
Excel là một trong những công cụ mạnh mẽ nhất để phân tích dữ liệu nhưng nó có những hạn chế. Khi các tập dữ liệu phát triển thành hàng triệu hàng, khi các báo cáo cần chạy tự động hoặc khi các phân tích yêu cầu máy học, chỉ riêng Excel đã bắt đầu thể hiện sự cũ kỹ của nó. Python lấp đầy nhiều khoảng trống này. Tích hợp Python đã biến Excel từ một công cụ bảng tính truyền thống thành nền tảng phân tích dữ liệu mạnh mẽ hơn. Với Python có sẵn ngay trong Excel, giờ đây, các nhà phân tích có thể thực hiện các phép tính nâng cao, xây dựng mô hình dự đoán và tạo các hình ảnh trực quan phức tạp mà không cần rời khỏi sổ làm việc của họ.
Trong hướng dẫn này, chúng tôi sẽ hiển thị năm thư viện Python để phân tích dữ liệu Excel nâng cao mà mọi chuyên gia nên sử dụng. Những thư viện này cho phép bạn thực hiện thao tác dữ liệu nâng cao, trực quan hóa và học máy ngay trong Excel.
1. Pandas – Cốt lõi của thao tác và phân tích dữ liệu
Nếu bạn chỉ học một thư viện Python để phân tích Excel, hãy tìm hiểu Pandas đầu tiên. Pandas là nền tảng cho hầu hết mọi tác vụ nâng cao liên quan đến Excel trong Python. Nó biến dữ liệu Excel thành DataFrames mạnh mẽ để làm sạch, chuyển đổi, lọc, nhóm, hợp nhất, tổng hợp và khám phá các tập dữ liệu lớn một cách hiệu quả.
Điểm mạnh chính của Excel Ưu điểm:
- Đọc và ghi các tệp Excel nguyên bản bằng pd.read_excel() và df.to_excel()
- Xử lý dữ liệu lộn xộn:xóa trùng lặp, điền các giá trị còn thiếu và chuẩn hóa các định dạng
- Thực hiện việc nhóm và tổng hợp nâng cao bằng logic vượt xa PivotTable
- Hợp nhất hoặc nối nhiều trang tính hoặc tệp
- Tạo tóm tắt thống kê với df.describe()
- Chạy một vài dòng mã và lần nào cũng nhận được kết quả tương tự
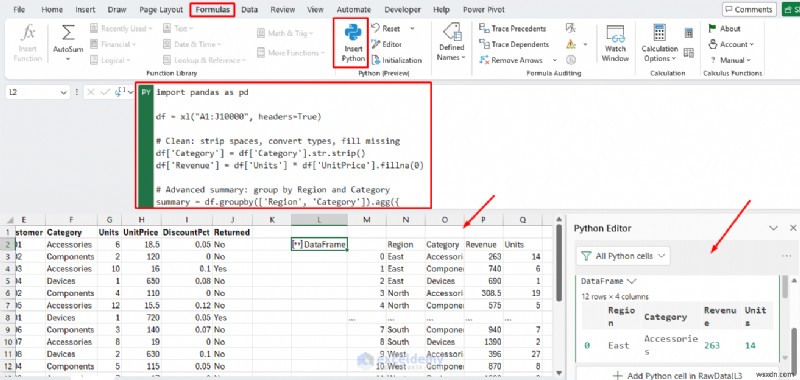
Ví dụ:Dọn dẹp dữ liệu lộn xộn
Vấn đề đau đầu phổ biến của Excel là nhận dữ liệu có nhiều loại, thiếu giá trị và định dạng không nhất quán. Với Pandas, bạn có thể sửa mọi thứ bằng một tập lệnh có thể lặp lại.
Python trong Excel:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
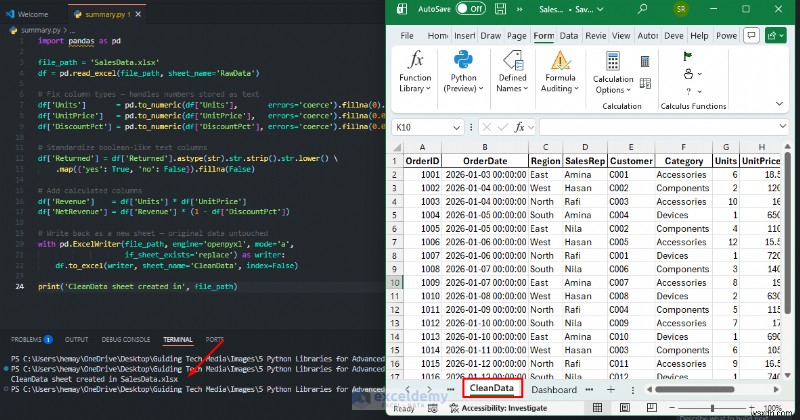
Python trong Mã VS:
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
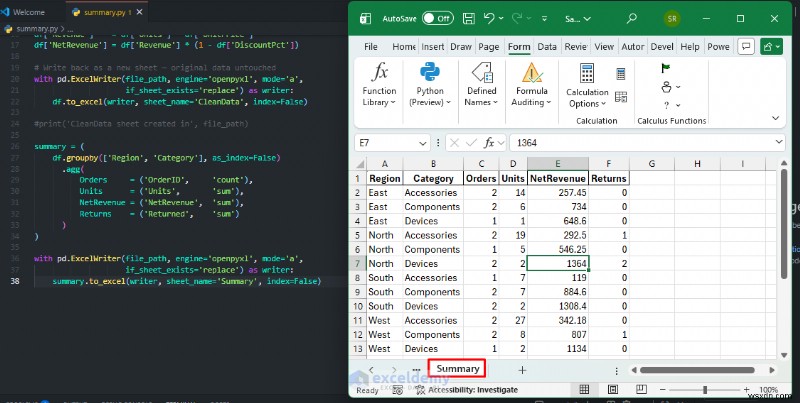
Tự động hóa báo cáo tóm tắt
Thay thế PivotTable thủ công bằng Pandas groupby quy trình làm việc diễn ra trong vài giây và xuất trang tính sẵn sàng chia sẻ mỗi khi cập nhật dữ liệu của bạn:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
Khi nào nên sử dụng: Bạn nhận được kết quả đầu ra kiểu PivotTable nhưng quá trình dọn dẹp và logic diễn ra trong cùng một quy trình làm việc. Điều đó có nghĩa là ít báo cáo bị hỏng hơn và ít sự can thiệp thủ công hơn. Người dùng thành thạo dựa vào Pandas để xử lý các tập dữ liệu quá lớn hoặc quá phức tạp đối với Excel gốc, đặc biệt khi tập dữ liệu vượt quá vài nghìn hàng, khi bạn cần lặp lại bước dọn dẹp hoặc tóm tắt hoặc khi bạn cần tự động hợp nhất dữ liệu từ nhiều nguồn.
2. OpenPyXL – Thao tác tệp Excel nâng cao và định dạng gốc
Trong khi Pandas xử lý dữ liệu, OpenPyXL vượt trội trong việc kiểm soát chi tiết đối với .xlsx tệp:định dạng ô, thêm biểu đồ, bảng, kiểu, công thức và hình ảnh mà không làm mất các tính năng gốc của Excel. Nó cho phép bạn làm việc trực tiếp với .xlsx các tệp, vì vậy quy trình làm việc Python của bạn có thể tạo ra kết quả sẵn sàng cho Excel thay vì chỉ phân tích thô.
Điểm mạnh chính của Excel Ưu điểm:
- Tạo và sửa đổi sổ làm việc theo chương trình
- Xuất các bảng đã được làm sạch sang các trang tính mới
- Thêm trực tiếp các biểu đồ chuyên nghiệp ở định dạng Excel tự động cập nhật
- Tự động thay thế các tab báo cáo cũ
- Áp dụng định dạng có điều kiện, đường viền, phông chữ và kiểu cho các ô cụ thể
- Thêm các công thức Excel chẳng hạn như =SUM() hoặc =VLOOKUP() vào ô
- Bảo vệ trang tính, cố định khung và đặt độ rộng cột theo chương trình
- Xây dựng các sản phẩm dựa trên sổ làm việc cho người dùng không sử dụng Python
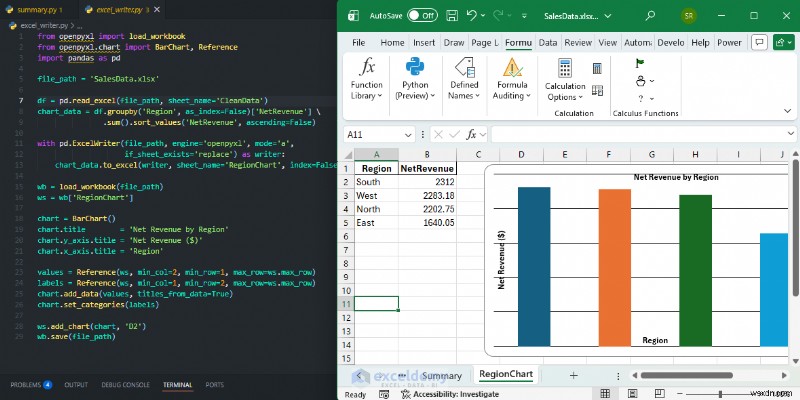
Ví dụ:Thêm biểu đồ gốc vào sổ làm việc của bạn
Sau khi tạo dữ liệu sạch bằng Pandas, hãy sử dụng openpyxl để thêm biểu đồ thanh chuyên nghiệp mà không cần mở Excel theo cách thủ công.
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
Khi nào nên sử dụng: Pandas giúp bạn phân tích dữ liệu. openpyxl giúp bạn cung cấp nó. Sử dụng OpenPyXL khi bạn cần các kết quả đầu ra Excel có độ phân giải hoàn hảo, chẳng hạn như các báo cáo và trang tổng quan trông được tạo thủ công và khi kết quả cần hiển thị ở định dạng .xlsx tệp có biểu đồ và định dạng Excel gốc mà đồng nghiệp có thể tiếp tục chỉnh sửa.
3. Matplotlib – Trực quan hóa mạnh mẽ ngoài biểu đồ Excel
Biểu đồ Excel rất tiện lợi nhưng Matplotlib mang lại cho các nhà phân tích nhiều quyền kiểm soát hơn. Matplotlib là thư viện dùng để tạo các biểu đồ tĩnh, có chất lượng xuất bản. Nó có khả năng tùy biến cao và tích hợp tốt với Pandas để phân tích thăm dò nhanh chóng.
Điểm mạnh chính của Excel Ưu điểm:
- Tạo các biểu đồ nâng cao như bản đồ nhiệt, biểu đồ phân tán với đường xu hướng, biểu đồ hộp, biểu đồ và biểu đồ 3D
- Có được nhiều quyền kiểm soát hơn đối với phông chữ, màu sắc, đường lưới, dấu kiểm và chú giải
- Xây dựng bố cục ô phụ nhiều bảng hiển thị nhiều biểu đồ cùng một lúc
- Xuất sang hình ảnh, PDF hoặc SVG hoặc nhúng hình ảnh trực quan trở lại Excel bằng OpenPyXL
- Chú thích các điểm dữ liệu bằng nhãn và mũi tên tùy chỉnh
Ví dụ:Tạo Trang tổng quan bán hàng nhiều bảng
Hãy tạo biểu đồ hai bảng:xu hướng doanh thu hàng tháng ở bên trái và phân tích danh mục ở bên phải. Sau đó, chúng tôi sẽ lưu nó dưới dạng hình ảnh có độ phân giải cao, sẵn sàng cho mọi báo cáo.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
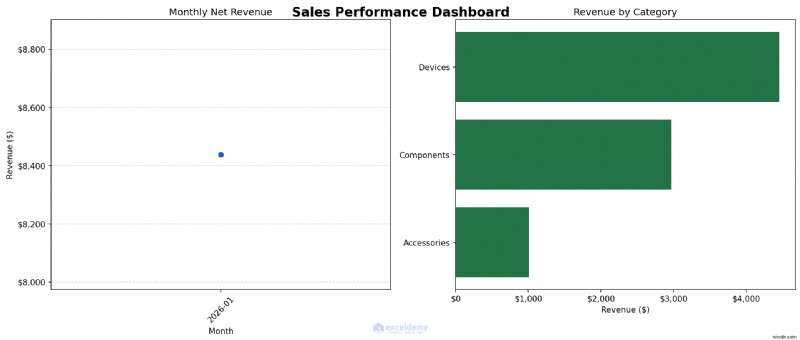
Khi nào nên sử dụng: Trước tiên hãy sử dụng Python để tạo biểu đồ phân tích. Sau đó, quyết định xem biểu đồ có nên vẫn là đầu ra Python hay dữ liệu tóm tắt sẽ được trả về Excel để định dạng trang tổng quan cuối cùng. Sử dụng Matplotlib khi bạn cần biểu đồ cho báo cáo hoặc bản trình bày hoặc khi bạn cần tạo nhiều lần cùng một biểu đồ từ dữ liệu cập nhật với kiểu dáng nhất quán.
4. Seaborn – Trực quan hóa dữ liệu thống kê
Sinh ra ở biển được xây dựng trên Matplotlib và tập trung vào trực quan hóa thống kê. Nó đơn giản hóa việc tạo các biểu đồ trực quan hấp dẫn làm nổi bật các mô hình và mối tương quan. Trong khi Matplotlib có thể yêu cầu hàng chục dòng để có một biểu đồ bóng bẩy, Seaborn thường có thể đạt được kết quả tương tự trong một hoặc hai dòng với kiểu dáng mặc định hấp dẫn. Nó vượt trội trong việc tiết lộ các phân bố, mối tương quan và các mẫu ẩn trong dữ liệu của bạn.
Điểm mạnh chính của Excel Ưu điểm:
- Tạo biểu đồ thống kê nhanh chóng
- Hoạt động tốt để phân tích dữ liệu khám phá
- Xây dựng bản đồ nhiệt tương quan để xem các cột liên quan với nhau như thế nào
- Tạo các ô phân phối với các đường cong mật độ được tích hợp sẵn
- Sử dụng biểu đồ hình hộp và biểu đồ đàn vĩ cầm để so sánh các nhóm một cách trực quan
- Tạo biểu đồ cặp cho ma trận biểu đồ phân tán tự động trên các cột số
- Tạo biểu đồ hồi quy với khoảng tin cậy trên một dòng
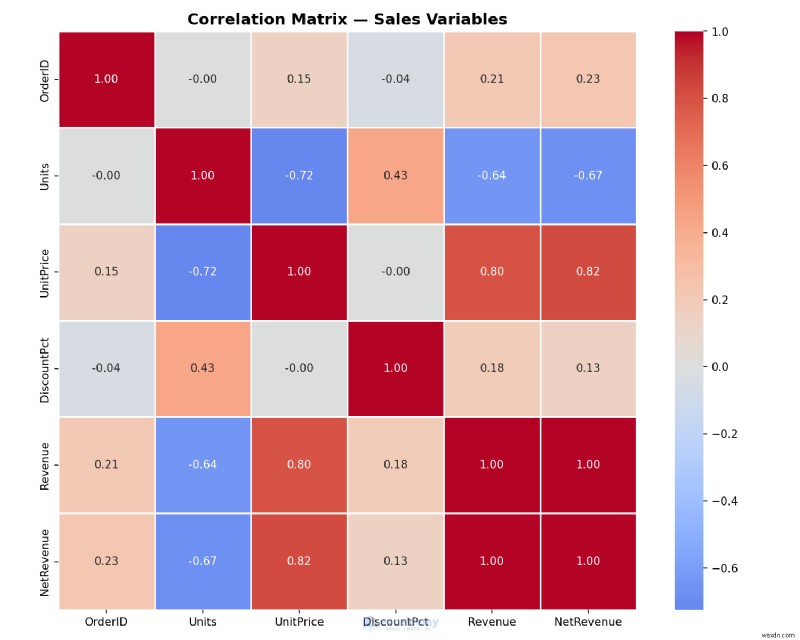
Ví dụ:Tạo bản đồ nhiệt tương quan
Tìm các mẫu ẩn trong dữ liệu Excel của bạn:biến nào di chuyển cùng nhau? Bản đồ nhiệt có thể giải quyết vấn đề này một cách nhanh chóng và vượt xa những gì các công cụ tích hợp của Excel thường cung cấp.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
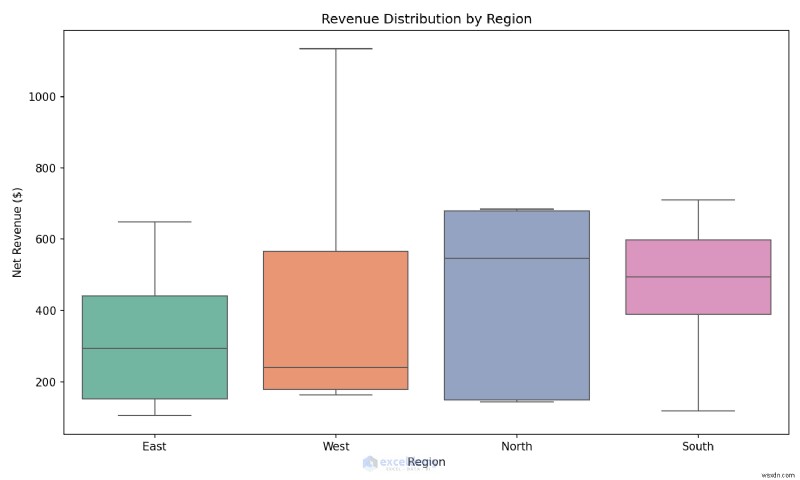
Ví dụ:Tạo ô hộp trên một dòng
So sánh mức phân bổ doanh thu giữa các khu vực để phát hiện ngay các điểm khác biệt.
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
Khi nào nên sử dụng: Sử dụng Seaborn trong quá trình phân tích thăm dò khi bạn muốn nhanh chóng hiểu được các phân bố, giá trị ngoại lệ và mối quan hệ trước khi xây dựng báo cáo chính thức.
5. Scikit-learn – Học máy trực tiếp trên dữ liệu Excel
Đây là thư viện chuyển bạn từ báo cáo sang hỗ trợ quyết định. Scikit-learn mang khả năng học máy chuyên nghiệp vào quy trình làm việc Excel của bạn. Nó cho phép phân tích dự đoán cho người dùng Excel, bao gồm hồi quy, phân loại, phân cụm và dự báo mà Excel gốc không thể xử lý dễ dàng. Thay vì chỉ mô tả những gì đã xảy ra trong dữ liệu của bạn, nó giúp bạn dự đoán những gì có thể xảy ra tiếp theo, từ dự báo doanh số bán hàng đến phân loại khách hàng cho đến phát hiện những điều bất thường.
Điểm mạnh chính của Excel Ưu điểm:
- Hồi quy tuyến tính và logistic để dự đoán các kết quả hoặc danh mục bằng số như rủi ro rời bỏ hoặc dự báo doanh số
- Cây quyết định và rừng ngẫu nhiên cho những dự đoán có thể hiểu được
- K-nghĩa là tự động phân cụm để nhóm các bản ghi tương tự
- Tách thử nghiệm đào tạo và xác thực chéo để đo độ chính xác của mô hình
- Quy trình chia tỷ lệ tính năng, mã hóa và tiền xử lý
- Trả lại dự đoán cho Excel để lọc và sắp xếp
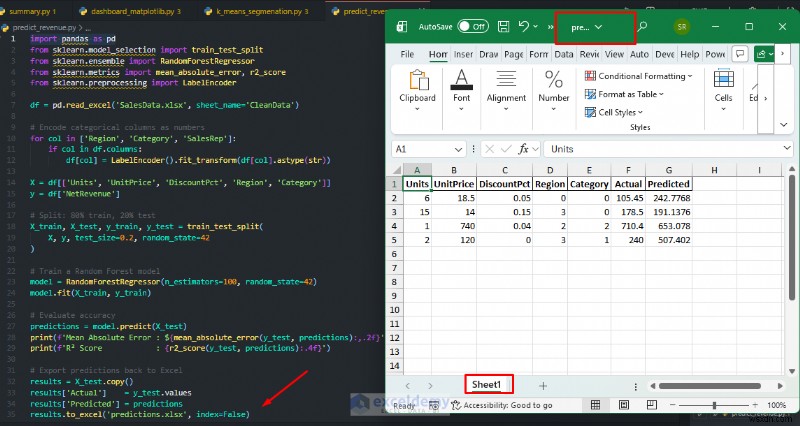
Ví dụ:Dự đoán doanh thu thuần
Huấn luyện mô hình dựa trên dữ liệu bán hàng lịch sử của bạn, sau đó sử dụng mô hình đó để dự đoán doanh thu cho các đơn đặt hàng mới. Đây là một phân tích mà Excel không thể thực hiện nguyên bản.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
Phân khúc khách hàng K-Means:
Tự động phân chia khách hàng thành các nhóm dựa trên hành vi mua hàng mà không cần tiêu chí thủ công.
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
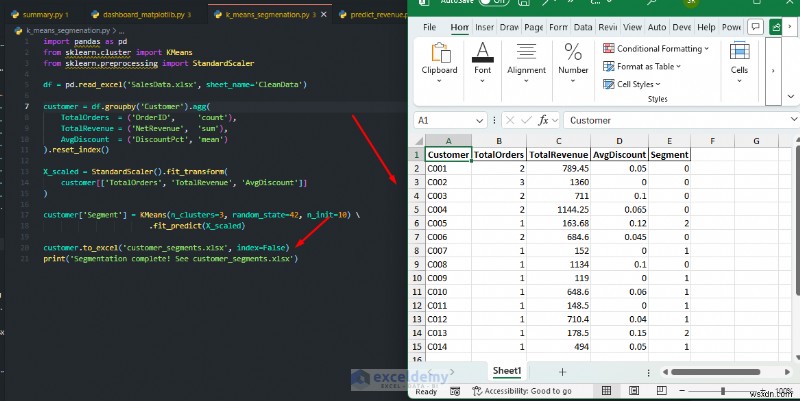
Khi nào nên sử dụng: Bạn có thể viết lại các dự đoán vào một trang tính, sau đó cho phép người dùng Excel lọc, sắp xếp, lập biểu đồ hoặc kết hợp các kết quả với các công thức và định dạng có điều kiện. Điều này cho phép các chuyên gia thêm trực tiếp thông tin chi tiết về máy học vào bảng tính. Sử dụng Scikit-learn khi bạn cần dự đoán các giá trị trong tương lai, phân loại bản ghi hoặc khám phá các nhóm tự nhiên mà PivotTable không thể tiết lộ.
Phần thưởng:Xlwings – Tự động hóa hai chiều và tích hợp Excel trực tiếp
xlwings thư viện chạy một phiên bản Excel trong thời gian thực. Nó kết nối Python và Excel, cho phép tự động hóa thực sự. Trong khi openpyxl đọc và ghi các tệp tĩnh, xlwings có thể mở Excel, thao tác trực tiếp, đọc lại các giá trị vào Python, kích hoạt các hàm Python từ các nút Excel và xây dựng các UDF (hàm do người dùng xác định) đầy đủ xuất hiện trong các ô. Đây là giải pháp thay thế hiện đại cho nhiều quy trình làm việc dựa trên VBA.
Điểm mạnh chính của Excel Ưu điểm:
- Điều khiển phiên Excel trực tiếp:mở, đọc, viết và đóng sổ làm việc theo chương trình
- Viết các hàm Python có thể gọi trực tiếp từ các ô Excel dưới dạng UDF
- Tự động hóa các tác vụ lặp đi lặp lại như làm mới dữ liệu và tạo báo cáo
- Đẩy trực tiếp biểu đồ Pandas DataFrames và Matplotlib vào các phạm vi được đặt tên
- Chạy tập lệnh Python được kích hoạt bằng các nút Excel
- Hoạt động trên cả Windows và macOS
- Là giải pháp thay thế hoặc bổ sung mạnh mẽ cho Python trong Excel dành cho quy trình làm việc trên máy tính để bàn
Bạn có thể sử dụng xlwings khi cần tương tác trực tiếp, hai chiều với Excel, khi thay thế macro VBA, khi xây dựng trang tổng quan tương tác hoặc khi cho phép các đồng nghiệp không rành về kỹ thuật kích hoạt phân tích Python chỉ bằng một cú nhấp chuột.
Chọn ngăn xếp thư viện tốt nhất cho các chuyên gia Excel khác nhau
Không phải mọi nhà phân tích đều cần tất cả năm thư viện cùng một lúc. Một cách thiết thực để áp dụng chúng là theo vai trò.
- Dành cho nhà phân tích báo cáo: Sự kết hợp này cho phép bạn làm sạch dữ liệu, tạo bản tóm tắt, tạo biểu đồ và xuất kết quả sổ làm việc tinh tế.
- Gấu trúc
- Matplotlib
- Openpyxl
- Dành cho nhà phân tích tài chính và hoạt động: Ngăn xếp này hoạt động tốt để lập mô hình, tính toán KPI, phân bổ và báo cáo hàng tháng có thể lặp lại.
- Gấu trúc
- Sinh vật biển
- Openpyxl
- Dành cho nhóm phân tích nâng cao: Sự kết hợp này cung cấp cho bạn quy trình đầy đủ từ việc chuẩn bị dữ liệu đến tính điểm dự đoán cho đến phân phối sổ làm việc.
- Gấu trúc
- Matplotlib
- Scikit-learn
- Openpyxl
- Sinh vật biển
Suy nghĩ cuối cùng
Đây là năm thư viện Python để phân tích dữ liệu Excel nâng cao mà mọi chuyên gia nên sử dụng. Nắm vững các công cụ này và bạn có thể chuyển đổi Excel từ một ứng dụng bảng tính đơn giản thành một nền tảng phân tích có khả năng cao hơn. Một lộ trình học tập hợp lý là bắt đầu với Pandas, sau đó thêm openpyxl, sau đó học Matplotlib và Seaborn cùng nhau, rồi giải quyết Scikit-learn sau đó. Mỗi thư viện đều hoạt động với cùng một .xlsx tập tin bạn đã sử dụng. Hãy bắt đầu khám phá chúng để trở thành nhà phân tích dữ liệu có năng lực hơn.
Nhận MIỄN PHÍ Bài tập Excel nâng cao có Giải pháp!