- Đây là phần tiếp theo của bài đăng trên blog được xuất bản vào tháng 4 năm 2021.
Chúng tôi đã xây dựng một ứng dụng mẫu so sánh hiệu suất của cơ sở dữ liệu không máy chủ hàng đầu bằng cách sử dụng trường hợp sử dụng web phổ biến và các chức năng không máy chủ. Cơ sở dữ liệu là DynamoDB, MongoDB (Atlas), Firestore, Cassandra (Datastax Astra), FaunaDB và Redis (Upstash)
Kiểm tra ứng dụng và mã nguồn.
Những gì chúng tôi so sánh là độ trễ của việc tìm nạp 10 bài báo hàng đầu cho mỗi cơ sở dữ liệu. Toàn bộ dữ liệu là 7001 tin bài thực tế được thu thập từ New York Times API. Truy vấn mà chúng tôi đo lường có độ trễ là:
select * from news where section = “World” order by view_count desc limit 10
Phần phụ trợ được triển khai dưới dạng các chức năng không máy chủ trên AWS Lambda (chức năng Google Cloud cho Firestore). Chúng tôi đã sắp xếp các chức năng không có máy chủ và cơ sở dữ liệu trong cùng một khu vực (khi có thể) để giảm thiểu độ trễ.
Chúng tôi đã loại trừ thời gian kết nối cơ sở dữ liệu khỏi phép đo độ trễ và ghi lại dấu thời gian ngay trước và sau truy vấn. Độ trễ được đo và ghi lại ở phần phụ trợ (bên trong chức năng không có máy chủ) nên nó không bao gồm độ trễ mạng giữa trình duyệt và máy chủ. Ngoài ra, độ trễ cũng không bị ảnh hưởng bởi thời gian khởi động lạnh của chức năng không máy chủ.
Để mô phỏng dữ liệu động trong thế giới thực, chúng tôi đã gán các giá trị view_count ngẫu nhiên cho 10 bài viết hàng đầu. Vì vậy, mỗi lần chúng tôi buộc cơ sở dữ liệu trả về một nhóm bài viết khác nhau, để ngăn chúng sử dụng bộ nhớ đệm của chúng. Các hoạt động cập nhật không được bao gồm trong tính toán độ trễ.
Đây là con số độ trễ tính đến ngày hôm nay (25 tháng 8)
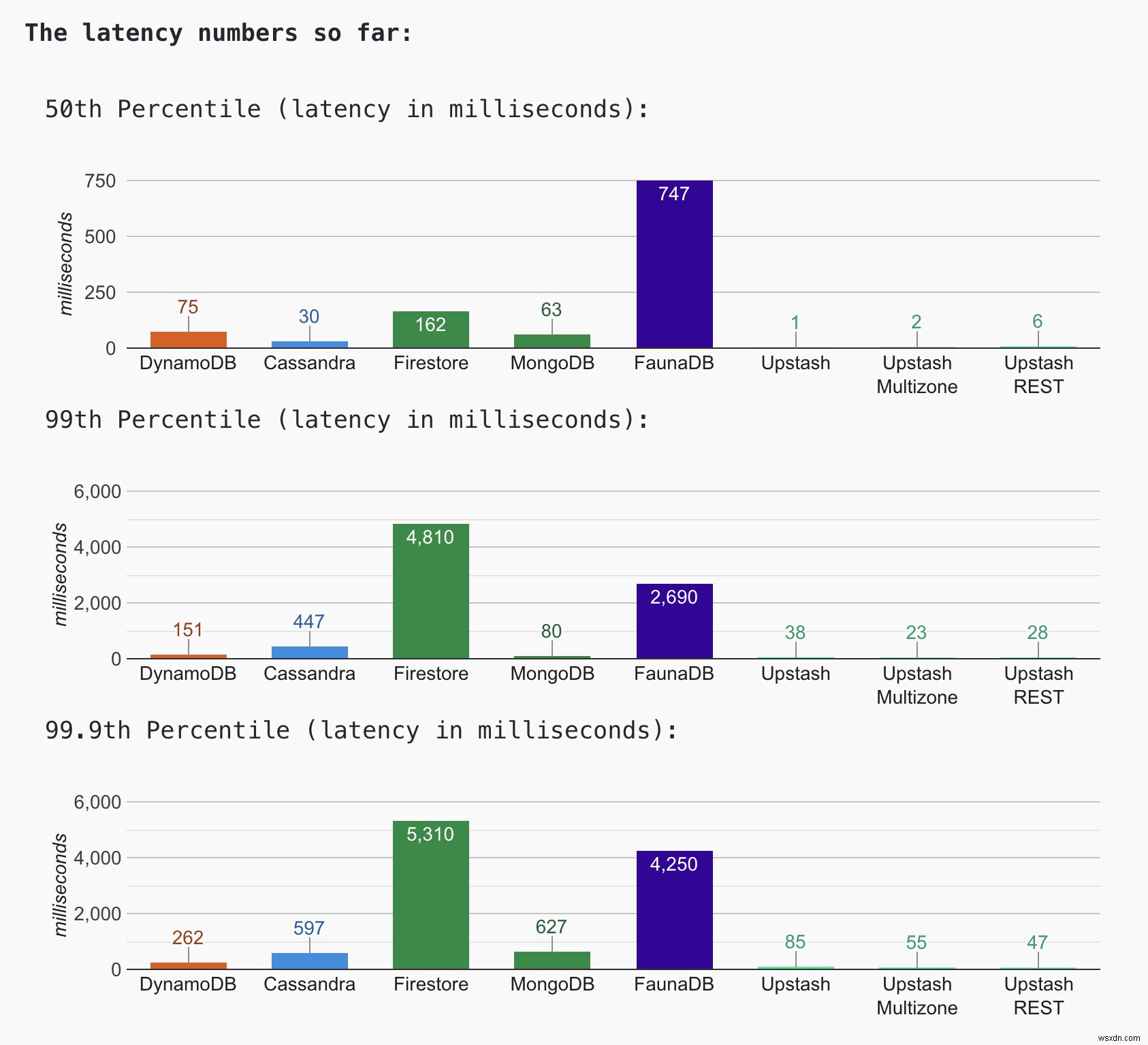
Dưới đây, tôi sẽ liệt kê các cấu hình tùy chỉnh được áp dụng cho từng cơ sở dữ liệu:
DynamoDB
Khu vực:US-West-1
Khả năng đọc và ghi:50 (giá trị mặc định là 5).
Chỉ mục:GSI với phần khóa phân vùng (Chuỗi) và sắp xếp khóa view_count (Số)
Lưu ý:Bảng toàn cục không được bật vì máy khách đã ở cùng khu vực (US-West-1)
Kiểm tra mã.
MongoDB (Bản đồ)
Khu vực:AWS N. Virginia (us-East-1)
Cấp cụm:M5 (Chung)
Chỉ mục:Chỉ mục tổng hợp trên section và view_count
Lưu ý:Tôi ước tôi có thể thử cung cấp không máy chủ MongoDB nhưng nó không có trình điều khiển Node.js. Nhưng sẽ không có vấn đề gì vì tôi giữ kết nối db bên ngoài phần mà tôi tính toán độ trễ.
Kiểm tra mã.
Firestore
Khu vực:GCP US-Central
Chế độ:Kho dữ liệu
Chỉ mục:Chỉ mục tổng hợp trên phần (tăng dần) và view_count (giảm dần)
Kiểm tra mã.
Cassandra (Datastax Astra)
Khu vực:AWS US-East-1
Gói:Thanh toán khi bạn di chuyển
Chỉ mục:KHÓA CHÍNH (section, view_count, id)
API:API REST
Kiểm tra mã.
FaunaDB
Gói:Cá nhân ($ 25 mỗi tháng)
Chỉ mục:term =section, value =view_count
API:FQL
Kiểm tra mã.
Redis (Upstash)
Khu vực:AWS US-West-1
Gói:Thanh toán khi bạn đi.
Chỉ mục:SortedSet được sử dụng.
Lưu ý:Cơ sở dữ liệu đơn và đa vùng được kiểm tra riêng biệt.
Kiểm tra mã.
Ghi chú Đặc biệt
- Theo mặc định, FaunaDB có đảm bảo tính nhất quán tốt hơn và sao chép toàn cầu. Ngoài ra nó không cho phép bạn chọn khu vực để triển khai. Đây có thể là những lý do đằng sau hiệu suất tương đối thấp hơn.
- Firestore có hiệu suất tương tự với những người khác nhưng có sự khác biệt lớn hơn. Nó có thể là do có một chi phí của các kết nối lạnh. Tôi không thể tìm thấy cách giữ cho kết nối tồn tại. Hãy cho tôi biết nếu bạn có ý tưởng về vấn đề này.
- Cassandra không cho phép cập nhật các trường khóa chính. Chỉ mục phụ không được khuyến khích nếu bạn sẽ cập nhật chỉ mục nhiều. Vì vậy, tôi không thể cập nhật view_count, điều này có thể ảnh hưởng tích cực đến hiệu suất của nó.
- Mặc dù một vùng của Upstash trông nhanh hơn một chút, không có sự khác biệt lớn về hiệu suất giữa thiết lập một vùng và nhiều vùng cho Upstash. API REST có vẻ như có hiệu suất rất gần với API gốc ở các phân vị cao hơn.
Lưu ý rằng đây là một nỗ lực không ngừng vì vậy chúng tôi sẽ tiếp tục cấu trúc lại mã để cải thiện chất lượng của điểm chuẩn. Khi chúng tôi cấu trúc lại mã của một sản phẩm, chúng tôi sẽ đặt lại biểu đồ của nó. Vui lòng kiểm tra mã và cho chúng tôi biết nếu có những điều cần cải thiện. Bạn có thể liên hệ với chúng tôi trên twitter và bất hòa.