Trong bài viết này, tôi sẽ so sánh độ trễ của ba cơ sở dữ liệu không máy chủ DynamoDB, FaunaDB, Upstash (Redis) cho một trường hợp sử dụng web phổ biến.
Tôi đã tạo một trang web tin tức mẫu và tôi đang ghi lại độ trễ liên quan đến cơ sở dữ liệu với mỗi yêu cầu đến trang web. Kiểm tra trang web và mã nguồn.
Tôi đã chèn 7001 bài báo NY Times vào mỗi cơ sở dữ liệu. Các bài báo được thu thập từ New York Times Archive API (tất cả các bài báo của tháng 1 năm 2021). Tôi cho điểm ngẫu nhiên từng bài báo. Theo yêu cầu của mỗi trang, tôi truy vấn 10 bài báo hàng đầu trong World từ mỗi cơ sở dữ liệu.
Tôi sử dụng các hàm không máy chủ (AWS Lambda) để tải các bài báo từ mỗi cơ sở dữ liệu. Thời gian phản hồi của việc tìm nạp 10 bài báo đang được ghi lại dưới dạng độ trễ bên trong hàm lambda. Lưu ý rằng độ trễ được ghi lại chỉ nằm giữa hàm lambda và cơ sở dữ liệu. Đó không phải là độ trễ giữa trình duyệt của bạn và máy chủ.
Sau mỗi yêu cầu đọc, tôi cập nhật điểm số một cách ngẫu nhiên để mô phỏng dữ liệu động. Nhưng tôi loại trừ phần này khỏi tính toán độ trễ.
Trước tiên, chúng tôi sẽ kiểm tra ứng dụng, sau đó chúng tôi sẽ xem xét kết quả:
Thiết lập AWS Lambda
Khu vực:US-West-1
Bộ nhớ:1024Mb
Thời gian chạy:nodejs14.x
Thiết lập DynamoDB
Tôi đã tạo một bảng DynamoDB ở US-West-1 với khả năng đọc và ghi là 50 (giá trị mặc định là 5).
Chỉ mục của tôi là GSI với khóa phân vùng section (String) và sắp xếp khóa view_count (Number) .
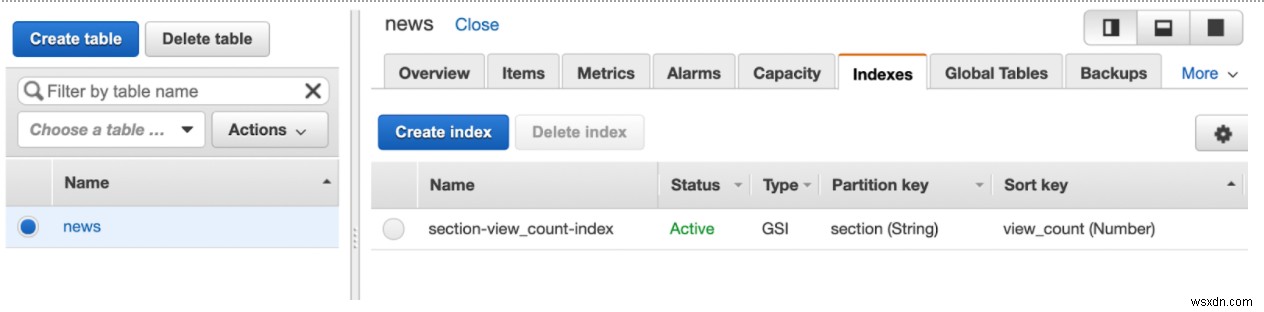
Thiết lập FaunaDB
FaunaDB là một cơ sở dữ liệu được sao chép toàn cầu, không có cách nào để chọn một khu vực. Tôi đã sử dụng FQL, giả sử API GraphQL có thể có một số chi phí.
Tôi đã tạo một chỉ mục với phần điều khoản và giá trị ref như bên dưới. Tôi đã đặt nó không được đăng với hy vọng cải thiện hiệu suất.
CreateIndex({
name: "section_by_view_count",
unique: false,
serialized: false,
source: Collection("news"),
terms: [
{ field: ["data", "section"] }
],
values: [
{ field: ["data", "view_count"], reverse: true },
{ field: ["ref"] }
]
})
Thiết lập Redis
Tôi đã tạo cơ sở dữ liệu loại Chuẩn ở vùng US-West-1 trong Upstash. Tôi đã sử dụng Tập hợp được sắp xếp cho mỗi danh mục tin tức. Vì vậy, tất cả World các tin bài sẽ nằm trong Tập hợp được sắp xếp với khóa World .
Khởi tạo cơ sở dữ liệu
Tôi đã tải xuống 7001 bài báo dưới dạng tệp JSON từ trang web NYTimes API, sau đó tạo một tập lệnh NodeJS cho mỗi cơ sở dữ liệu đọc JSON và chèn bản ghi tin tức vào cơ sở dữ liệu. Xem các tệp:initDynamo.js, initFauna.js, initRedis.js
Truy vấn DynamoDB
Tôi đã sử dụng AWS SDK để kết nối với DynamoDB. Để giảm thiểu độ trễ, tôi đang duy trì kết nối DynamoDB. Tôi đã sử dụng perf_hooks thư viện để đo thời gian phản hồi. Tôi ghi lại thời gian hiện tại ngay trước khi truy vấn DynamoDB cho 10 bài báo hàng đầu. Tôi đã tính toán độ trễ ngay khi nhận được phản hồi từ DynamoDB. Sau đó, tôi chấm điểm ngẫu nhiên các bài báo và chèn số độ trễ vào tập hợp được sắp xếp của Redis nhưng những phần này nằm ngoài phần tính toán độ trễ. Xem mã bên dưới:
var AWS = require("aws-sdk");
AWS.config.update({
region: "us-west-1",
});
const https = require("https");
const agent = new https.Agent({
keepAlive: true,
maxSockets: Infinity,
});
AWS.config.update({
httpOptions: {
agent,
},
});
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const tableName = "news";
var params = {
TableName: tableName,
IndexName: "section-view_count-index",
KeyConditionExpression: "#sect = :section",
ExpressionAttributeNames: {
"#sect": "section",
},
ExpressionAttributeValues: {
":section": process.env.SECTION,
},
Limit: 10,
ScanIndexForward: false,
};
const docClient = new AWS.DynamoDB.DocumentClient();
module.exports.load = (event, context, callback) => {
let start = performance.now();
docClient.query(params, (err, result) => {
if (err) {
console.error(
"Unable to scan the table. Error JSON:",
JSON.stringify(err, null, 2)
);
} else {
// response is ready so we can set the latency
let latency = performance.now() - start;
let response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: result,
}),
};
// we are setting random score to top-10 items to simulate real time dynamic data
result.Items.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
var params2 = {
TableName: tableName,
Key: {
id: item.id,
},
UpdateExpression: "set view_count = :r",
ExpressionAttributeValues: {
":r": view_count,
},
};
docClient.update(params2, function (err, data) {
if (err) {
console.error(
"Unable to update item. Error JSON:",
JSON.stringify(err, null, 2)
);
}
});
});
// pushing the latency to the histogram
const client = new Redis(process.env.LATENCY_REDIS_URL);
client.lpush("histogram-dynamo", latency, (resp) => {
client.quit();
callback(null, response);
});
}
});
};
Truy vấn FaunaDB
Tôi đã sử dụng faunadb thư viện để kết nối và truy vấn FaunaDB. Phần còn lại rất giống với mã DynamoDB. Để giảm thiểu độ trễ, tôi đang duy trì kết nối. Tôi đã sử dụng perf_hooks thư viện để đo thời gian phản hồi. Tôi ghi lại thời gian hiện tại ngay trước khi truy vấn FaunaDB cho 10 bài báo hàng đầu. Tôi đã tính toán độ trễ ngay khi nhận được phản hồi từ FaunaDB. Sau đó, tôi chấm điểm ngẫu nhiên các bài báo và gửi số độ trễ đến một tập hợp được sắp xếp của Redis nhưng những phần này nằm ngoài phần tính toán độ trễ. Xem mã bên dưới:
const faunadb = require("faunadb");
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET,
keepAlive: true,
});
const section = process.env.SECTION;
module.exports.load = async (event) => {
let start = performance.now();
let ret = await client
.query(
// the below is Fauna API for "select from news where section = 'world' order by view_count limit 10"
q.Map(
q.Paginate(q.Match(q.Index("section_by_view_count"), section), {
size: 10,
}),
q.Lambda(["view_count", "X"], q.Get(q.Var("X")))
)
)
.catch((err) => console.error("Error: %s", err));
console.log(ret);
// response is ready so we can set the latency
let latency = performance.now() - start;
const rclient = new Redis(process.env.LATENCY_REDIS_URL);
await rclient.lpush("histogram-fauna", latency);
await rclient.quit();
let result = [];
for (let i = 0; i < ret.data.length; i++) {
result.push(ret.data[i].data);
}
// we are setting random scores to top-10 items asynchronously to simulate real time dynamic data
ret.data.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
client
.query(
q.Update(q.Ref(q.Collection("news"), item["ref"].id), {
data: { view_count },
})
)
.catch((err) => console.error("Error: %s", err));
});
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: result,
},
}),
};
};
Truy vấn Redis
Tôi đã sử dụng ioredis thư viện để kết nối và đọc từ Redis trong Upstash. Tôi đã sử dụng lệnh ZREVRANGE để tải dữ liệu từ Tập hợp đã sắp xếp. Để giảm thiểu độ trễ, tôi đã sử dụng lại kết nối tạo ứng dụng khách Redis bên ngoài chức năng. Tương tự như DynamoDB và FaunaDB, tôi đang cập nhật điểm số và gửi số độ trễ đến một Redis DB khác để tính toán biểu đồ. Xem mã:
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const client = new Redis(process.env.REDIS_URL);
module.exports.load = async (event) => {
let section = process.env.SECTION;
let start = performance.now();
let data = await client.zrevrange(section, 0, 9);
let items = [];
for (let i = 0; i < data.length; i++) {
items.push(JSON.parse(data[i]));
}
// response is ready so we can set the latency
let latency = performance.now() - start;
// we are setting random scores to top-10 items to simulate real time dynamic data
for (let i = 0; i < data.length; i++) {
let view_count = Math.floor(Math.random() * 1000);
await client.zadd(section, view_count, data[i]);
}
// await client.quit();
// pushing the latency to the histogram
const client2 = new Redis(process.env.LATENCY_REDIS_URL);
await client2.lpush("histogram-redis", latency);
await client2.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: items,
},
}),
};
};
Tính toán biểu đồ
Tôi đã sử dụng hdr-histogram-js thư viện để tính toán biểu đồ. Đây là cách triển khai js của thư viện biểu đồ hdr của Gil Tene. Xem mã của hàm lambda nhận số độ trễ và tính toán biểu đồ.
const Redis = require("ioredis");
const hdr = require("hdr-histogram-js");
module.exports.load = async (event) => {
const client = new Redis(process.env.LATENCY_REDIS_URL);
let dataRedis = await client.lrange("histogram-redis", 0, 10000);
let dataDynamo = await client.lrange("histogram-dynamo", 0, 10000);
let dataFauna = await client.lrange("histogram-fauna", 0, 10000);
const hredis = hdr.build();
const hdynamo = hdr.build();
const hfauna = hdr.build();
dataRedis.forEach((item) => {
hredis.recordValue(item);
});
dataDynamo.forEach((item) => {
hdynamo.recordValue(item);
});
dataFauna.forEach((item) => {
hfauna.recordValue(item);
});
await client.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify(
{
redis_min: hredis.minNonZeroValue,
dynamo_min: hdynamo.minNonZeroValue,
fauna_min: hfauna.minNonZeroValue,
redis_mean: hredis.mean,
dynamo_mean: hdynamo.mean,
fauna_mean: hfauna.mean,
redis_histogram: hredis,
dynamo_histogram: hdynamo,
fauna_histogram: hfauna,
},
null,
2
),
};
};
Kết quả
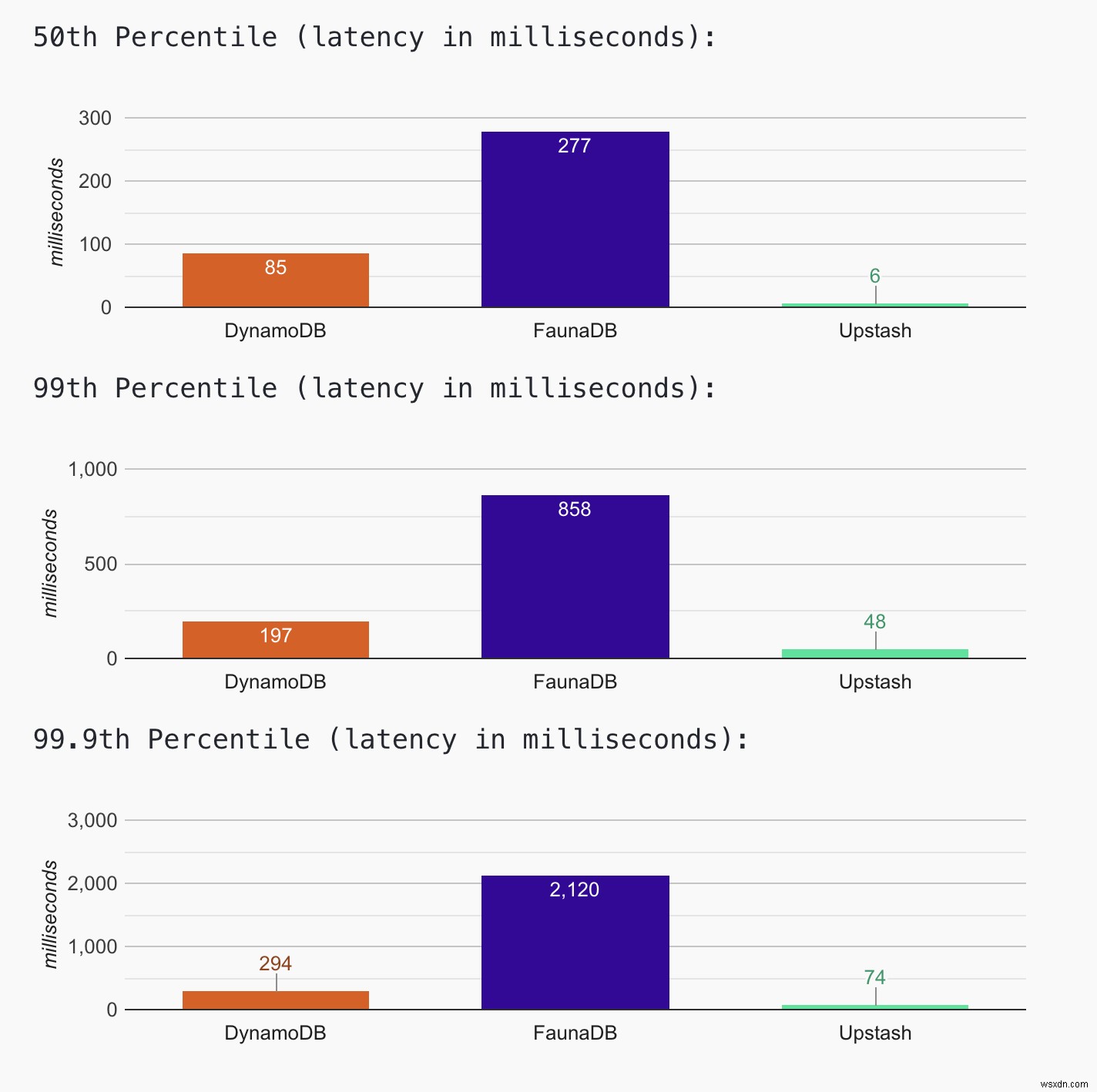
Kiểm tra trang web để biết kết quả mới nhất. Bạn cũng có thể tiếp cận dữ liệu biểu đồ mới nhất. Miễn là trang web đang hoạt động, chúng tôi sẽ tiếp tục thu thập dữ liệu và cập nhật biểu đồ. Kết quả tính đến hôm nay (ngày 12 tháng 4 năm 2021) cho thấy Upstash có độ trễ thấp nhất (~ 50 mili giây ở phân vị thứ 99) trong đó FaunaDB có độ trễ cao nhất (~ 900 mili giây ở phân vị thứ 99). DynamoDB có (~ 200ms ở phân vị thứ 99)
Hiệu ứng khởi động nguội
Mặc dù chúng tôi chỉ đo độ trễ cho phần truy vấn, nhưng khởi động nguội vẫn có tác dụng. Chúng tôi tối ưu hóa mã của mình bằng cách sử dụng lại các kết nối máy khách. Chúng tôi được hưởng lợi từ điều này miễn là thùng chứa Lambda còn nóng và đang chạy. Khi AWS giết vùng chứa (khởi động nguội), mã sẽ tạo lại ứng dụng khách, đây là một chi phí. Trong trang web ứng dụng, nếu bạn làm mới trang; bạn sẽ thấy số độ trễ giảm xuống ~ 1ms cho Upstash; và ~ 7ms đối với DynamoDB.
Tại sao FaunaDB lại chậm (trong điểm chuẩn này)?
Trong trang trạng thái của FaunaDB, bạn sẽ thấy số độ trễ tính bằng hàng trăm. Vì vậy, tôi cho rằng cấu hình của tôi không có sai sót lớn. Có thể có hai lý do đằng sau sự khác biệt về độ trễ này:
Tính nhất quán mạnh mẽ: Theo mặc định, cả DynamoDB và Upstash đều cung cấp tính nhất quán cuối cùng cho các lần đọc. FaunaDB cung cấp tính nhất quán và cô lập mạnh mẽ dựa trên Calvin. Tính nhất quán cao đi kèm với chi phí hiệu suất.
Nhân rộng toàn cầu: Đối với cả Upstash và DynamoDB, chúng tôi có thể định cấu hình cơ sở dữ liệu và hàm lambda ở trong cùng một vùng AWS. Trong FaunaDB, dữ liệu của bạn được sao chép trên toàn thế giới; vì vậy bạn không có tùy chọn để chọn khu vực của mình. Nếu các máy khách cơ sở dữ liệu của bạn được đặt trên khắp thế giới thì đây có thể là một lợi thế. Nhưng nếu bạn triển khai chương trình phụ trợ của mình đến một khu vực cụ thể, thì điều này sẽ gây ra thêm độ trễ.
Redis cung cấp độ trễ dưới mili giây. Tại sao nó không phải là trường hợp ở đây?
Tạo kết nối Redis mới trong hàm AWS Lambda gây ra chi phí đáng kể. Do ứng dụng không có được lưu lượng truy cập ổn định, AWS Lambda thường xuyên tạo lại kết nối (khởi động nguội). Vì vậy, phần lớn số độ trễ trong biểu đồ bao gồm thời gian tạo kết nối. Chúng tôi chạy một công việc tìm nạp trang web sau mỗi 15 giây; chúng tôi thấy rằng độ trễ cho Upstash đã giảm xuống còn ~ 1ms. Nếu bạn làm mới trang, bạn sẽ thấy hiệu ứng tương tự. Xem bài đăng trên blog của chúng tôi để biết cách tối ưu hóa các ứng dụng không máy chủ của bạn để có độ trễ thấp.
Sắp ra mắt
Upstash sẽ sớm phát hành sản phẩm Premium trong đó dữ liệu được sao chép sang nhiều vùng khả dụng. Tôi sẽ thêm nó để xem hiệu quả của việc nhân rộng vùng.
Hãy cho chúng tôi biết phản hồi của bạn trên Twitter hoặc Discord.
Cập nhật
Đã có một cuộc thảo luận sôi nổi trên HackerNews về banchmark của tôi và hiệu suất của Fauna. Tôi đã áp dụng các đề xuất và khởi động lại ứng dụng FaunaDB. Đó là lý do tại sao, số lượng bản ghi FaunaDB trong biểu đồ ít hơn những bản ghi khác.