Đối với phân tích dữ liệu, Phân tích Dữ liệu Khám phá (EDA) phải là bước đầu tiên của bạn. Phân tích dữ liệu khám phá giúp chúng tôi -
-
Để cung cấp thông tin chi tiết về tập dữ liệu.
-
Hiểu cấu trúc cơ bản.
-
Trích xuất các tham số và mối quan hệ quan trọng giữ giữa chúng.
-
Kiểm tra các giả định cơ bản.
Hiểu EDA bằng cách sử dụng Tập dữ liệu mẫu
Để hiểu EDA bằng cách sử dụng python, chúng tôi có thể lấy dữ liệu mẫu trực tiếp từ bất kỳ trang web nào hoặc từ đĩa cục bộ của bạn. Tôi đang lấy dữ liệu mẫu từ Kho lưu trữ máy học UCI được cung cấp công khai về biến thể màu đỏ của tập dữ liệu Chất lượng rượu và cố gắng thu thập nhiều thông tin chi tiết về tập dữ liệu bằng EDA.
import pandas as pd
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
df.head() Chạy tập lệnh trên trong sổ ghi chép jupyter, sẽ cho kết quả như bên dưới -
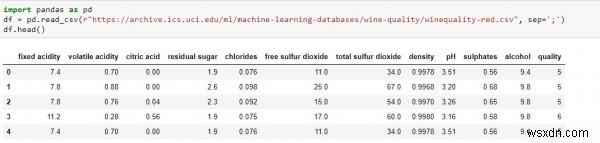
Để bắt đầu,
-
Đầu tiên, nhập thư viện cần thiết, gấu trúc trong trường hợp.
-
Đọc tệp csv bằng cách sử dụng hàm read_csv () của thư viện gấu trúc và mỗi dữ liệu được phân tách bằng dấu phân cách “;” trong tập dữ liệu đã cho.
-
Trả lại năm quan sát đầu tiên từ tập dữ liệu với sự trợ giúp của hàm “.head” do thư viện gấu trúc cung cấp. Tương tự, chúng ta có thể nhận được năm lần quan sát cuối cùng bằng cách sử dụng hàm “.tail ()” của thư viện gấu trúc.
Chúng tôi có thể lấy tổng số hàng và cột từ tập dữ liệu bằng cách sử dụng “.shape” như bên dưới -
df.shape

Để tìm tất cả các cột mà nó chứa, loại nào và chúng có chứa bất kỳ giá trị nào trong đó hay không, với sự trợ giúp của hàm info ().
df.info()
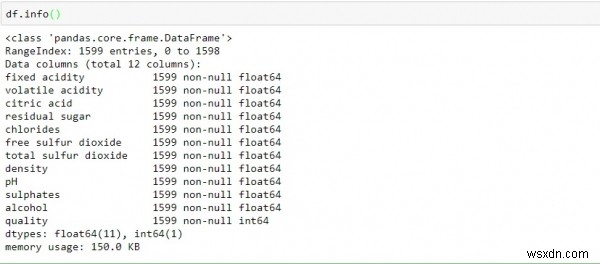
Bằng cách quan sát các dữ liệu trên, chúng ta có thể kết luận -
-
Dữ liệu chứa một giá trị số nguyên chỉ float.
-
Tất cả các biến cột đều không rỗng (không trống hoặc thiếu giá trị).
Một hàm hữu ích khác được cung cấp bởi pandas là description () cung cấp số lượng, giá trị trung bình, độ lệch chuẩn, giá trị tối thiểu và tối đa cũng như số lượng dữ liệu.
df.describe()
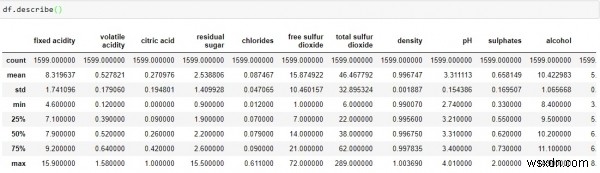
-
Từ dữ liệu trên, chúng tôi có thể kết luận rằng giá trị trung bình của mỗi cột nhỏ hơn giá trị trung bình (50%) trong cột chỉ mục.
-
Có sự khác biệt rất lớn giữa giá trị 75% và giá trị tối đa của các yếu tố dự đoán “đường dư”, “lưu huỳnh điôxít tự do” và “tổng lưu huỳnh điôxít”.
-
Hai quan sát trên đưa ra dấu hiệu rằng có những giá trị - độ lệch cực lớn trong tập dữ liệu của chúng tôi.
Các cặp thông tin chi tiết chính mà chúng ta có thể nhận được từ các biến phụ thuộc như sau -
df.quality.unique()

-
Trong thang điểm "chất lượng", 1 đứng cuối. i.e. kém và 10 đứng đầu. i.e. tốt nhất.
-
Từ trên chúng ta có thể kết luận, không có điểm quan sát nào 1 (kém), 2 và 9, 10 (tốt nhất). Tất cả các điểm đều từ 3 đến 8.
df.quality.value_counts()
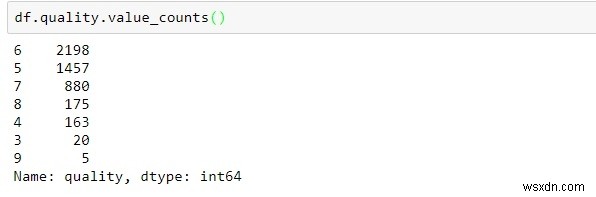
-
Dữ liệu được xử lý ở trên cung cấp thông tin về số phiếu bầu cho từng điểm chất lượng theo thứ tự giảm dần.
-
Hầu hết chất lượng nằm trong khoảng 5-7.
-
Các quan sát ít nhất được quan sát trong loại 3 và 6.
Hình ảnh hóa dữ liệu
Để kiểm tra các giá trị còn thiếu -
Chúng tôi có thể kiểm tra các giá trị còn thiếu trong tập dữ liệu csv rượu whisky trắng của mình với sự trợ giúp của thư viện seaborn. Dưới đây là mã để fullfil -
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set()
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep=";")
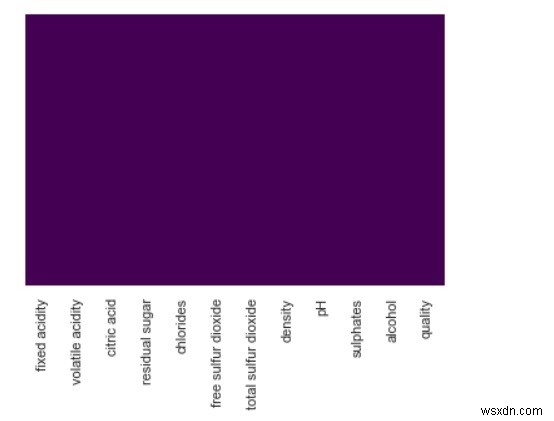
sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis') Đầu ra
-
Từ phía trên, chúng ta có thể thấy không có giá trị nào bị thiếu trong tập dữ liệu. Nếu có, chúng ta sẽ thấy hình được thể hiện bằng các bóng màu khác nhau trên nền màu tím.
-
Với các tập dữ liệu khác nhau, nơi có các giá trị bị thiếu và bạn sẽ nhận thấy sự khác biệt.
Để kiểm tra mối tương quan
Để kiểm tra mối tương quan giữa các giá trị khác nhau của tập dữ liệu, hãy chèn mã bên dưới vào tập dữ liệu hiện có của chúng tôi -
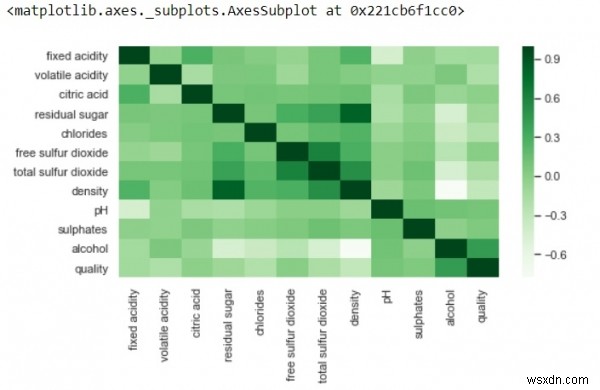
plt.figure(figsize=(8,4)) sns.heatmap(df.corr(),cmap='Greens',annot=False)
Đầu ra
-
Ở trên, mối tương quan tích cực được thể hiện bằng các sắc thái tối và tương quan tiêu cực bằng các sắc thái nhạt hơn.
-
Thay đổi giá trị của annot =True và kết quả sẽ hiển thị cho bạn các giá trị mà các đối tượng địa lý tương quan với nhau trong ô lưới.
Chúng ta có thể tạo một ma trận tương quan khác với annot =True. Sửa đổi mã của bạn bằng cách thêm các dòng mã bên dưới vào mã hiện có của chúng tôi -
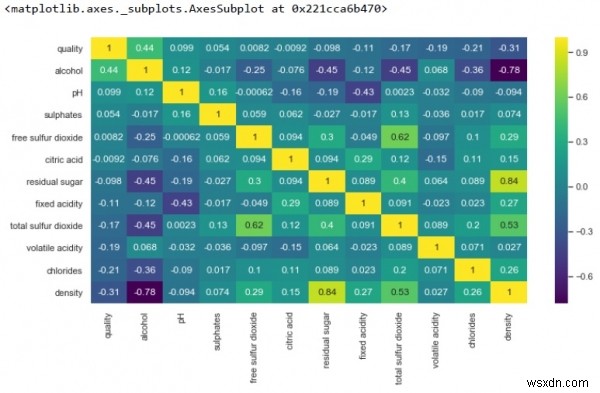
k = 12 cols = df.corr().nlargest(k, 'quality')['quality'].index cm = df[cols].corr() plt.figure(figsize=(8,6)) sns.heatmap(cm, annot=True, cmap = 'viridis')
Đầu ra
-
Từ trên chúng ta có thể thấy, có một mối tương quan thuận chặt chẽ của tỷ trọng với lượng đường còn lại. Tuy nhiên, tỷ trọng và rượu có mối tương quan tiêu cực mạnh mẽ.
-
Ngoài ra, không có mối tương quan giữa sulfur dioxide tự do và chất lượng.