Trong bài đăng này, tôi nói về cách tôi xây dựng Chatbot RAG nội dung tùy chỉnh nguồn mở với Upstash Vector, Upstash Redis, API suy luận khuôn mặt ôm, mô hình trò chuyện sao chép LLAMA-2-70B và Vercel. Upstash Vector đã giúp tôi chèn và truy vấn vectơ, tự động tạo hoặc cập nhật ngữ cảnh có liên quan cho từng tin nhắn của người dùng và Upstash Redis đã giúp tôi lưu trữ các cuộc hội thoại của chatbot.
Điều kiện tiên quyết
Bạn sẽ cần những thứ sau:
- Node.js 18 trở lên
- Tài khoản Upstash
- Tài khoản ôm mặt
- Tài khoản sao chép
- Tài khoản Vercel
Ngăn xếp công nghệ
Thiết lập Upstash Redis
Khi bạn đã tạo tài khoản Upstash và đăng nhập, bạn sẽ chuyển tới tab Redis và tạo cơ sở dữ liệu.
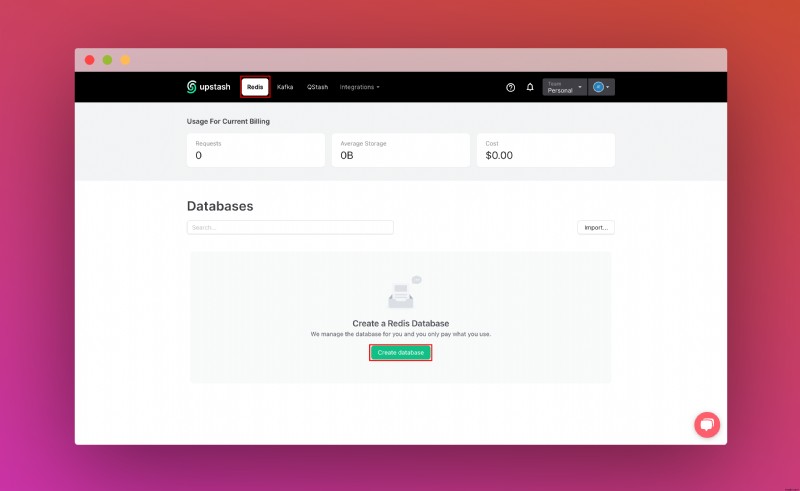
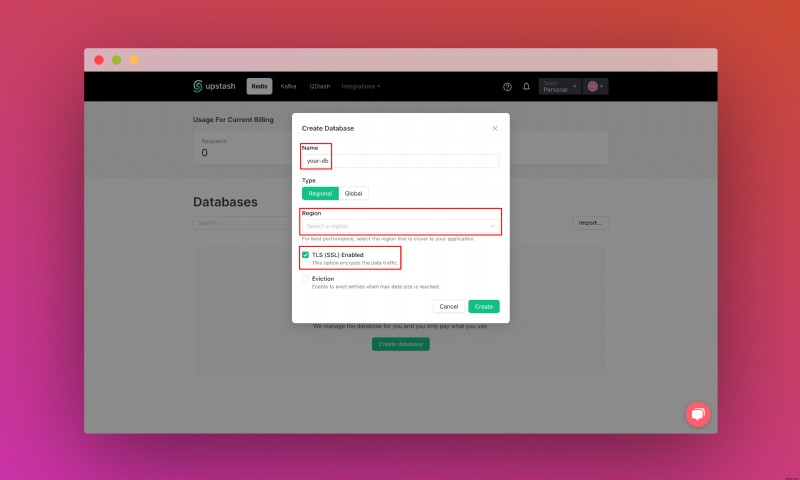
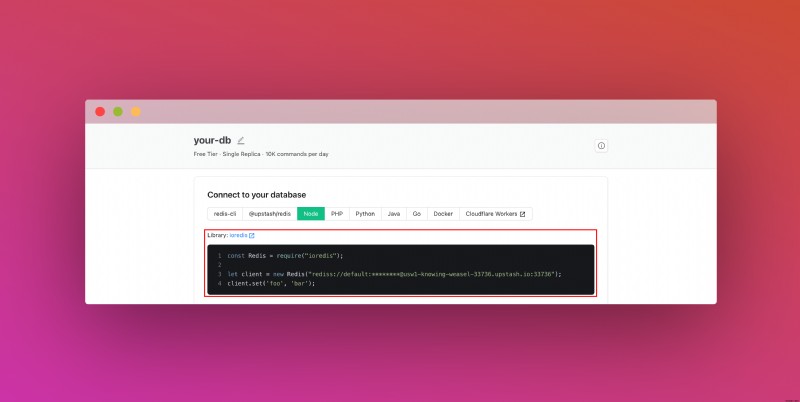
Sau khi tạo cơ sở dữ liệu, bạn sẽ chuyển đến tab Chi tiết. Cuộn xuống cho đến khi bạn tìm thấy phần Kết nối cơ sở dữ liệu của bạn. Sao chép nội dung và lưu ở nơi an toàn.
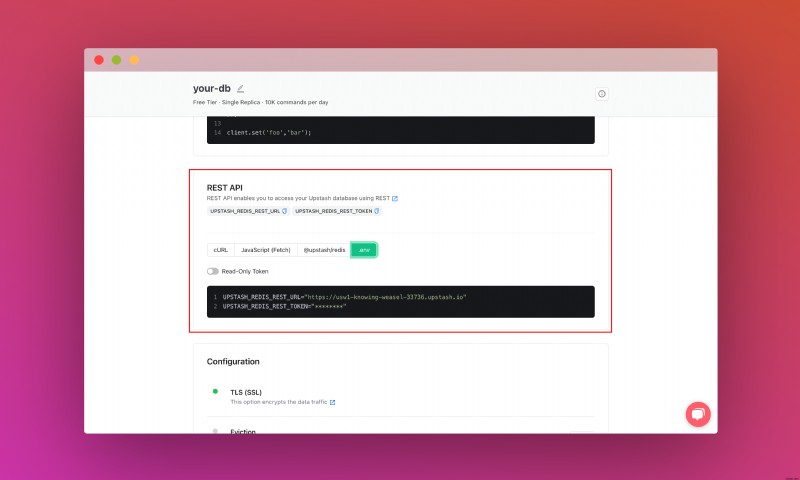
Ngoài ra, hãy cuộn xuống cho đến khi bạn tìm thấy phần API REST và chọn nút .env. Sao chép nội dung và lưu ở nơi an toàn.
Thiết lập Upstash Vector
Khi bạn đã tạo tài khoản Upstash và đăng nhập, bạn sẽ chuyển đến tab Vector và tạo Chỉ mục.
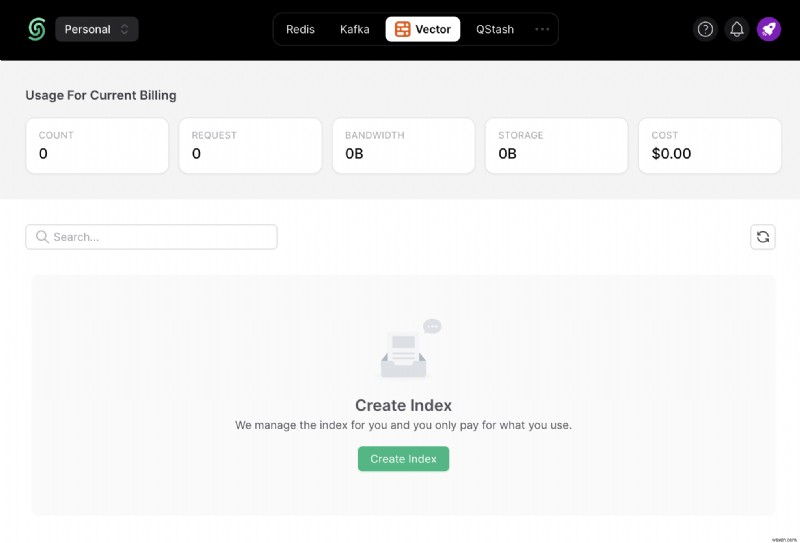
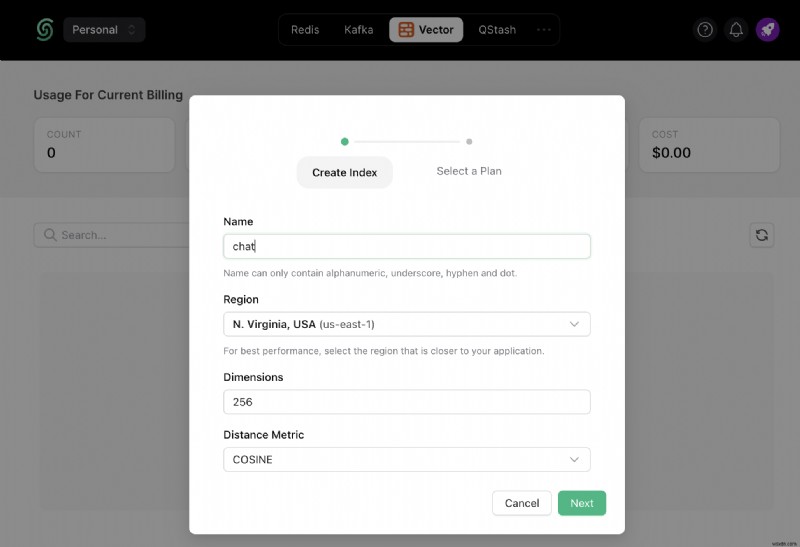
Ngoài ra, hãy cuộn xuống cho đến khi bạn tìm thấy Kết nối và chọn .env nút. Sao chép nội dung và lưu ở nơi an toàn.
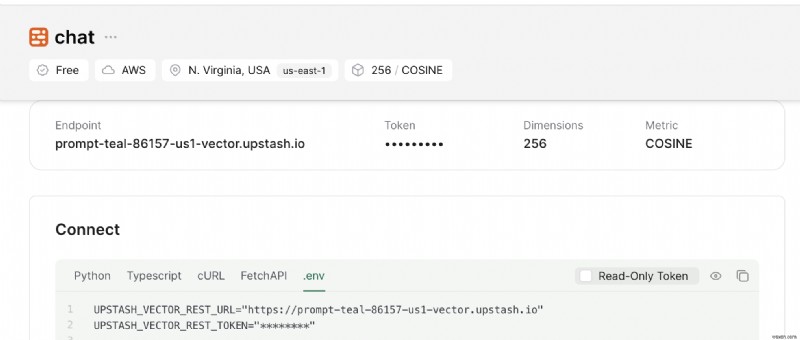
Thiết lập dự án
Để thiết lập, chỉ cần sao chép kho ứng dụng và làm theo hướng dẫn này để tìm hiểu mọi thứ có trong đó. Để phân nhánh dự án, hãy chạy:
git clone https://github.com/rishi-raj-jain/custom-rag-chatbot-upstash-vector
cd custom-rag-chatbot-upstash-vector
pnpm install
Khi bạn đã sao chép kho lưu trữ, bạn sẽ tạo một .env tập tin. Bạn sẽ thêm các mục chúng tôi đã lưu từ các phần trên.
Nó sẽ trông giống như thế này:
# .env
# Obtained from the steps as above
# Upstash Redis URL and Token
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash Vector URL and Token
UPSTASH_VECTOR_REST_URL="https://...-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="..."
# Replicate API Key
REPLICATE_API_TOKEN="r8_..."
# Hugging Face Inference API Key
HUGGINGFACEHUB_API_KEY="hf_..."Sau các bước này, bạn sẽ có thể khởi động môi trường cục bộ bằng lệnh sau:
pnpm devCấu trúc kho lưu trữ
Đây là cấu trúc thư mục chính của dự án. Tôi đã đánh dấu màu đỏ các tệp sẽ được thảo luận thêm trong bài đăng này liên quan đến việc tạo Tuyến API để trò chuyện với AI được đào tạo về ngữ cảnh tùy chỉnh của bạn và cập nhật ngữ cảnh trước upsert -ing vectơ vào chỉ mục hiện có.
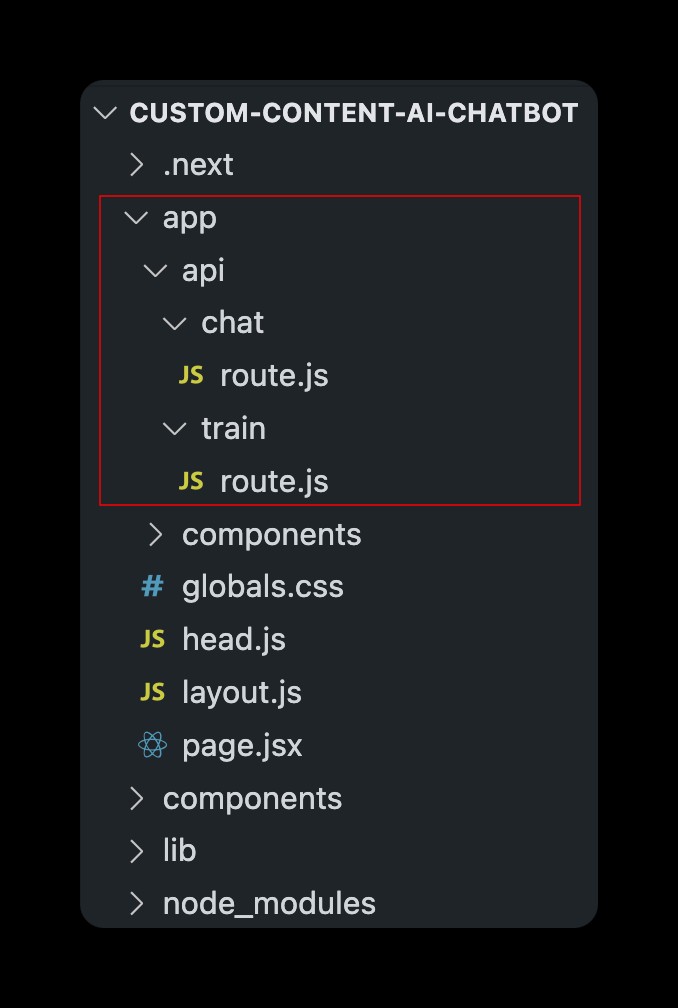
Thiết lập tuyến trò chuyện trong Bộ định tuyến ứng dụng Next.js
Trong phần này, chúng tôi nói về cách thiết lập tuyến đường:app/api/chat/route.js để đồng bộ hóa cuộc hội thoại trong cơ sở dữ liệu không có máy chủ của chúng tôi, tự động tạo các chuỗi nhúng, truy vấn các vectơ có liên quan từ một chỉ mục nhất định để tạo ngữ cảnh và yêu cầu các dự đoán có liên quan bằng mô hình Trò chuyện LLAMA-2-70B. Để đơn giản hóa mọi thứ, chúng tôi sẽ chia phần này thành các phần khác:
Lưu trữ cuộc trò chuyện
Để lưu trữ cuộc trò chuyện diễn ra với Upstash Redis, chúng tôi sẽ sử dụng Danh sách Redis. Ngay sau khi người dùng gửi tin nhắn để phản hồi, chúng tôi sẽ đẩy phản hồi từ chatbot (trước đó) vào danh sách một cách có điều kiện. Sau đó, chúng tôi lưu tin nhắn mới nhất từ người dùng bằng cách đẩy nó vào danh sách và tiến hành phản hồi tin nhắn đó.
// File: app/api/chat/route.js
import { Redis } from '@upstash/redis'
// Instantiate the Upstash Redis
const upstashRedis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
export async function POST(req) {
try {
// the whole chat as array of messages
const { messages } = await req.json()
// assuming user - assistant chat
// add assitant's response to the chat history
if (messages.length > 1) {
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 2]))
}
// add user's request to the chat history
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 1]))
// Proceed to create a response
}Tạo nội dung nhúng cho tin nhắn mới nhất
Để trả lời tin nhắn mới nhất của người dùng một cách hiệu quả trong tất cả ngữ cảnh nhất định (tức là nội dung tùy chỉnh mà người dùng cung cấp), chúng tôi sẽ tạo một phần nhúng sẽ giúp chúng tôi truy xuất ngữ cảnh có liên quan (còn gọi là vectơ tương tự) từ chỉ mục hiện có. Chúng tôi sẽ sử dụng API suy luận ôm khuôn mặt với LangChain để tạo các phần nhúng chỉ bằng một lệnh gọi API ở cạnh và cắt vectơ thu được theo độ dài mà chúng tôi đã định cấu hình trong khi tăng Chỉ số vectơ Upstash (ở đây, 256 ).
// File: app/api/chat/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// ...
// get the latest question stored in the last message of the chat array
const userMessages = messages.filter((i) => i.role === 'user')
const lastMessage = userMessages[userMessages.length - 1].content
// generate embeddings of the latest question
const queryVector = (await embeddings.embedQuery(lastMessage)).slice(0, 256)
// Proceed to create a response
}Truy xuất vectơ ngữ cảnh có liên quan dựa trên thông báo mới nhất
Việc tìm nạp động tất cả ngữ cảnh do người dùng cung cấp cho mỗi tin nhắn là một thao tác tốn kém. Chúng tôi muốn chỉ sử dụng ngữ cảnh liên quan đến tin nhắn mới nhất của người dùng và chuyển nó sang mô hình Trò chuyện LLAMA-2-70B làm lời nhắc hệ thống. Để chỉ tìm nạp ngữ cảnh phù hợp, chúng tôi truy vấn tập hợp vectơ hiện có để thu được 2 vectơ phù hợp nhất bao gồm cả siêu dữ liệu của chúng và lọc kết quả có điểm tin cậy lớn hơn 70%.
// File: app/api/chat/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// query the relevant vectors from the embedding vector
const queryResult = await upstashVectorIndex.query({
vector: queryVector,
// get the top 2 relevant results
topK: 2,
// do not include the whole set of embeddings in the response
includeVectors: false,
// include the meta data so that can get the description out of the index
includeMetadata: true,
})
// console.log('The query result came in', queryResult.length)
// using the resulting set of relevant vectors
// filter the one that have score of greater than 70% match
// and get the description we stored while training
const queryPrompt = queryResult
.filter((match) => match.score && match.score > 0.7)
.map((match) => match.metadata.description)
.join('\n')
// console.log('The query prompt is', queryPrompt)
// Proceed to create a response
}Mô hình trò chuyện LLAMA-2-70B nhắc nhở với ngữ cảnh để dự đoán
Bây giờ chúng ta đã có được ngữ cảnh liên quan dưới dạng một chuỗi, bước cuối cùng là nhắc mô hình trò chuyện llama-2-70B phản hồi tin nhắn mới nhất của người dùng. Chúng tôi sử dụng experimental_buildLlama2Prompt của Vercel AI SDK phương pháp đảm nhiệm việc tạo định dạng lời nhắc phù hợp cho mô hình trò chuyện llama-2-70B.
// File: app/api/chat/route.js
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
import { ReplicateStream, StreamingTextResponse } from 'ai'
// Instantiate the Replicate API
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
})
export async function POST(req) {
try {
// ...
const response = await replicate.predictions.create({
// You must enable streaming.
stream: true,
// The model must support streaming. See https://replicate.com/docs/streaming
// This is the model ID for Llama 2 70b Chat
version: '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt([
{
// create a system content message to be added as
// the llama2prompt generator will supply it as the context with the API
role: 'system',
content: queryPrompt.substring(0, Math.min(queryPrompt.length, 2000)),
},
// also, pass the whole conversation!
...messages,
]),
},
})
// stream the result to the frontend
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}Thiết lập tuyến đường tàu trong bộ định tuyến ứng dụng Next.js
Trong phần này, chúng tôi nói về cách thiết lập tuyến đường:app/api/train/route.js để tự động tạo các phần nhúng của các chuỗi được truyền trong đối tượng yêu cầu và thêm chúng vào Chỉ mục vectơ Upstash. Để đơn giản hóa mọi thứ, chúng tôi sẽ chia phần này thành các phần khác:
Tạo phần nhúng của chuỗi
Chúng tôi sẽ tạo các chuỗi nhúng sẽ giúp chúng tôi thiết lập hoặc cập nhật chỉ mục hiện có. Làm như vậy cho phép chúng tôi cập nhật bối cảnh cho các phản hồi trong tương lai của chatbot. Chúng tôi sẽ sử dụng API suy luận ôm khuôn mặt với LangChain để tạo các phần nhúng chỉ bằng một lệnh gọi API ở biên.
// File: app/api/train/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// a default set of messages to create vector embeddings on
let messagesToVectorize = [
'Rishi is pretty much active on Twitter nowadays.',
'Rishi loves writing for Upstash',
"Rishi's recent article on building chatbot using Upstash went viral",
'Rishi is enjoying building launchfa.st.',
]
// if the POST request is of type application/json
if (req.headers.get('Content-Type') === 'application/json') {
// and if the request contains array of messages to train on
const { messages } = await req.json()
if (typeof messages !== 'string' && messages.length > 0) {
messagesToVectorize = messages
}
}
// Call the Hugging Face Inference API to get emebeddings on the messages
const generatedEmbeddings = await Promise.all(messagesToVectorize.map((i) => embeddings.embedQuery(i)))
// ...
}Lưu trữ vectơ để tìm kiếm mức độ liên quan
Để thêm các phần nhúng được tạo vào chỉ mục vectơ, chúng tôi cắt các vectơ thu được theo độ dài mà chúng tôi đã định cấu hình trong khi tăng Chỉ mục vectơ Upstash (ở đây, 256 ) và sử dụng upsert phương pháp để chèn phần nhúng bằng siêu dữ liệu, tức là chính các chuỗi. Điều này cho phép chúng tôi truy xuất các chuỗi khi tìm kiếm các vectơ tương tự và do đó, thiết lập cơ sở kiến thức của cuộc hội thoại trong khi chúng tôi gọi mô hình Trò chuyện LLAMA-2-70B để tạo phản hồi.
// File: app/api/train/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// Slice the vector into lengths of upto 256
await Promise.all(
generatedEmbeddings
.map((i) => i.slice(0, 256))
.map((vector, index) =>
// Upsert the vector with description to be further as the context to upcoming questions
upstashVectorIndex.upsert({
vector,
id: index.toString(),
metadata: { description: messagesToVectorize[index] },
}),
),
)
// Once done, return with a successful 200 response
return new Response(JSON.stringify({ code: 1 }), { status: 200, headers: { 'Content-Type': 'application/json' } })
}Đó là rất nhiều học hỏi! Bây giờ bạn đã hoàn tất ✨
Triển khai lên Vercel
Kho lưu trữ hiện đã sẵn sàng để triển khai lên Vercel. Hãy làm theo các bước sau để triển khai 👇🏻
- Bắt đầu bằng cách tạo kho lưu trữ GitHub chứa mã ứng dụng của bạn.
- Sau đó, điều hướng tới Trang tổng quan Vercel và tạo Dự án mới .
- Liên kết dự án mới với kho lưu trữ GitHub mà bạn vừa tạo.
- Trong Cài đặt , cập nhật
Environment Variablesđể khớp với những thông tin đó ở địa phương của bạn.envtập tin. - Triển khai! 🚀
Thông tin thêm
Để biết thêm thông tin chi tiết, hãy khám phá các tài liệu tham khảo được trích dẫn trong bài đăng này.
Kết luận
Tóm lại, dự án này đã cung cấp kinh nghiệm quý giá trong việc tìm hiểu cách tạo nội dung nhúng, truy vấn từ tập hợp vectơ hiện có và sử dụng ngữ cảnh để tạo dự đoán có liên quan bằng mô hình Trò chuyện LLAMA-2-70B trong khi sử dụng dịch vụ phù hợp với nhu cầu của bạn, tức là Upstash.