Thống kê là cơ bản để học ml và AI. Vì Python là ngôn ngữ được lựa chọn cho các Công nghệ này, chúng ta sẽ xem cách viết các chương trình Python kết hợp phân tích thống kê. Trong bài viết này, chúng ta sẽ xem cách tạo đồ thị và biểu đồ bằng cách sử dụng các mô-đun Python khác nhau. Sự đa dạng của các biểu đồ này giúp chúng tôi phân tích dữ liệu một cách nhanh chóng và đưa ra các kết luận bên trong là các kết luận bằng đồ thị.
Chuẩn bị dữ liệu
Chúng tôi lấy tập dữ liệu chứa dữ liệu về các loại hạt giống khác nhau. Tập dữ liệu này có sẵn tại kaggle trong liên kết hiển thị trong chương trình bên dưới. Nó có tám cột sẽ được sử dụng để kết thúc các loại biểu đồ khác nhau để so sánh các tính năng của các hạt giống khác nhau. Chương trình bên dưới tải tập dữ liệu từ môi trường cục bộ và hiển thị một mẫu hàng.
Ví dụ
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
datainput = pd.read_csv('E:\\seeds.csv')
#https://www.kaggle.com/jmcaro/wheat-seedsuci
print(datainput) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
Area Perimeter Compactness ... Asymmetry.Coeff Kernel.Groove Type 0 15.26 14.84 0.8710 ... 2.221 5.220 1 1 14.88 14.57 0.8811 ... 1.018 4.956 1 2 14.29 14.09 0.9050 ... 2.699 4.825 1 3 13.84 13.94 0.8955 ... 2.259 4.805 1 4 16.14 14.99 0.9034 ... 1.355 5.175 1 .. ... ... ... ... ... ... ... 194 12.19 13.20 0.8783 ... 3.631 4.870 3 195 11.23 12.88 0.8511 ... 4.325 5.003 3 196 13.20 13.66 0.8883 ... 8.315 5.056 3 197 11.84 13.21 0.8521 ... 3.598 5.044 3 198 12.30 13.34 0.8684 ... 5.637 5.063 3 [199 rows x 8 columns]
Tạo biểu đồ
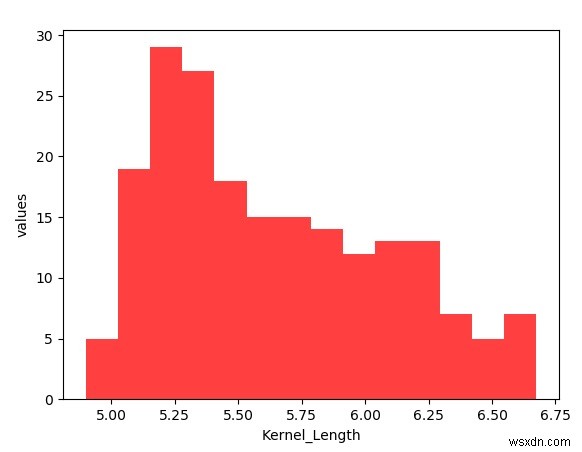
Để tạo biểu đồ, chúng tôi xóa hàng tiêu đề khỏi tệp csv và đọc tệp dưới dạng một mảng numpy. Sau đó, chúng tôi sử dụng mô-đun genfromtxt để đọc tệp. Chiều dài hạt nhân được đặt dưới dạng chỉ số cột 3 trong mảng. Cuối cùng, chúng tôi sử dụng matplotlib để vẽ biểu đồ bằng cách sử dụng tập dữ liệu được tạo bởi numpy và cũng áp dụng các nhãn được yêu cầu.
Ví dụ
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_Length = seed_data[:, [3]]
x = len(Kernel_Length)
y = np.sqrt(x)
y = int(y)
z = plot.hist(Kernel_Length, bins=y, color='#FF4040')
z = plot.xlabel('Kernel_Length')
z = plot.ylabel('values')
plot.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
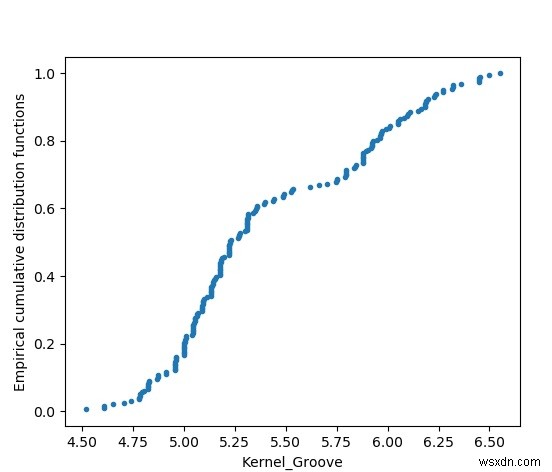
Các hàm phân phối tích lũy theo kinh nghiệm
Biểu đồ này cho thấy biểu đồ của kích thước rãnh hạt nhân được phân bổ trên tập dữ liệu. Nó được sắp xếp từ giá trị nhỏ nhất đến giá trị lớn nhất và nó được hiển thị dưới dạng phân phối.
Ví dụ
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_groove = seed_data[:, 6]
def ECDF(seed_data):#Empirical cumulative distribution functions
i = len(seed_data)
m = np.sort(seed_data)
n = np.arange(1, i + 1) / i
return m, n
m, n = ECDF(Kernel_groove)
plot.plot(m, n, marker='.', linestyle='none')
plot.xlabel('Kernel_Groove')
plot.ylabel('Empirical cumulative distribution functions')
plot.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
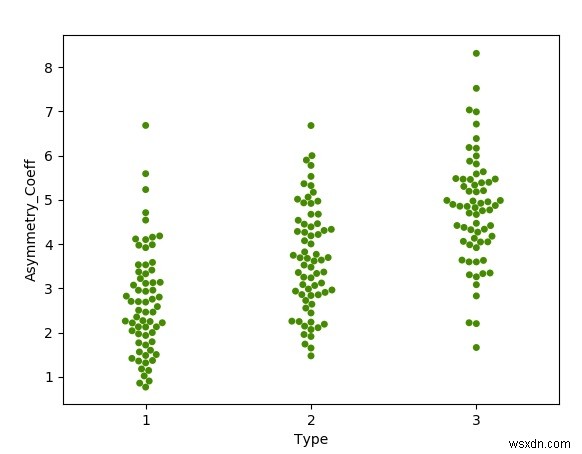
Ô bầy ong
Biểu đồ ấm áp cho thấy kích thước của một nhóm các điểm dữ liệu bằng cách phân cụm trực quan từng điểm dữ liệu riêng lẻ. Chúng tôi sử dụng thư viện seaborn để tạo biểu đồ này. Chúng tôi sử dụng cột Loại từ tập dữ liệu để nhóm các hạt giống loại tương tự lại với nhau.
Ví dụ
import pandas as pd
import matplotlib.pyplot as plot
import seaborn as sns
datainput = pd.read_csv('E:\\seeds.csv')
sns.swarmplot(x='Type', y='Asymmetry.Coeff',data=datainput, color='#458B00')#bee swarm plot
plot.xlabel('Type')
plot.ylabel('Asymmetry_Coeff')
plot.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -