Mọi doanh nghiệp đều phụ thuộc vào lòng trung thành của khách hàng. Kinh doanh lặp lại từ khách hàng là một trong những nền tảng cho lợi nhuận kinh doanh. Vì vậy điều quan trọng là phải biết lý do của khách hàng rời bỏ một doanh nghiệp. Khách hàng bỏ đi được gọi là khách hàng churn. Bằng cách xem xét các xu hướng trong quá khứ, chúng ta có thể đánh giá những yếu tố nào ảnh hưởng đến sự rời bỏ của khách hàng và cách dự đoán liệu một khách hàng cụ thể có rời bỏ doanh nghiệp hay không. Trong bài viết này, chúng tôi sẽ sử dụng thuật toán ML để nghiên cứu các xu hướng trong quá khứ của khách hàng và sau đó đánh giá khách hàng nào có khả năng bỏ cuộc.
Chuẩn bị dữ liệu
Như một ví dụ sẽ xem xét sự churn của khách hàng Viễn thông trong bài viết này. Dữ liệu nguồn có sẵn tại kaggel. URL để tải xuống dữ liệu được đề cập trong chương trình dưới đây. Chúng tôi sử dụng thư viện Pandas để tải tệp csv vào chương trình Python và xem xét một số hàng mẫu.
Ví dụ
import pandas as pd
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\\Telecom_customers.csv')
print("Given input data :\n",datainput) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
Given input data : customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG Female 0 ... 29.85 29.85 No 1 5575-GNVDE Male 0 ... 56.95 1889.5 No 2 3668-QPYBK Male 0 ... 53.85 108.15 Yes 3 7795-CFOCW Male 0 ... 42.30 1840.75 No 4 9237-HQITU Female 0 ... 70.70 151.65 Yes ... ... ... ... ... ... ... ... 7038 6840-RESVB Male 0 ... 84.80 1990.5 No 7039 2234-XADUH Female 0 ... 103.20 7362.9 No 7040 4801-JZAZL Female 0 ... 29.60 346.45 No 7041 8361-LTMKD Male 1 ... 74.40 306.6 Yes 7042 3186-AJIEK Male 0 ... 105.65 6844.5 No [7043 rows x 21 columns]
Nghiên cứu mẫu hiện có
Tiếp theo, chúng tôi nghiên cứu tập dữ liệu để tìm các mẫu hiện có về thời điểm chuỗi xảy ra. Chúng tôi cũng loại bỏ một số cột khỏi người bạn dữ liệu mà không ảnh hưởng đến điều kiện. Ví dụ:cột ID khách hàng sẽ không có tác động đến việc liệu khách hàng có rời đi hay không, vì vậy chúng tôi loại bỏ các cột như vậy bằng cách sử dụng phương pháp thả tất cả các cửa sổ bật lên. Sau đó, chúng tôi vẽ biểu đồ hiển thị phần trăm cơ hội trong tập dữ liệu đã cho.
Ví dụ 2
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\\Telecom_customers.csv')
print("Given input data :\n",datainput)
#Dropping columns
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
data = datainput['Churn'].value_counts(sort = True)
chroma = ["#BDFCC9","#FFDEAD"]
rcParams['figure.figsize'] = 9,9
explode = [0.2,0.2]
plt.pie(data, explode=explode, colors=chroma, autopct='%1.1f%%', shadow=True, startangle=180,)
plt.title('Percentage of Churn in the given Data')
plt.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
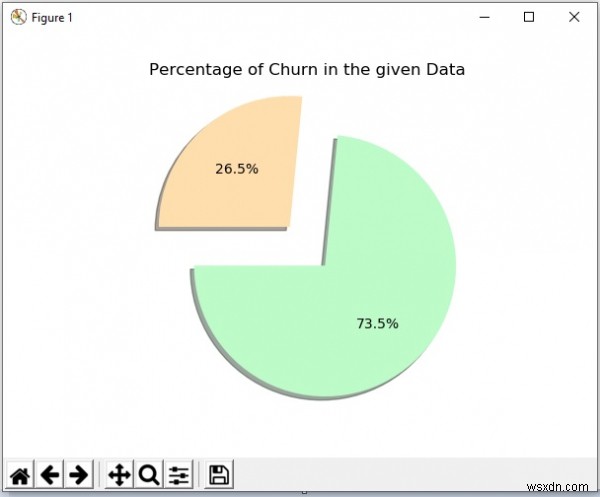
Xử lý trước dữ liệu
Để làm cho dữ liệu sẵn sàng được sử dụng bởi các thuật toán ML, chúng tôi gắn nhãn tất cả các trường. Chúng tôi cũng chuyển đổi các giá trị văn bản thành cờ số. Ví dụ:các giá trị trong cột giới tính thay đổi thành 0 và 1 thay vì nam và nữ. Điều này giúp sử dụng các trường đó trong các tính toán và thuật toán sẽ đánh giá tác động của các trường này lên giá trị churn. Chúng tôi sử dụng phương pháp LabelEncoder từ sklearn.
Ví dụ 3
import pandas as pd
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
print("\nseparated X and y :")
print("y -",y)
print("X -",X) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
Dữ liệu đầu vàoinput data after label encoder customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG 0 0 ... 29.85 29.85 0 1 5575-GNVDE 1 0 ... 56.95 1889.5 0 2 3668-QPYBK 1 0 ... 53.85 108.15 1 3 7795-CFOCW 1 0 ... 42.30 1840.75 0 4 9237-HQITU 0 0 ... 70.70 151.65 1 ... ... ... ... ... ... ... ... 7038 6840-RESVB 1 0 ... 84.80 1990.5 0 7039 2234-XADUH 0 0 ... 103.20 7362.9 0 7040 4801-JZAZL 0 0 ... 29.60 346.45 0 7041 8361-LTMKD 1 1 ... 74.40 306.6 1 7042 3186-AJIEK 1 0 ... 105.65 6844.5 0 [7043 rows x 21 columns] separated X and y : y - [0 0 1 ... 0 1 0] X - customerID gender ... MonthlyCharges TotalCharges 0 7590-VHVEG 0 ... 29.85 29.85 1 5575-GNVDE 1 ... 56.95 1889.5 2 3668-QPYBK 1 ... 53.85 108.15 3 7795-CFOCW 1 ... 42.30 1840.75 4 9237-HQITU 0 ... 70.70 151.65 ... ... ... ... ... ... 7038 6840-RESVB 1 ... 84.80 1990.5 7039 2234-XADUH 0 ... 103.20 7362.9 7040 4801-JZAZL 0 ... 29.60 346.45 7041 8361-LTMKD 1 ... 74.40 306.6 7042 3186-AJIEK 1 ... 105.65 6844.5 [7043 rows x 20 columns]
Đào tạo và kiểm tra dữ liệu
Bây giờ chúng ta chia tập dữ liệu thành hai phần. Một là để đào tạo và một là để thử nghiệm. Tham số test_size được sử dụng để quyết định phần trăm tập dữ liệu sẽ chỉ được sử dụng để thử nghiệm. Bài tập này sẽ giúp chúng tôi có được sự tự tin về mô hình mà chúng tôi đang tạo ra. Sau đó, chúng tôi áp dụng thuật toán hồi quy logistic và tìm ra các giá trị được dự đoán.
Ví dụ
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
print("\npredicted values :\n",Y_pred) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
predicted values : [0 0 1 ... 0 1 0]
Tìm các tham số đánh giá
Khi mức độ chính xác ở bước trên có thể chấp nhận được, chúng tôi tiếp tục đánh giá thêm mô hình bằng cách tìm ra các tham số khác nhau. Chúng tôi sử dụng ma trận Độ chính xác và nhầm lẫn làm tham số để đánh giá mức độ chính xác của mô hình này. Giá trị phần trăm độ chính xác cao hơn cho thấy mô hình phù hợp hơn. Tương tự như vậy, ma trận nhầm lẫn hiển thị một ma trận gồm dương tính đúng, phủ định đúng, dương tính giả và phủ định sai. Tỷ lệ phần trăm giá trị đúng cao hơn so với giá trị sai là dấu hiệu của mô hình tốt hơn.
Ví dụ
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.metrics import confusion_matrix
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#Accuracy
LR = metrics.accuracy_score(Y_test, Y_pred) * 100
print("\nThe accuracy score using the LR is -> ",LR)
#confusion matrix
cm=confusion_matrix(Y_test,Y_pred)
print("\nconfusion matrix : \n",cm) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
The accuracy score using the LR is -> 80.8374733853797 confusion matrix : [[928 109] [161 211]]
Trọng số của các biến
Tiếp theo, chúng tôi đánh giá mỗi trường hoặc biến ảnh hưởng như thế nào đến giá trị churn. Điều này sẽ giúp chúng tôi nhắm mục tiêu các biến cụ thể sẽ có tác động lớn hơn đến thời gian chờ và cố gắng xử lý các biến đó để ngăn chặn tình trạng khách hàng bỏ trốn.>
Ví dụ
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#weights of all the variables
wt = pd.Series(classifier.coef_[0], index=X.columns.values)
print("\nweight of all the variables :")
print(wt.sort_values(ascending=False)) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
weight of all the variables : PaperlessBilling 0.389379 SeniorCitizen 0.246504 InternetService 0.209283 Partner 0.067855 StreamingMovies 0.054309 MultipleLines 0.042330 PaymentMethod 0.039134 MonthlyCharges 0.027180 StreamingTV -0.008606 gender -0.029547 tenure -0.034668 DeviceProtection -0.052690 OnlineBackup -0.143625 Dependents -0.209667 OnlineSecurity -0.245952 TechSupport -0.254740 Contract -0.729557 PhoneService -0.950555 dtype: float64