Pandas là một trong những thư viện python phổ biến nhất dành cho khoa học dữ liệu và phân tích. Thư viện Pandas được sử dụng để thao tác, phân tích và làm sạch dữ liệu. Nó là một phần trừu tượng cấp cao so với NumPy cấp thấp được viết hoàn toàn bằng C. Trong phần này, chúng tôi sẽ đề cập đến một số điều quan trọng nhất (thường được sử dụng nhất) mà chúng ta cần biết với tư cách là một anayst hoặc một nhà khoa học dữ liệu.
Cài đặt thư viện
Chúng tôi có thể cài đặt các thư viện cần thiết bằng cách sử dụng pip, chỉ cần chạy lệnh dưới đây trên thiết bị đầu cuối lệnh của bạn:
gấu trúcpip intall
DataFrame và Series
Đầu tiên chúng ta cần hiểu hai cấu trúc dữ liệu cơ bản chính của gấu trúc .i.e. DataFrame và Series. Chúng ta cần có hiểu biết vững chắc về hai cấu trúc dữ liệu này để có thể thông thạo gấu trúc.
Sê-ri
Chuỗi là một đối tượng tương tự như danh sách kiểu tích hợp sẵn trong python nhưng khác với nó vì nó có lable được liên kết với từng phần tử hoặc chỉ mục.
>>> nhập gấu trúc dưới dạng pd>>> my_series =pd.Series ([12, 24, 36, 48, 60, 72, 84])>>> my_series0 121 242 363 484 605 726 84dtype:int64Trong đầu ra ở trên, ‘chỉ mục’ ở bên trái và ‘giá trị’ ở bên phải. Ngoài ra, mỗi đối tượng Dòng có kiểu dữ liệu (dtype), trong trường hợp của chúng tôi là int64.
Chúng tôi có thể truy xuất các phần tử theo số chỉ mục của chúng:
>>> my_series [6] 84Để cung cấp tính rõ ràng của chỉ mục (nhãn), hãy sử dụng:
>>> my_series =pd.Series ([12, 24, 36, 48, 60, 72, 84], index =['ind0', 'ind1', 'ind2', 'ind3', 'ind4' , 'ind5', 'ind6'])>>> my_seriesind0 12ind1 24ind2 36ind3 48ind4 60ind5 72ind6 84dtype:int64Ngoài ra, rất dễ dàng truy xuất một số phần tử theo chỉ mục của chúng hoặc thực hiện gán nhóm:
>>> my_series [['ind0', 'ind3', 'ind6']] ind0 12ind3 48ind6 84dtype:int64>>> my_series [['ind0', 'ind3', 'ind6']] =36>>> my_seriesind0 36ind1 24ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64Thao tác lọc và toán học cũng dễ dàng:
>>> my_series [my_series> 24] ind0 36ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64>>> my_series [my_series <24] * 2Series ([], dtype:int64)>>> my_seriesind0 36ind1 24ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64>>>Dưới đây là một số thao tác phổ biến khác trên Chuỗi.
>>> #Work as Dictionary>>> my_series1 =pd.Series ({'a':9, 'b':18, 'c':27, 'd':36})>>> my_series1a 9b 18c 27d 36dtype:int64>>> #Label thuộc tính>>> my_series1.name ='Numbers'>>> my_series1.index.name ='letter'>>> my_series1lettersa 9b 18c 27d 36Name:Numbers, dtype:int64>>> #chaning Index>>> my_series1.index =['w', 'x', 'y', 'z']>>> my_series1w 9x 18y 27z 36Name:Numbers, dtype:int64>>>DataFrame
DataFrame hoạt động giống như một bảng vì nó chứa các hàng và cột. Mỗi cột trong DataFrame là một đối tượng Chuỗi và các hàng bao gồm các phần tử bên trong Chuỗi.
DataFrame có thể được xây dựng bằng cách sử dụng các phiên bản Python tích hợp:
>>> df =pd.DataFrame ({'Quốc gia':['Trung Quốc', 'Ấn Độ', 'Indonesia', 'Pakistan'], 'Dân số':[1420062022, 1368737513, 269536482, 204596442], ' Khu vực ':[9388211, 2973190, 1811570, 770880]})>>> df Khu vực Quốc gia Dân số0 9388211 Trung Quốc 14200620221 2973190 Ấn Độ 13687375132 1811570 Indonesia 2695364823 770880 Pakistan 204596442>>> df [' Country '] 0 China1 India2 Indonesia3 PakistanTên:Quốc gia, dtype:object>>> df.columnsIndex (['Khu vực', 'Quốc gia', 'Dân số'], dtype ='object')>>> df.indexRangeIndex (start =0, stop =4, step =1)>>>Truy cập các phần tử
Có một số cách để cung cấp chỉ mục hàng một cách rõ ràng.
>>> df =pd.DataFrame ({'Quốc gia':['Trung Quốc', 'Ấn Độ', 'Indonesia', 'Pakistan'], 'Dân số':[1420062022, 1368737513, 269536482, 204596442], ' Landarea ':[9388211, 2973190, 1811570, 770880]}, index =[' CHA ',' IND ',' IDO ',' PAK '])>>> df Quốc gia Landarea dân sốCHA Trung Quốc 9388211 1420062022IND Ấn Độ 2973190 1368737513IDO Indonesia 1811570 269536482PAK Pakistan 770880 204596442>>> df.index =['CHI', 'IND', 'IDO', 'PAK']>>> df.index.name ='Mã quốc gia'>>> df Quốc gia Landarea Dân số Mã quốc gia CHI Trung Quốc 9388211 1420062022IND Ấn Độ 2973190 1368737513IDO Indonesia 1811570 269536482PAK Pakistan 770880 204596442>>> df ['Country'] Country CodeCHI ChinaIND IndiaIDO IndonesiaPAK PakistanTên:Quốc gia, loại:đối tượngTruy cập hàng bằng cách sử dụng chỉ mục có thể được thực hiện theo một số cách
- Sử dụng .loc và cung cấp nhãn chỉ mục
- Sử dụng .iloc và cung cấp số chỉ mục
>>> df.loc ['IND'] Country IndiaLandarea 2973190Population 1368737513Name:IND, dtype:object>>> df.iloc [1] Country IndiaLandarea 2973190Population 1368737513Name:IND, dtype:object>>>>>> df .loc [['CHI', 'IND'], 'Dân số'] Mã quốc giaCHI 1420062022IND 1368737513Tên:Dân số, loại:int64
Đọc và ghi tệp
Pandas hỗ trợ nhiều định dạng tệp phổ biến bao gồm CSV, XML, HTML, Excel, SQL, JSON và nhiều định dạng khác. Định dạng tệp CSV phổ biến nhất được sử dụng.
Để đọc tệp csv, chỉ cần chạy:
>>> df =pd.read_csv ('GDP.csv', sep =',') Đối số được đặt tên sep trỏ đến một ký tự phân tách trong tệp CSV được gọi là GDP.csv.
Tổng hợp và nhóm
Để nhóm dữ liệu trong gấu trúc, chúng ta có thể sử dụng phương pháp .groupby. Để chứng minh việc sử dụng tổng hợp và phân nhóm ở gấu trúc, tôi đã sử dụng bộ dữ liệu Titanic, bạn có thể tìm thấy bộ dữ liệu tương tự từ liên kết dưới đây:
https://yadi.sk/d/TfhJdE2k3EyALt
>>> titanic_df =pd.read_csv ('titanic.csv')>>> print (titanic_df.head ()) PassengerID Name PClass Age \ 0 1 Allen, Miss Elisabeth Walton 1st 29.001 2 Allison, Miss Helen Loraine 1st 2.002 3 Allison, Mr Hudson Joshua Creighton 1st 30.003 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.004 5 Allison, Master Hudson Trevor 1st 0.92 Sex Survived SexCode0 nữ 1 11 nữ 0 12 nam 0 03 nữ 0 14 nam 1 0>>> Hãy tính xem có bao nhiêu hành khách (phụ nữ và nam giới) sống sót và bao nhiêu hành khách không sống sót, chúng tôi sẽ sử dụng .groupby
>>> print (titanic_df.groupby (['Sex', 'Survived']) ['PassengerID']. count ()) Sex Survivedfemale 0 154 1 308male 0 709 1 142Name:PassengerID, dtype:int64Dữ liệu trên dựa trên hạng cabin:
>>> print (titanic_df.groupby (['PClass', 'Survived']) ['PassengerID']. count ()) PClass Survived * 0 11st 0 129 1 1932nd 0 160 1 1193rd 0 573 1 138Tên:PassengerID, loại dtype:int64Phân tích chuỗi thời gian bằng gấu trúc
Gấu trúc được tạo ra để phân tích dữ liệu chuỗi thời gian. Để minh họa, tôi đã sử dụng giá chứng khoán 5 năm của amazon. Bạn có thể tải xuống từ liên kết dưới đây,
https://finance.yahoo.com/quote/AMZN/history?period1=1397413800&period2=1555180200&interval=1mo&filter=history&frequency=1mo
>>> nhập gấu trúc dưới dạng pd>>> amzn_df =pd.read_csv ('AMZN.csv', index_col ='Date', parse_dates =True)>>> amzn_df =amzn_df.sort_index ()>>> print ( amzn_df.info ())DatetimeIndex:62 mục nhập, 2014-04-01 đến 2019-04-12 Cột dữ liệu (tổng số 6 cột):Mở 62 đối tượng không rỗngCao 62 không null objectLow 62 non-null object Đóng 62 non-null objectAdj Close 62 non-null objectDtypes:object (6) memory use:1,9+ KBNone Ở trên, chúng tôi đã tạo một DataFRame với cột DatetimeIndex theo ngày và sau đó sắp xếp nó.
Và giá đóng cửa trung bình là,
>>> amzn_df.loc ['2015-04', 'Close']. mean () 421.779999Hình ảnh hóa
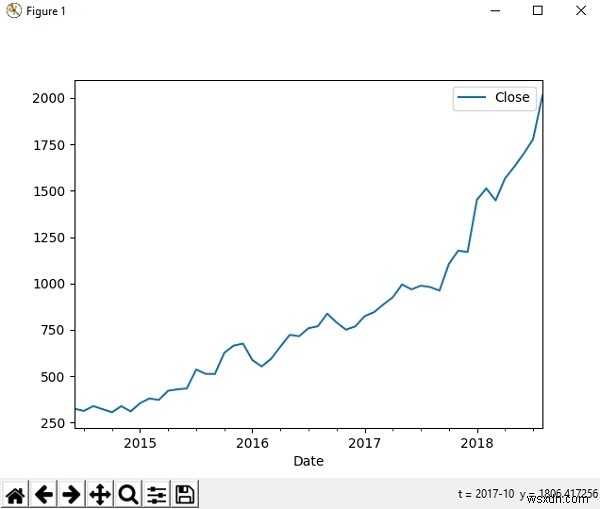
Chúng ta có thể sử dụng thư viện matplotlib để hình dung gấu trúc. Hãy xem tập dữ liệu lịch sử chứng khoán amazon của chúng tôi và xem xét biến động giá của nó trong khoảng thời gian cụ thể qua biểu đồ.
>>> nhập matplotlib.pyplot dưới dạng plt>>> df =pd.read_csv ('AMZN.csv', index_col ='Date', parse_dates =True)>>> new_df =df.loc ['2014-06 ':' 2018-08 ', [' Close ']]>>> new_df =new_df.astype (float)>>> new_df.plot ()>>> plt. show ()