc quản lý giao tiếp không đồng bộ mà không gây ra sự phức tạp hoặc chậm trễ đòi hỏi phải có thiết kế cẩn thận.
-
Luồng dữ liệu và đường ống
- Việc thiết kế luồng dữ liệu và quy trình xử lý hiệu quả là rất quan trọng đối với các hệ thống có độ trễ thấp.
- Việc giảm thiểu thời gian tiêu tốn dữ liệu khi truyền giữa các thành phần và tối ưu hóa trình tự các bước xử lý có thể tác động đáng kể đến độ trễ tổng thể.
-
Kiến trúc vi dịch vụ
- Việc triển khai kiến trúc vi dịch vụ có thể nâng cao khả năng mở rộng và tính linh hoạt. Tuy nhiên, việc đảm bảo giao tiếp liền mạch giữa các vi dịch vụ mà không gây ra độ trễ có thể là một thách thức.
- Việc thiết kế các API hiệu quả và quản lý hoạt động liên lạc giữa các dịch vụ là rất quan trọng.
2. Kiến trúc cơ bản
Nền tảng phân khúc bao gồm ba hệ thống con chính: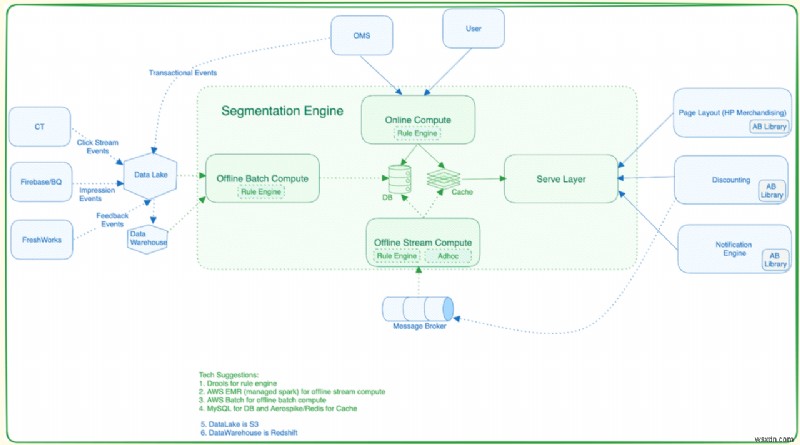
-
Dịch vụ điện toán (Tính toán hàng loạt ngoại tuyến/Tính toán trực tuyến):
- Trích xuất phân khúc người dùng từ dữ liệu thô bằng Spark Jobs.
- Công việc Spark truy xuất, dọn dẹp và xác thực dữ liệu từ hồ dữ liệu.
- Dữ liệu kết quả được gửi đến hệ thống phụ cung cấp.
-
Dịch vụ nhập:
- Chuyển các phân đoạn được tính toán từ dịch vụ điện toán sang dịch vụ phân đoạn.
- Quản lý việc bao gồm và loại trừ người dùng trong các phân khúc.
-
Dịch vụ phân đoạn (Lớp phục vụ):
-
Cung cấp phân khúc người dùng dựa trên yêu cầu cụ thể về dịch vụ người dùng hoặc dịch vụ giảm giá.
-
Dịch vụ giảm giá có thể truy vấn dựa trên ID người dùng và tính toán mức giảm giá hiện có
ID người dùng ID phân đoạn Được tạo tại 2521Đoạn XNgày 3 tháng 12 năm 20232788Đoạn YNgày 3 tháng 12 năm 20233943Đoạn ZNgày 3 tháng 12 năm 2023
-
3. Thành phần kiến trúc
Nền tảng Phân đoạn bao gồm các thành phần chính sau: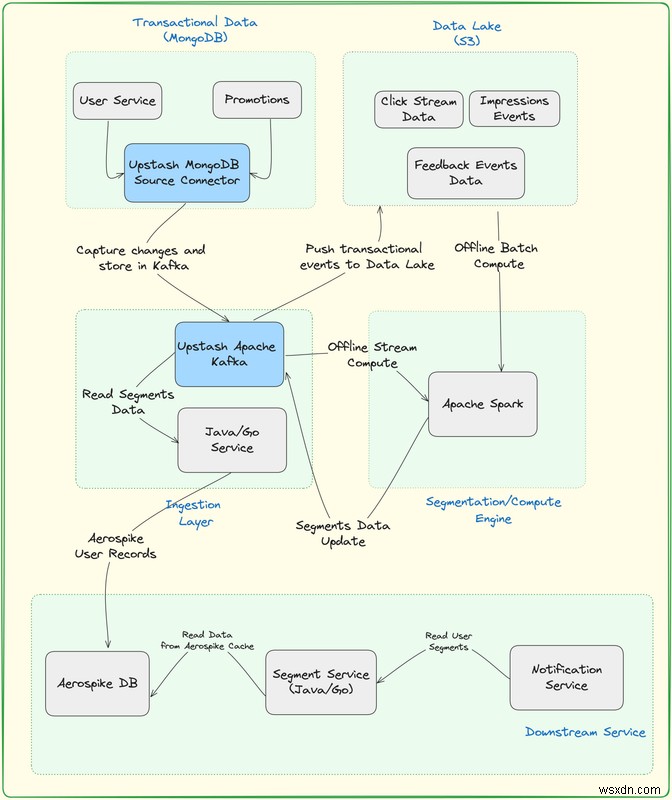
-
Hồ dữ liệu - S3
- S3 là một tùy chọn linh hoạt và được áp dụng rộng rãi để hoạt động như một hồ dữ liệu. Khả năng lưu trữ đối tượng bền bỉ và có thể mở rộng giúp nó phù hợp để lưu trữ và quản lý hiệu quả khối lượng lớn các loại dữ liệu đa dạng.
- Bằng cách sử dụng S3 làm hồ dữ liệu, các tổ chức có thể hưởng lợi từ các tính năng mạnh mẽ của nó để lưu trữ, truy xuất và quản lý dữ liệu, khiến S3 trở thành lựa chọn phổ biến trong nhiều ứng dụng và kiến trúc tập trung vào dữ liệu.
-
Cơ sở dữ liệu giao dịch MongoDB
- Mô hình hướng tài liệu của MongoDB có lợi cho các trường hợp sử dụng giao dịch vì nó cho phép bạn lưu trữ các cấu trúc dữ liệu phức tạp ở định dạng tương tự như JSON. Tính linh hoạt này đặc biệt hữu ích cho các ứng dụng mà cấu trúc dữ liệu có thể phát triển theo thời gian.
-
Cụm Kafka nâng cao
- Bạn có thể truyền trực tuyến các sự kiện lưu lượng truy cập (nhấp chuột) từ ứng dụng web của mình tới Upstash Kafka sau đó bạn có thể lưu trữ chúng vào hồ dữ liệu để xử lý thêm.
- Upstash Kafka là sản phẩm Kafka không có máy chủ đầu tiên. Với mô hình trả tiền theo yêu cầu, Bạn có thể có cụm Kafka được quản lý hoàn toàn mà không phải trả hàng trăm đô la. Với cấp miễn phí, Bạn có thể tạo cụm Kafka trong vài giây mà không cần nhập thẻ tín dụng. Nhóm Upstash đảm nhận việc cung cấp, bảo trì, mở rộng quy mô, nâng cấp và tất cả những công việc tẻ nhạt khác trong khi bạn tập trung vào ứng dụng của mình.
-
Trình kết nối nguồn MongoDB nâng cấp
- Trình kết nối nguồn MongoDB là một thành phần được sử dụng trong các nền tảng phát trực tuyến và tích hợp dữ liệu, chẳng hạn như Apache Kafka Connect, để kết nối với cơ sở dữ liệu MongoDB và ghi lại các thay đổi hoặc sự kiện trong thời gian thực.
- Trình kết nối Nguồn MongoDB Upstash tạo điều kiện di chuyển dữ liệu từ MongoDB sang hệ thống hoặc nền tảng khác, cho phép tích hợp và phân tích dữ liệu liền mạch.
-
Tia lửa Apache
- Apache Spark là một công cụ đa ngôn ngữ để thực thi kỹ thuật dữ liệu, khoa học dữ liệu và học máy trên các máy hoặc cụm nút đơn.
- Bằng cách tích hợp Upstash Kafka với Apache Spark do Upstash cung cấp ngay lập tức, bạn sẽ truyền các sự kiện lưu lượng truy cập (nhấp chuột) từ ứng dụng web của mình tới Upstash Kafka sau đó bạn có thể phân tích nó theo thời gian thực.
- Apache Spark sẽ chịu trách nhiệm xử lý các bản cập nhật cho phân khúc người dùng. Những cập nhật này sau đó sẽ được ghi vào Upstash Kafka trước khi được phổ biến để cập nhật cơ sở dữ liệu Aerospike.
4. Thử thách thiết kế
Việc áp dụng và sử dụng công cụ phân đoạn ngày càng tăng có thể gây ra những thách thức nhất định cho hệ thống.
- Tắc nghẽn QPS ghi:Việc tạo nhiều phân đoạn lớn hơn có thể dẫn đến tắc nghẽn trong truy vấn ghi mỗi giây (QPS), dẫn đến thời gian chờ đợi kéo dài để tạo phân đoạn.
- Yêu cầu độ trễ thấp hơn:Việc đạt được độ trễ rất thấp là rất quan trọng để gửi một số thông tin liên lạc nhất định, đặc biệt là khi xác định xem người dùng có thuộc một phân khúc cụ thể hay không.
-
Độ trễ đọc
-
Hơn nữa, khi nền tảng tiếp tục phát triển, ngay cả với độ trễ yêu cầu <50 mili giây để đọc, người ta dự đoán rằng tốc độ này có thể không đủ cho một số dịch vụ và trường hợp sử dụng trong tương lai của chúng.
-
Ví dụ:dịch vụ thông báo dự kiến sẽ yêu cầu kiểm tra nhanh để xác định tư cách thành viên của phân khúc người dùng trước khi gửi thông tin liên lạc. Việc tăng độ trễ cho mỗi yêu cầu liên lạc được dự đoán là không thể chấp nhận được trong tương lai.
-
-
Quản lý cơ sở hạ tầng Kafka
-
Việc xử lý hàng triệu sự kiện mỗi phút từ các nguồn giao dịch thực sự có thể đặt ra thách thức khi sử dụng cơ sở hạ tầng Kafka và việc quản lý hiệu quả thông lượng cao như vậy đòi hỏi phải xem xét cẩn thận nhiều yếu tố khác nhau.
-
Kiểm tra và tối ưu hóa hiệu suất thường xuyên là chìa khóa để duy trì cơ sở hạ tầng Kafka thông lượng cao.
-
-
Thu thập dữ liệu thay đổi MongoDB
-
Việc tổng hợp các sự kiện từ các ứng dụng web, đặc biệt là khi chúng được lưu trữ trong cơ sở dữ liệu giao dịch truyền thống như MongoDB, sau đó đẩy chúng vào hồ dữ liệu thực sự có thể đòi hỏi một số nỗ lực.
-
Sử dụng các cơ chế thu thập dữ liệu thay đổi do MongoDB cung cấp hoặc triển khai giải pháp tùy chỉnh để nắm bắt các thay đổi trong cơ sở dữ liệu.
-
5. Giải pháp đề xuất
-
Bộ nhớ đệm được phân phối Aerospike để cải thiện độ trễ đọc
-
Aerospike sẽ chứa các phân đoạn người dùng trong đó ID người dùng đóng vai trò là khóa chính để truy cập các phân đoạn người dùng.
-
Ngoài ra, bạn cũng có thể triển khai các chỉ mục phụ trên ID phân khúc, đơn giản hóa việc truy xuất người dùng phân khúc và loại bỏ nhu cầu lưu trữ riêng người dùng phân khúc
-
Hơn nữa, thiết kế này nhằm mục đích đáp ứng các yêu cầu về độ trễ, với tiềm năng hoạt động như một bộ đệm, có khả năng thay thế nhu cầu về Redis.
-
Việc thay thế Aerospike hiện tại bằng Upstash Redis sẽ cần phải quản lý hai bộ dữ liệu:phân khúc người dùng và phân khúc người dùng.
-
-
Kafka Upstash không có máy chủ để quản lý cơ sở hạ tầng Kafka
-
Với Upstash Kafka, bạn sẽ có được một dịch vụ được quản lý hoàn toàn. Điều này ngụ ý rằng Upstash xử lý tất cả các nhiệm vụ kỹ thuật, chẳng hạn như cung cấp máy chủ, mở rộng quy mô và bảo trì liên quan đến việc chạy cụm Kafka.
-
Điều này giúp bạn không cần phải lo lắng về những việc như thiết lập cơ sở hạ tầng, đảm bảo mọi thứ hoạt động chính xác và bảo trì cơ sở hạ tầng theo thời gian.
-
Điều này cho phép bạn tập trung vào việc tận dụng Kafka cho các yêu cầu và mục tiêu riêng của mình. Không còn gánh nặng quản lý cơ sở hạ tầng, giờ đây bạn có thể tập trung năng lượng vào việc nâng cao chất lượng tổng thể của ứng dụng, đặc biệt là trong môi trường phát triển đang phát triển nhanh chóng.
-
Giá tăng dần về 0: Một dịch vụ serverless thực sự sẽ không tính phí nếu bạn không thường xuyên sử dụng nó. Giá theo yêu cầu là tính năng nổi bật nhất của chúng tôi. Bạn đã thiết kế các sản phẩm và cơ sở hạ tầng của mình để phù hợp với mô hình định giá này ngay từ ngày đầu. Điều này đòi hỏi phải giảm thiểu chi phí cố định, điều này khá khó khăn đối với một con thú như Kafka.
-
Không có gánh nặng vận hành cho người dùng: Người dùng tạo chủ đề Kafka và bắt đầu sử dụng nó. Tính sẵn sàng cao, khả năng mở rộng, nâng cấp, sao lưu… tất cả là trách nhiệm của chúng tôi.
-
Không kết nối: Các chức năng không có máy chủ không giữ trạng thái. Vì vậy, bạn sẽ có thể truy cập dữ liệu của mình bằng kết nối không trạng thái. Sản phẩm Kafka của chúng tôi hỗ trợ giao thức Kafka TCP nên tất cả máy khách Kafka sẽ hoạt động với Upstash. Bạn cũng có API REST tích hợp sẵn để kích hoạt các môi trường không kết nối như AWS Lambda hoặc Cloudflare Workers.
-
-
MongoDB CDC sử dụng Trình kết nối nguồn Upstash MongoDB
-
Kafka Connect là một công cụ để truyền dữ liệu giữa Apache Kafka và các hệ thống khác mà không cần viết một dòng mã nào. Thông qua Kafka Sink Connectors, bạn có thể xuất dữ liệu của mình sang bất kỳ bộ lưu trữ nào khác. Thông qua Trình kết nối nguồn Kafka, bạn có thể lấy dữ liệu về các chủ đề Kafka của chúng tôi từ các hệ thống khác.
-
Trình kết nối Kafka có thể tự lưu trữ nhưng nó yêu cầu bạn phải thiết lập và duy trì các quy trình/máy bổ sung. Upstash cung cấp các phiên bản trình kết nối được lưu trữ cho cụm Kafka của bạn. Điều này sẽ giúp bạn bớt gánh nặng duy trì một hệ thống bổ sung và nó cũng sẽ hoạt động hiệu quả hơn vì nó nằm gần cụm của bạn.
-
6. Ghi chú kết thúc
Bài đăng trên blog này khám phá các nguyên tắc thiết kế của nền tảng phân khúc có độ trễ thấp tận dụng các công nghệ do Upstash cung cấp. Cơ sở hạ tầng được thiết kế để mở rộng quy mô một cách liền mạch, đáp ứng được hàng triệu người dùng và xử lý hàng terabyte dữ liệu được lưu trữ trong hồ dữ liệu.