Được xuất bản lần đầu bởi Tricore:ngày 11 tháng 7 năm 2017
Trong Phần 1 của loạt bài gồm hai phần về Apache ™ Hadoop®, chúng tôi đã giới thiệu hệ thống Hadoopecosystem và khuôn khổ Hadoop. Trong Phần 2, chúng tôi đề cập đến thành phần cốt lõi hơn của khuôn khổ Hadoop, bao gồm các thành phần để truy vấn, tích hợp bên ngoài, trao đổi dữ liệu, điều phối và quản lý. Chúng tôi cũng giới thiệu một mô-đun giám sát các cụm Hadoop.
Truy vấn
Phần 1 của loạt bài này đã giới thiệu Apache Pig ™ như một công cụ viết kịch bản. Được viết bằng tiếng Latinh Pig, Pig được dịch thành các công việc MapReduce có thể thực thi được. Nó cung cấp một số ưu điểm mà bạn có thể tìm hiểu thêm trong Phần 1.
Tuy nhiên, một số nhà phát triển vẫn thích SQL hơn. Nếu bạn muốn làm theo những gì bạn biết, bạn có thể sử dụng SQL với Hadoop để thay thế.
Hive
Apache Hive ™ là một kho dữ liệu phân tán quản lý và sắp xếp lượng lớn dữ liệu. Nhà kho này được xây dựng dựa trên Hệ thống tệp phân phối Hadoop (HDFS ™). Ngôn ngữ truy vấn Hive, HiveQL, dựa trên ngữ nghĩa SQL. Công cụ thời gian chạy chuyển đổi HiveQL thành công việc MapReduce truy vấn dữ liệu.
Hive cung cấp các khả năng sau:
-
Một kho dữ liệu đã được toán học hóa để chứa một lượng lớn dữ liệu thô.
-
Một môi trường giống SQL để thực hiện các phân tích và truy vấn trên dữ liệu thô trong HDFS.
-
Tích hợp với các ứng dụng hệ quản trị cơ sở dữ liệu quan hệ bên ngoài (RDBMS).
Hình ảnh sau đây mô tả kiến trúc của hệ sinh thái Hadoop:
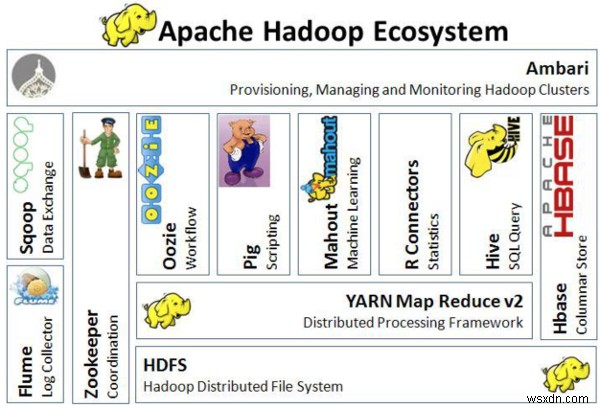 Kiến trúc của hệ sinh thái Hadoop
Kiến trúc của hệ sinh thái Hadoop Tích hợp bên ngoài
Apache Flume ™ là một dịch vụ phân tán, đáng tin cậy và có sẵn để thu thập, tổng hợp và chuyển một lượng lớn dữ liệu nhật ký vàoHDFS một cách hiệu quả. Flume vận chuyển một lượng lớn dữ liệu sự kiện bằng cách sử dụng kiến trúc luồng dữ liệu trực tuyến có khả năng chịu lỗi và sẵn sàng khôi phục chuyển đổi dự phòng.
Flume cũng cung cấp các khả năng sau:
-
Vận chuyển một lượng lớn dữ liệu sự kiện như lưu lượng mạng, nhật ký và tin nhắn email.
-
Truyền dữ liệu từ nhiều nguồn vào HDFS.
-
Đảm bảo truyền dữ liệu thời gian thực, đáng tin cậy tới các ứng dụng Hadoop.
Trao đổi dữ liệu
Apache Sqoop ™ được thiết kế để truyền dữ liệu số lượng lớn một cách hiệu quả giữa Hadoop và các kho dữ liệu bên ngoài như cơ sở dữ liệu quan hệ và kho dữ liệu enterprised. Sqoop hoạt động với các cơ sở dữ liệu quan hệ như TeradataDatabase, IBM® Netezza, Oracle® Database, MySQL ™ vàPostgreSQL®. Sqoop được sử dụng rộng rãi trong hầu hết các công ty thu thập hoặc phân tích dữ liệu lớn.
Sqoop cung cấp các chức năng sau:
-
Tùy thuộc vào cơ sở dữ liệu, nó có thể tự động hóa hầu hết quá trình mô tả lược đồ cho dữ liệu được nhập.
-
Nó sử dụng khung MapReduce để nhập và xuất dữ liệu. Điều này cho phépSqoop cung cấp một cơ chế song song và khả năng chịu lỗi.
-
Nó cung cấp các trình kết nối cho tất cả các cơ sở dữ liệu RDBMS chính.
-
Nó hỗ trợ tải đầy đủ và tăng dần, xuất và nhập dữ liệu song song và nén dữ liệu.
-
Nó hỗ trợ tích hợp bảo mật Kerberos.
Phối hợp
Apache Zookeeper ™ là một dịch vụ điều phối cho các ứng dụng phân tán cho phép đồng bộ hóa trên một cụm. Nó cung cấp một kho lưu trữ tập trung, nơi các ứng dụng phân tán có thể lưu trữ và truy xuất dữ liệu.
Zookeeper là một công cụ Hadoop quản trị được sử dụng để quản lý các công việc trong acluster. Một số nhà phát triển gọi công cụ này là “người bảo vệ theo dõi” vì bất kỳ thay đổi nào đối với dữ liệu trong một nút đều được truyền đạt đến các nút khác.
Cung cấp, quản lý và giám sát các cụm Hadoop
Apache Ambari ™ là một công cụ dựa trên web để cung cấp, quản lý và điều chỉnh các cụm Apache Hadoop. Nó có giao diện người dùng rất đơn giản nhưng có tính tương tác cao để cài đặt các công cụ và thực hiện các tác vụ quản lý, cấu hình và giám sát. Ambari cung cấp một bảng điều khiển để xem thông tin về tình trạng của xe, chẳng hạn như bản đồ nhiệt. Nó cũng cho phép bạn xem các ứng dụng MapReduce, Pig và Hive cùng với các tính năng để bạn có thể dễ dàng chẩn đoán các đặc điểm hiệu suất của hệ thống.
Ambari cũng cung cấp các khả năng sau:
-
Ánh xạ các dịch vụ chính với các nút.
-
Khả năng chọn các dịch vụ mà bạn muốn cài đặt.
-
Lựa chọn ngăn xếp tùy chỉnh đơn giản.
-
Giao diện gọn gàng hơn.
-
Cài đặt, giám sát và quản lý được tổ chức hợp lý.
Kết luận
Hadoop là một giải pháp rất hiệu quả cho các công ty muốn lưu trữ và phân tích một lượng lớn dữ liệu. Đây là một công cụ được tìm kiếm nhiều để quản lý dữ liệu trong các hệ thống phân tán. Bởi vì nó là mã nguồn mở, nó có sẵn miễn phí cho các công ty tận dụng. Để tìm hiểu thêm về Hadoop, hãy xem tài liệu chính thức tại trang web Apache Software Foundation.
Bạn đã sử dụng Hadoop chưa? Sử dụng tab Phản hồi để đưa ra bất kỳ nhận xét hoặc đặt câu hỏi nào.