Được xuất bản lần đầu bởi Tricore:2 tháng 8, 2017
Mặc dù bắt đầu với MongoDB thật dễ dàng, nhưng các vấn đề phức tạp hơn sẽ xuất hiện khi bạn xây dựng ứng dụng. Bạn có thể thấy mình tự hỏi những điều tương tự:
- Làm cách nào để đồng bộ hóa lại thành viên bản sao trong nhóm bản sao?
- Làm cách nào để khôi phục MongoDB sau sự cố?
- Khi nào tôi nên sử dụng đặc tả GridFS của MongoDB để lưu trữ và truy xuất tệp?
- Làm cách nào để sửa dữ liệu bị hỏng?
Bài đăng trên blog này chia sẻ một số mẹo để xử lý những tình huống này khi bạn đang sử dụng MongoDB.
Mẹo 1:Không phụ thuộc vào lệnh sửa chữa để khôi phục dữ liệu của bạn
Nếu cơ sở dữ liệu của bạn gặp sự cố và bạn không chạy với –journal gắn cờ, không sử dụng dữ liệu của máy chủ đó.
repair của MongoDB lệnh đi qua mọi tài liệu mà nó có thể tìm thấy và tạo bản sao sạch của nó. Tuy nhiên, hãy nhớ rằng quá trình này tốn nhiều thời gian, sử dụng nhiều dung lượng đĩa (cùng một lượng dung lượng hiện đang được sử dụng) và bỏ qua mọi bản ghi bị hỏng. Vì quy trình sao chép của MongoDB không thể sửa dữ liệu bị hỏng, bạn cần đảm bảo xóa sạch dữ liệu có thể bị hỏng trước khi đồng bộ hóa lại.
Mẹo 2:Đồng bộ hóa lại một thành viên của nhóm bản sao
Để đồng bộ hóa lại một thành viên của nhóm bản sao, hãy đảm bảo rằng ít nhất một thành viên phụ và một thành viên chính đang hoạt động. Sau đó, hãy đảm bảo rằng bạn đã đăng nhập với tư cách là người dùng có tên Oracle và dừng dịch vụ MongoDB.
Đăng nhập với tư cách người dùng có tên MongoDB và di chuyển tất cả các tệp dữ liệu trong thư mục sao lưu để bạn có thể khôi phục chúng nếu gặp sự cố. Nếu các tệp thư mục hiện diện trong thư mục sao lưu, bạn có thể xóa chúng. Nếu bạn không chắc chắn nơi tìm các tệp dữ liệu, hãy xem trong /etc/mongod.conf . Là người dùng có tên Oracle, hãy khởi động dịch vụ MongoDB.
Đăng nhập vào tập dữ liệu để xác thực. Bạn không cần xác thực để truy cập cơ sở dữ liệu cho đến khi thành viên được đồng bộ hóa trong tập hợp bản sao.
Sau khi quá trình sao chép hoàn tất, trạng thái sẽ thay đổi từ STARTUP2 thành SECONDARY .
Mẹo 3:Không sử dụng GridFS cho dữ liệu nhị phân, nhỏ
MongoDB sử dụng đặc tả GridFS để lưu trữ và truy xuất các tệp lớn. Inessence, GridFS chia nhỏ các đối tượng nhị phân lớn trước khi lưu trữ chúng trong cơ sở dữ liệu adatabase. GridFS yêu cầu hai truy vấn:một để tìm nạp siêu dữ liệu của tệp và một để tìm nạp nội dung của nó. Do đó, nếu bạn sử dụng GridFS để lưu trữ các tệp nhỏ, bạn sẽ tăng gấp đôi số lượng truy vấn mà ứng dụng của bạn phải thực hiện.
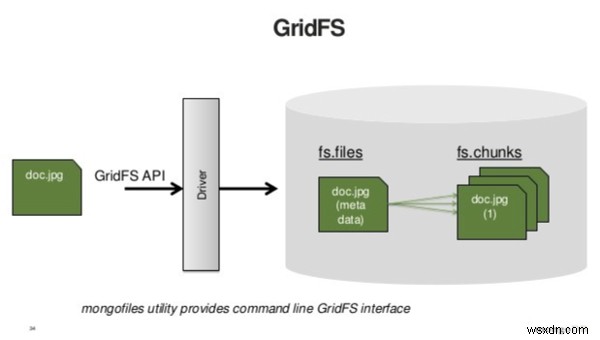
Nguồn:https://www.slideshare.net
GridFS được thiết kế để lưu trữ dữ liệu lớn, nghĩa là dữ liệu quá lớn để có thể lướt qua một tài liệu. Theo nguyên tắc chung, bất kỳ thứ gì quá lớn để tải vào khách hàng có thể không phải là thứ mà bạn muốn tải tất cả cùng một lúc lên aserver. Giải pháp thay thế là phát trực tuyến. Bất kỳ thứ gì bạn định phát trực tuyến tới aclient đều là ứng cử viên sáng giá cho GridFS.
Mẹo 4:Giảm thiểu quyền truy cập vào đĩa
Các nhà phát triển biết rằng truy cập dữ liệu từ RAM thì nhanh và truy cập dữ liệu từ đĩa thì chậm.
Mặc dù bạn có thể biết rằng giảm thiểu số lần truy cập đĩa là một kỹ thuật tối ưu hóa tuyệt vời, nhưng bạn có thể không biết cách thực hiện nhiệm vụ này.
Một cách là sử dụng ổ cứng thể rắn (SSD). SSD thực hiện nhiều tác vụ nhanh hơn nhiều so với ổ cứng truyền thống (HDD). Chúng cũng hoạt động rất tốt với MongoDB. Mặt khác, chúng thường nhỏ hơn và đắt hơn.
Hình ảnh sau đây so sánh SSD và HDD.

Nguồn:https://www.serverintellect.com
Một cách khác để giảm số lần truy cập đĩa là thêm nhiều RAM hơn. Tuy nhiên, cách làm này sẽ chỉ đưa bạn đi xa vì cuối cùng RAM của bạn sẽ không thể đáp ứng được kích thước dữ liệu của bạn.
Câu hỏi đặt ra là, làm cách nào để chúng ta lưu trữ hàng terabyte hoặc petabyte dữ liệu trên đĩa, lập trình một ứng dụng hầu như sẽ truy cập vào bộ nhớ dữ liệu được yêu cầu thường xuyên và di chuyển dữ liệu từ đĩa vào bộ nhớ một cách ít thường xuyên nhất có thể?
Nếu bạn truy cập tất cả dữ liệu của mình một cách ngẫu nhiên trong thời gian thực, câu trả lời là bạn sẽ cần rất nhiều RAM. Tuy nhiên, hầu hết các ứng dụng không hoạt động theo cách này. Dữ liệu gần đây được truy cập thường xuyên hơn dữ liệu cũ hơn, một số người dùng nhất định hoạt động tích cực hơn những người khác và một số khu vực nhất định có nhiều khách hàng hơn những người khác. và truy cập đĩa rất hiếm khi.
Mẹo 5:Khởi động MongoDB bình thường sau sự cố cơ sở dữ liệu
Nếu bạn chạy nhật ký và hệ thống của bạn gặp sự cố theo cách có thể khôi phục được, bạn có thể khởi động lại cơ sở dữ liệu một cách bình thường. Đảm bảo rằng bạn đang sử dụng tất cả các tùy chọn thông thường của mình, đặc biệt là -- dbpath (để nó có thể tìm thấy các tệp tạp chí) và --journal .
MongoDB sẽ tự động sửa dữ liệu của bạn trước khi bắt đầu chấp nhận kết nối. Quá trình này có thể mất vài phút đối với các tập dữ liệu lớn, nhưng không tốn nhiều thời gian so với thời gian thông thường để chạy sửa chữa trên các tập dữ liệu lớn.
Các tệp nhật ký được lưu trữ trong journal danh mục. Không xóa các tệp này.
Mẹo 6:Thu gọn cơ sở dữ liệu bằng cách sử dụng lệnh sửa chữa
Về cơ bản, lệnh sửa chữa thực hiện một mongodump và sau đó là mongorestore , tạo một bản sao rõ ràng của dữ liệu của bạn. Trong quá trình này, nó cũng loại bỏ mọi “lỗ hổng” trống trong tệp dữ liệu của bạn.
Lệnh sửa chữa chặn hoạt động và yêu cầu gấp đôi dung lượng đĩa mà cơ sở dữ liệu của bạn hiện đang chạy. Tuy nhiên, nếu bạn có một máy khác, bạn có thể thực hiện quy trình tương tự theo cách thủ công bằng cách sử dụng mongodump và mongorestore .
Để hoàn tất quy trình theo cách thủ công, hãy sử dụng các bước sau:
-
Bước xuống máy Hyd1 và
fsyncvàlock:rs.stepDown() db.runCommand({fsync : 1, lock : 1}) -
Dump tệp vào Hyd2:
Hyd2$ mongodump --host Hyd1 -
Tạo một bản sao của tệp dữ liệu trong Hyd1, để bạn vẫn có nó dưới dạng dự phòng. Sau đó, xóa tệp dữ liệu gốc và khởi động lại Hyd1 với dữ liệu trống.
-
Khôi phục nó từ Hyd2. Để khôi phục tệp dữ liệu, hãy nhập lệnh sau:
Hyd2$ mongorestore --host Hyd1 --port 10000 # specify port if it's not 27017
Kết luận
Những thay đổi này đã tăng đáng kể hiệu suất MongoDB của chúng tôi. Nếu bạn đang có kế hoạch sử dụng MongoDB, bạn có thể muốn đánh dấu bài viết này, sau đó quay lại bài viết đó và kiểm tra từng lần tiếp theo khi bạn bắt đầu một dự án mới.
Trong Phần 2 của loạt bài gồm hai phần, chúng tôi sẽ chia sẻ một số mẹo giúp các doanh nghiệp lớn thiết kế, tối ưu hóa và triển khai các tính năng MongoDB hữu ích.
Sử dụng tab Phản hồi để đưa ra bất kỳ nhận xét hoặc đặt câu hỏi nào.