Điều tra dân số là việc ghi lại thông tin về một nhóm dân số nhất định một cách có hệ thống. Dữ liệu thu thập được bao gồm nhiều loại thông tin khác nhau như - thông tin chi tiết về nhân khẩu học, kinh tế, môi trường sống, v.v. Điều này cuối cùng giúp chính phủ hiểu được kịch bản hiện tại cũng như lập kế hoạch cho tương lai. Trong bài viết này, chúng ta sẽ xem cách tận dụng python để phân tích dữ liệu điều tra dân số Ấn Độ. Chúng ta sẽ xem xét các khía cạnh nhân khẩu học và kinh tế khác nhau. Sau đó, biểu đồ phí sẽ chiếu bản phân tích theo cách đồ họa. Nguồn được thu thập từ kaggle. Nó nằm ở đây.
Tổ chức dữ liệu
Trong chương trình dưới đây, đầu tiên chúng ta thu thập dữ liệu bằng cách sử dụng một chương trình python ngắn. Nó chỉ tải dữ liệu vào khung dữ liệu gấu trúc để phân tích thêm. Kết quả hiển thị một số trường để biểu diễn đơn giản hơn.
Ví dụ
import pandas as pd
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
#https://www.kaggle.com/danofer/india-census#india-districts-census-2011.csv
print(datainput) Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
District code ... Total_Power_Parity 0 1 ... 1119 1 2 ... 1066 2 3 ... 242 3 4 ... 214 4 5 ... 629 .. ... ... ... 635 636 ... 10027 636 637 ... 4890 637 638 ... 3151 638 639 ... 3151 639 640 ... 5782 [640 rows x 118 columns]
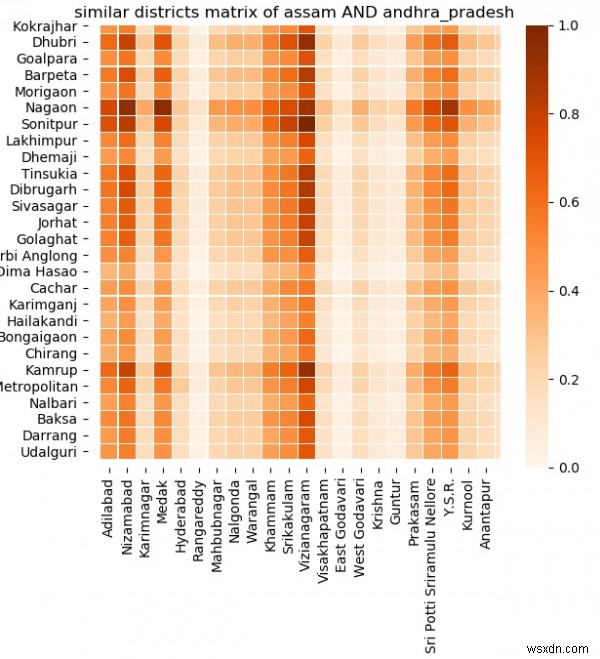
Phân tích sự giống nhau giữa hai quốc gia
Bây giờ chúng tôi đã thu thập được dữ liệu, chúng tôi có thể tiến hành phân tích những điểm tương đồng trên các mặt khác nhau giữa hai Quốc gia. Những điểm tương đồng có thể dựa trên nhóm tuổi, quyền sở hữu máy tính, tình trạng sẵn có nhà ở, trình độ học vấn, v.v. Trong ví dụ dưới đây, chúng tôi lấy hai tiểu bang có tên là Assam và Andhra Pradesh. Sau đó, chúng tôi so sánh hai trạng thái bằng cách sử dụng tương tự_matrix. Tất cả các trường dữ liệu được so sánh cho từng cặp quận có thể có từ cả hai tiểu bang. Bản đồ nhiệt kết quả cho biết hai thứ này có liên quan chặt chẽ như thế nào. Bóng càng tối thì chúng càng có liên quan với nhau.
Ví dụ
import pandas as pd
import matplotlib.pyplot as plot
from matplotlib.colors import Normalize
import seaborn as sns
import math
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
df_ASSAM = datainput.loc[datainput['State name'] == 'ASSAM']
df_ANDHRA_PRADESH = datainput.loc[datainput['State name'] == 'ANDHRA PRADESH']
def segment(x1, x2):
# Set indices for both the data frames
x1.set_index('District code')
x2.set_index('District code')
# The similarity matrix of size len(x1) X len(x2)
similarity_matrix = []
# Iterate through rows of df1
for r1 in x1.iterrows():
# Create list to hold similarity score of row1 with other rows of x2
y = []
# Iterate through rows of x2
for r2 in x2.iterrows():
# Calculate sum of squared differences
n = 0
for c in list(datainput)[3:]:
maximum_c = max(datainput[c])
minimum_c = min(datainput[c])
n += pow((r1[1][c] - r2[1][c]) / (maximum_c - minimum_c), 2)
# Take sqrt and inverse the result
y.append(1 / math.sqrt(n))
# Append similarity scores
similarity_matrix.append(y)
p = 0
q = 0
r = 0
for m in range(len(similarity_matrix)):
for n in range(len(similarity_matrix[m])):
if (similarity_matrix[m][n] > p):
p = similarity_matrix[m][n]
q = m
r = n
print("%s from ASSAM and %s from ANDHRA PRADESH are most similar" % (x1['District name'].iloc[q],x2['District name'].iloc[r]))
return similarity_matrix
m = segment(df_ASSAM, df_ANDHRA_PRADESH)
normalization=Normalize()
s = plot.axes()
sns.heatmap(normalization(m), xticklabels=df_ANDHRA_PRADESH['District name'],yticklabels=df_ASSAM['District name'],linewidths=0.05,cmap='Oranges').set_title("similar districts matrix of assam AND andhra_pradesh")
plot.rcParams['figure.figsize'] = (20,20)
plot.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -
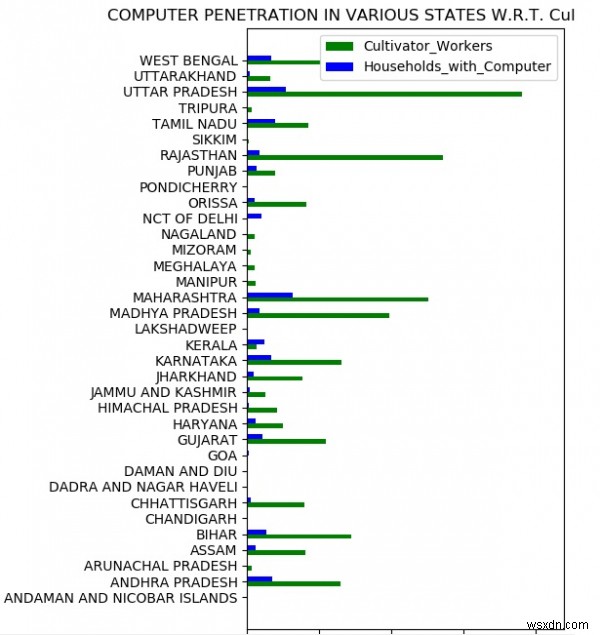
So sánh các thông số cụ thể
Bây giờ chúng ta cũng có thể so sánh các địa điểm với các thông số cụ thể. Trong ví dụ dưới đây, chúng tôi so sánh mức độ sẵn có của các máy tính gia đình dành cho công nhân trồng trọt. Chúng tôi tạo biểu đồ cho thấy sự so sánh giữa hai tham số này cho mỗi trạng thái.
Ví dụ
import pandas as pd
import matplotlib.pyplot as plot
from numpy import *
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
z = datainput.groupby(by="State name")
m = []
w = []
for k, g in z:
t = 0
t1 = 0
for r in g.iterrows():
t += r[1][36]
t1 += r[1][21]
m.append((k, t))
w.append((k, t1))
mp= pd.DataFrame({
'state': [x[0] for x in m],
'Households_with_Computer': [x[1] for x in m],
'Cultivator_Workers': [x[1] for x in w]})
d = arange(35)
wi = 0.3
fig, f = plot.subplots()
plot.xlim(0, 22000000)
r1 = f.barh(d, mp['Cultivator_Workers'], wi, color='g', align='center')
r2 = f.barh(d + wi, mp['Households_with_Computer'], wi, color='b', align='center')
f.set_xlabel('Population')
f.set_title('COMPUTER PENETRATION IN VARIOUS STATES W.R.T. Cultivator_Workers')
f.set_yticks(d + wi / 2)
f.set_yticklabels((x for x in mp['state']))
f.legend((r1[0], r2[0]), ('Cultivator_Workers', 'Households_with_Computer'))
plot.rcParams.update({'font.size': 15})
plot.rcParams['figure.figsize'] = (15, 15)
plot.show() Đầu ra
Chạy đoạn mã trên cho chúng ta kết quả sau -