Python cung cấp nhiều thư viện để phân tích và trực quan hóa dữ liệu, chủ yếu là numpy, pandas, matplotlib, seaborn, v.v. Trong phần này, chúng ta sẽ thảo luận về thư viện gấu trúc để phân tích và trực quan hóa dữ liệu, đây là một thư viện mã nguồn mở được xây dựng dựa trên numpy.
Nó cho phép chúng tôi thực hiện phân tích nhanh chóng và làm sạch và chuẩn bị dữ liệu.
Cài đặt
Để cài đặt gấu trúc, hãy chạy lệnh dưới đây trong thiết bị đầu cuối của bạn -
gấu trúcpipinstall pandas
Hoặc chúng tôi có anaconda, bạn có thể sử dụng
condainstall pandas
Pandas-DataFrames
Khung dữ liệu là công cụ chính khi chúng tôi làm việc với gấu trúc.
mã -
import numpy as np import pandas as pd from numpy.random import randn np.random.seed(50) df = pd.DataFrame(randn(6,4), ['a','b','c','d','e','f'],['w','x','y','z']) df
Đầu ra
| | w | x | y | z |
|---|---|---|---|---|
| a | - 1.560352 | - 0,030978 | - 0,620928 | - 1,464580 |
| b | 1.411946 | - 0,476732 | - 0,780469 | 1.070268 |
| c | - 1.282293 | - 1.327479 | 0,126338 | 0,862194 |
| d | 0,696737 | - 0,334565 | - 0,997526 | 1.598908 |
| e | 3.314075 | 0,987770 | 0,123866 | 0,742785 |
| f | - 0,393956 | 0,148116 | - 0,412234 | - 0,160715 |
Dữ liệu bị thiếu trên gấu trúc
Weare sẽ thấy một số cách thuận tiện để đối phó với những con inpandas bị thiếu dữ liệu, chúng tự động được lấp đầy bằng số 0 hoặc nan.
import numpy as np
import pandas as pd
from numpy.random import randn
d = {'A': [1,2,np.nan], 'B': [9, np.nan, np.nan], 'C': [1,4,9]}
df = pd.DataFrame(d)
df Đầu ra
| | A | B | C |
|---|---|---|---|
| 0 | 1,0 | 9.0 | 1 |
| 1 | 2.0 | NaN | 4 |
| 2 | NaN | NaN | 9 |
Vì vậy, chúng tôi đang thiếu 3 giá trị ở trên.
df.dropna()
| | A | B | C |
|---|---|---|---|
| 0 | 1,0 | 9.0 | 1 |
df.dropna(axis = 1)
| | C |
|---|---|
| 0 | 1 |
| 1 | 4 |
| 2 | 9 |
df.dropna(thresh = 2)
| | A | B | C |
|---|---|---|---|
| 0 | 1,0 | 9,0 | 1 |
| 1 | 2.0 | NaN | 4 |
df.fillna(value = df.mean())
| | A | B | C |
|---|---|---|---|
| 0 | 1,0 | 9.0 | 1 |
| 1 | 2.0 | 9.0 | 4 |
| 2 | 1,5 | 9.0 | 9 |
Gấu trúc - Nhập dữ liệu
Chúng tôi sẽ đọc tệp csv được lưu trữ trong máy cục bộ của chúng tôi (trong trường hợp của tôi) hoặc chúng tôi có thể tìm nạp trực tiếp từ web.
#import pandas library
import pandas as pd
#Read csv file and assigned it to dataframe variable
df = pd.read_csv("SYB61_T03_Population Growth Rates in Urban areas and Capital cities.csv",encoding = "ISO-8859-1")
#Read first five element from the dataframe
df.head() Đầu ra
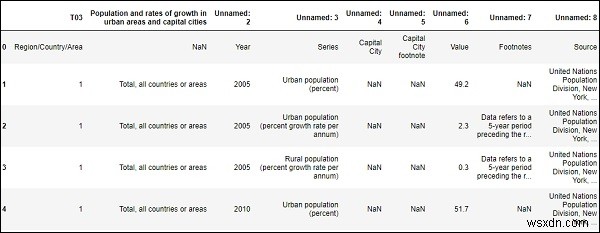
Thêm số lượng hàng và cột trong khung dữ liệu hoặc tệp csv của chúng tôi.
#Countthe number of rows and columns in our dataframe. df.shape
Đầu ra
(4166,9)
Gấu trúc - Toán khung dữ liệu
Các khung dữ liệu hoạt động có thể được thực hiện bằng cách sử dụng các công cụ thống kê dữ liệu khác nhau của gấu trúc
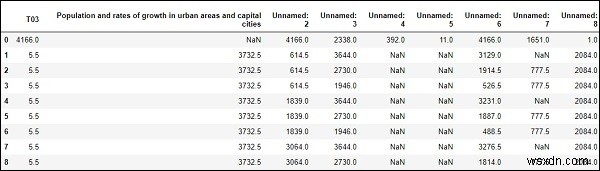
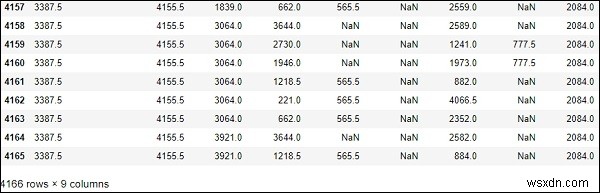
#To computes various summary statistics, excluding NaN values df.describe()
Đầu ra

# computes numerical data ranks df.rank()
Đầu ra
.....
.....
Gấu trúc - đồ thị biểu đồ
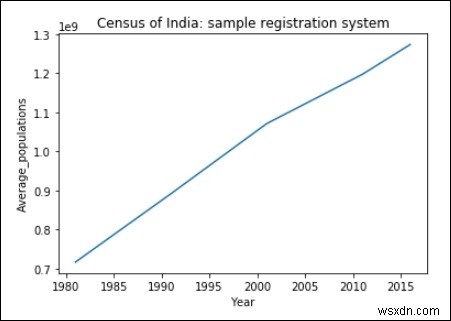
import matplotlib.pyplot as plt
years = [1981, 1991, 2001, 2011, 2016]
Average_populations = [716493000, 891910000, 1071374000, 1197658000, 1273986000]
plt.plot(years, Average_populations)
plt.title("Census of India: sample registration system")
plt.xlabel("Year")
plt.ylabel("Average_populations")
plt.show() Đầu ra
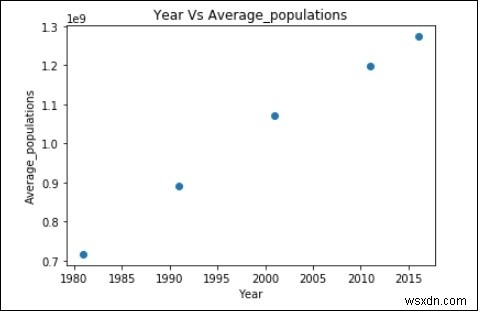
Biểu đồ phân tán của dữ liệu trên:
plt.scatter(years,Average_populations)
Biểu đồ:
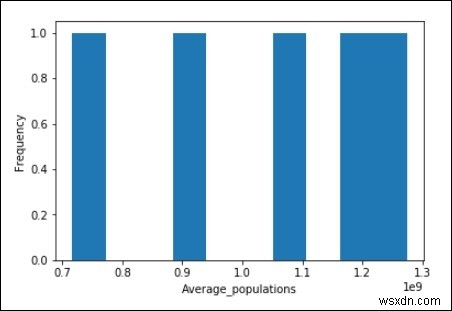
import matplotlib.pyplot as plt
Average_populations = [716493000, 891910000, 1071374000, 1197658000, 1273986000]
plt.hist(Average_populations, bins = 10)
plt.xlabel("Average_populations")
plt.ylabel("Frequency")
plt.show() Đầu ra