Giới thiệu về Đại lý nghiên cứu AI
Nghiên cứu học thuật tiến triển nhanh chóng—các bài báo mới xuất hiện hàng ngày trên arXiv và các máy chủ in trước khác. Việc duy trì thủ công có thể khiến bạn choáng ngợp. Trong hướng dẫn này, chúng tôi sẽ xây dựng trợ lý nghiên cứu AI đó:
- Hiểu được câu hỏi bằng ngôn ngữ tự nhiên của nhà nghiên cứu
- Tìm các bài viết phù hợp nhất trong cơ sở dữ liệu vectơ của bản tóm tắt arXiv
- Tóm tắt những hiểu biết chính và giải thích cách họ trả lời câu hỏi
- Cung cấp liên kết PDF trực tiếp để đọc sâu hơn
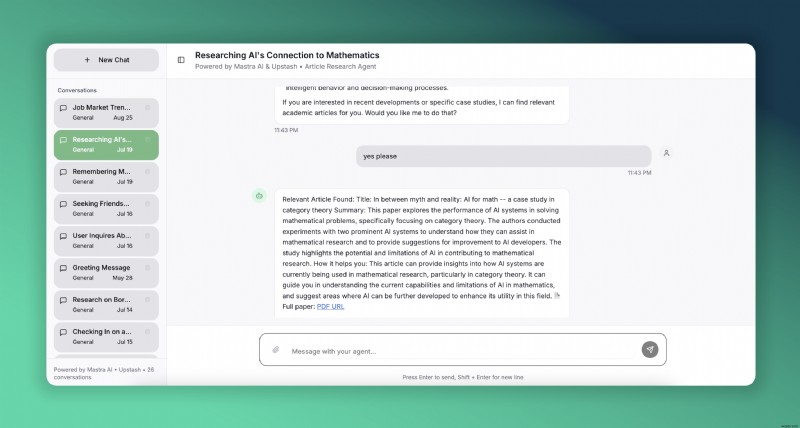
Chúng tôi sẽ thực hiện điều này với Mastra , khung TypeScript nguồn mở để xây dựng tác nhân AI và Upstash để lưu trữ Redis và Vector không có máy chủ. Đây là bản demo trực tiếp về tác nhân bài viết của chúng tôi tập trung vào nghiên cứu AI. Nó được triển khai trên Vercel để bạn dùng thử.
Mastra là gì?
Mastra là một khung bao gồm pin giúp việc tạo tác nhân AI cấp sản xuất trở nên đơn giản.
- Đại lý &quy trình công việc — Soạn thảo các tác nhân, công cụ và quy trình làm việc nhiều bước
- Thế hệ tăng cường truy xuất (RAG) - Bộ nhớ tích hợp và kho lưu trữ vector
- Đa LLM - Hoạt động với OpenAI, Claude và hơn thế nữa.
Chúng tôi sẽ tạo một tác nhân sử dụng Upstash Redis cho bộ nhớ. Nó cũng sẽ có một công cụ để tìm các bài báo nghiên cứu có liên quan mà trước đây chúng tôi đã nhúng vào cơ sở dữ liệu Upstash Vector.
Để tìm hiểu sâu hơn, hãy xem tài liệu của Mastra.
Ngăn xếp công nghệ cho dự án
- Khung Mastra để tạo ra các tác nhân và công cụ AI
- Upstash Redis để cung cấp bộ nhớ cuộc trò chuyện cho đại lý
- Vectơ nâng cao để lưu trữ phần đính kèm của bản tóm tắt bài viết nghiên cứu
- Next.js và Vercel để xây dựng và triển khai ứng dụng web
Chúng tôi cũng sẽ sử dụng Upstash Ratelimit để giới hạn các yêu cầu đối với ứng dụng demo của mình.
Hướng dẫn triển khai
Việc xây dựng ứng dụng này bao gồm việc tạo hai thành phần chính:máy chủ Mastra và ứng dụng web. Mặc dù chúng có thể ở trong cùng một dự án nhưng sẽ tốt hơn nếu tách chúng ra. Hãy bắt đầu với máy chủ Mastra.
Tạo dự án Mastra
Để tạo dự án Mastra mới, hãy chạy lệnh sau trong terminal của bạn.
npm create mastra@latestNó sẽ hỏi một vài câu hỏi; đối với dự án này, cài đặt mặc định là ổn.
Tạo tác nhân và công cụ
Bước đầu tiên trong việc định cấu hình một tác nhân là xác định tên, mục đích và công cụ của nó. Điều quan trọng nữa là chọn một mô hình ngôn ngữ sẽ hoạt động tốt cho các nhiệm vụ nhất định. Trong dự án này, chúng ta sẽ có một tác nhân và một công cụ.
export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
Việc cấu hình một tác nhân cũng đơn giản như được trình bày ở trên. Chúng tôi xác định articleAgent của mình với instruction (đóng vai trò là lời nhắc hệ thống), tools chuyên dụng của nó , model , và một thành phần quan trọng khác:memory .
Bộ nhớ của tác nhân
Mastra cung cấp cho các tổng đài viên cả lịch sử trò chuyện và khả năng thu hồi ngữ nghĩa. Bằng cách duy trì bộ nhớ trong bộ lưu trữ, tác nhân có thể cung cấp câu trả lời chính xác và được cá nhân hóa hơn. Hãy xem cấu hình bộ nhớ của tác nhân của chúng tôi.
export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
Để bật lịch sử trò chuyện, chúng tôi sử dụng Upstash Redis làm tùy chọn lưu trữ. Chúng tôi khởi tạo nó dưới dạng UpstashStore đối tượng mở rộng MastraStorage , đảm bảo nó hoạt động liền mạch với đại lý Mastra của chúng tôi.
export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});Trước đây chúng tôi đã đề cập đến việc thêm tính năng thu hồi ngữ nghĩa cho tác nhân của mình, tính năng này cho phép nó xem xét các thông báo trước đó liên quan đến bối cảnh hiện tại. Để làm được điều đó, tác nhân cần có cơ sở dữ liệu vectơ và trình nhúng để xử lý tin nhắn. Vì bản demo công khai của chúng tôi không dành cho mục đích sử dụng cá nhân và không cần ghi nhớ các tin nhắn trên các chuỗi khác nhau nên chúng tôi sẽ không sử dụng tính năng này nhưng có thể triển khai tính năng này như sau.
export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});Trong cấu hình thu hồi ngữ nghĩa, topK chỉ định số lượng tin nhắn tương tự cần truy xuất, messageRange xác định mức độ bối cảnh xung quanh cần đưa vào mỗi trận đấu và đặt phạm vi tới 'resource' thực hiện tìm kiếm tác nhân trên tất cả các chuỗi được liên kết với người dùng có tên 'resource'. Bộ nhớ đa luồng này là một tính năng mạnh mẽ có sẵn của Upstash.
Công cụ
Việc tạo một công cụ gần như đơn giản như việc tạo một tác nhân. Chúng tôi cung cấp tên, mô tả, lược đồ đầu vào và đầu ra cũng như một hàm để thực thi khi tác nhân cần khả năng của công cụ.
export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});Chúng tôi sử dụng Zod để xác thực các lược đồ đầu vào và đầu ra. Điều này giúp duy trì phản hồi nhất quán và giảm thiểu các lỗi tiềm ẩn từ LLM. Chúng tôi cũng xác định một chức năng cho công cụ này sử dụng. Công cụ của chúng tôi sẽ truy vấn một tập hợp lớn các bài báo nghiên cứu được cập nhật định kỳ thông qua API arXiv và được nhúng trong cơ sở dữ liệu Upstash Vector của chúng tôi.
const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
Chúng ta có thể thực hiện các thao tác đơn giản trên cơ sở dữ liệu vectơ của mình thông qua UpstashVector ví dụ mở rộng MastraVector . Ở trên, chúng tôi truy vấn các bản tóm tắt bài viết tương tự mà chúng tôi đã nhúng trước đó và trả về kết quả tốt nhất cho công cụ. Lưu ý rằng chúng tôi sử dụng cùng một mô hình nhúng cho truy vấn như đã làm cho các bài viết. Chúng tôi sẽ giải thích chi tiết hơn về cách nhúng bài viết sau.
Phiên bản Mastra
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
Chúng tôi chỉ cần chỉ định tác nhân nào sẽ sử dụng và Mastra của chúng tôi đối tượng đã sẵn sàng. Chúng tôi cũng cung cấp bộ lưu trữ để lưu trữ dữ liệu ngoài bộ nhớ trong. Bạn cũng có thể chọn từ các cấu hình triển khai có sẵn; chúng tôi sẽ triển khai bằng Vercel.
Với các tùy chọn mặc định từ create-mastra-app , chúng ta đã có cấu trúc file được yêu cầu:
.
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
Chỉ còn một bước nữa trước khi triển khai:các biến môi trường của chúng tôi.
OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
Đặt những thứ này vào .env.local của bạn để phát triển cục bộ và thêm chúng vào môi trường triển khai của bạn.
Bây giờ chúng tôi đã sẵn sàng xây dựng và triển khai máy chủ Mastra của mình.
npm run build && vercel --prodBạn có thể kiểm tra tài liệu Vercel để biết cách triển khai.
Trong khi phát triển, chúng tôi có thể sử dụng Mastra Playground để xem kết quả đầu ra của máy chủ. Chạy lệnh sau:
npm run devĐiều này sẽ cung cấp liên kết đến giao diện web nơi bạn có thể trò chuyện với nhân viên hỗ trợ của chúng tôi, chạy các công cụ một cách rõ ràng và khám phá các khả năng của máy chủ của chúng tôi.
Bây giờ là lúc nói về phần còn lại của ứng dụng.
Máy chủ Next.js
Sau khi máy chủ Mastra được thiết lập, chúng tôi cần xử lý ba việc:giao diện người dùng, giao tiếp với máy chủ Mastra và dịch vụ bài viết giao tiếp với API arXiv và nhúng phần tóm tắt vào Upstash Vector. Mastra có SDK khách để hiển thị các chức năng của máy chủ. Thông qua đó, bạn có thể truy cập các tác nhân, công cụ, bộ nhớ, v.v. Cách sử dụng của nó rất đơn giản nhưng chúng tôi sẽ chia sẻ một số ví dụ. Để biết thêm chi tiết, bạn có thể kiểm tra tài liệu ở đây. Trong dự án Next.js, bạn chỉ cần cài đặt và sử dụng SDK ứng dụng khách.
npm install @mastra/client-js@latest
Trong mã của bạn, hãy tạo một phiên bản MastraClient để sử dụng nó trong dự án của bạn.
import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
Bạn cần đặt NEXT_PUBLIC_MASTRA_API đến địa chỉ máy chủ Mastra của bạn. Nếu bạn đang phát triển cục bộ, đây sẽ là localhost địa chỉ. Vì có thể sẽ xảy ra xung đột cổng trên 3000 , bạn có thể thay đổi cấu hình của máy chủ Mastra khi chạy cục bộ như sau:
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
Bây giờ, khi chúng tôi chạy máy chủ Mastra cục bộ với npm run dev , nó được phục vụ tại cổng 4111 . Chúng ta có thể đặt NEXT_PUBLIC_MASTRA_API đến http://localhost:4111 khi chúng tôi chạy dự án Next.js cục bộ.
Hãy xem cách chúng tôi có thể sử dụng SDK khách của Mastra.
export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});Bạn có thể nhận các công cụ và tác nhân của mình và khi có chúng, bạn có thể thực hiện hầu hết mọi việc bạn có thể làm với các đối tượng thực tế thông qua SDK khách.
Vì chúng tôi sẽ xuất bản dự án demo này một cách công khai nên điều quan trọng là tránh gây gánh nặng cho đại lý. Đây là lúc Upstash Ratelimit xuất hiện. Trước mỗi yêu cầu phát trực tiếp, chúng tôi sẽ kiểm tra xem người dùng có bị giới hạn tốc độ hay không. Để định cấu hình bộ giới hạn tốc độ, chúng tôi sẽ cần Upstash Redis. Chúng tôi có thể sử dụng cùng cơ sở dữ liệu Redis mà chúng tôi có cho đại lý Mastra của mình.
import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}Bằng cách này, chúng tôi đảm bảo rằng các điểm cuối của chúng tôi sẽ không phải chịu tải nặng.
Khi tạo tác nhân trò chuyện bằng Mastra, việc biết một số tính năng tạo chuỗi của Mastra có thể hữu ích. Hãy nhớ rằng khi định cấu hình bộ nhớ cho tác nhân, chúng tôi đã đặt generateTitle tới true trong threads đối tượng. Điều này làm cho Mastra tự động tạo tiêu đề cho các chủ đề mới được tạo. Nhưng đây là điểm đáng chú ý:có thể tạo một chủ đề một cách rõ ràng, nhưng việc tạo tiêu đề tự động không được kích hoạt theo cách đó. Thông thường cách tạo thread mới như sau:
const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
Tuy nhiên, điều này sẽ làm mất khả năng tự động tạo tiêu đề của tác nhân vì bạn đang cài đặt nó theo cách thủ công. Rời khỏi title trường trống cũng không hoạt động. Trong trường hợp này, chúng ta có thể thấy Playground làm gì. Bạn có nhớ Playground do Mastra cung cấp để trải nghiệm các khả năng của máy chủ của bạn trong quá trình phát triển không? Nếu chúng tôi kiểm tra tab mạng trong công cụ dành cho nhà phát triển của trình duyệt, chúng tôi sẽ thấy rằng khi một chuỗi mới được tạo, nó không thực sự gửi yêu cầu API để tạo chuỗi đó. Thay vào đó, nó chờ bạn gửi tin nhắn đầu tiên. Sau đó, nó sẽ gửi một yêu cầu truyền phát có ID luồng mới được tạo. Điều này cho Mastra biết rằng không có luồng nào tồn tại với ID này, vì vậy nó sẽ tạo một luồng và nếu generateTitle là đúng, hãy tạo tiêu đề dựa trên tin nhắn đầu tiên.
Hãy tiếp tục với thành phần cuối cùng của dự án của chúng ta:các bài viết về arXiv.
Bài viết arXiv
arXiv là kho lưu trữ truy cập mở chứa gần 2,4 triệu bài báo nghiên cứu trong nhiều lĩnh vực khác nhau. articleQueryTool truy vấn cơ sở dữ liệu Upstash Vector, được cung cấp bởi các bài viết được tìm nạp qua API arXiv. API rất dễ sử dụng; bạn có thể tìm thêm thông tin chi tiết tại đây.
Trong dự án của chúng tôi, chúng tôi tìm nạp và lưu trữ các bài viết hàng ngày. Lần đầu tiên máy chủ chạy, nó lấy khoảng 30.000 bài viết từ các danh mục được chỉ định. Sau đó, nó lấy các bài viết mới được xuất bản vào ngày hôm trước. Để chỉ định danh mục bài viết và liệu có tìm nạp lô lớn ban đầu hay không, chúng tôi đặt các biến môi trường tương ứng. Chúng ta nên cung cấp các danh mục bài viết mong muốn bằng cách sử dụng phân loại của arXiv, được phân tách bằng dấu phẩy. Bạn có thể tra cứu các danh mục tại đây.
CATEGORIES=cs.AI
RUN_BEGINNING_STACK=falseNếu muốn có cơ sở dữ liệu toàn diện hơn, bạn có thể sử dụng tính năng truy cập dữ liệu hàng loạt của arXiv. Nếu không có nó, chúng tôi bị giới hạn ở 30.000 bài viết cho mỗi truy vấn API, đủ cho mục đích của chúng tôi.
Một truy vấn đơn giản tới arXiv trông như thế này:
const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.Chúng tôi thực hiện các lệnh gọi tương tự để nhận các bài viết mới nhất mỗi ngày và tìm nạp ngăn xếp ban đầu.
Sau khi tìm nạp các bài viết, chúng tôi chuẩn hóa chúng và nhúng chúng để lưu trữ trong Upstash Vector. Đây phải là cơ sở dữ liệu vectơ giống như công cụ Mastra của chúng tôi sử dụng. Khi nói "chuẩn hóa", chúng tôi muốn phân tích cú pháp các bài viết được tìm nạp thành ArxivPaper tiêu chuẩn loại mà chúng tôi sẽ sử dụng trong toàn bộ cơ sở mã của mình.
export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}Để đảm bảo cơ sở dữ liệu của chúng tôi luôn cập nhật với nghiên cứu mới nhất, chúng tôi triển khai Upstash QStash để thực thi tác vụ theo lịch trình. Với việc triển khai trên Vercel, chúng tôi cần ngăn chặn thời gian chờ chức năng có thể xảy ra với khoảng thời gian xử lý kéo dài. Chúng tôi giải quyết vấn đề này bằng cách hiển thị điểm cuối API công khai trên máy chủ của chúng tôi, cho phép phiên bản QStash của chúng tôi kích hoạt chức năng cập nhật cơ sở dữ liệu hàng ngày một cách đáng tin cậy.
// src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)Bạn có thể định cấu hình bộ lập lịch thông qua Bảng điều khiển Upstash để tự động kích hoạt các yêu cầu tới điểm cuối này hàng ngày vào lúc 6:00 sáng UTC.
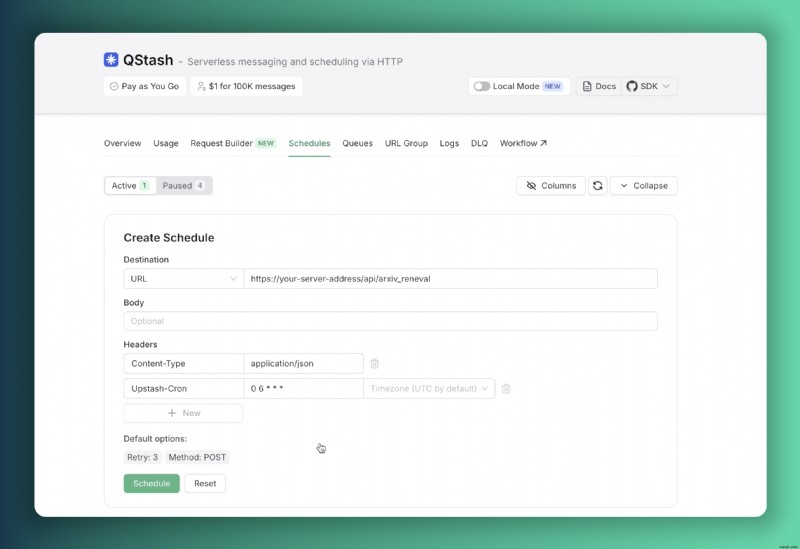
Với cấu hình bộ lập lịch này, máy chủ của chúng tôi sẽ thực hiện cập nhật cơ sở dữ liệu tự động mỗi sáng, đảm bảo dữ liệu luôn mới.
Chúng tôi cũng nên cung cấp thông tin xác thực cho phiên bản QStash của mình, tất cả các biến env bắt buộc đều được cung cấp trong tệp env mẫu.
Đó là khá nhiều nó. Nếu muốn, bạn có thể thử và chơi đùa với mã. Chỉ cần phân nhánh các kho lưu trữ và bắt đầu phát triển. Bạn có thể vào kho lưu trữ của phần Mastra tại đây và kho lưu trữ khác tại đây. Sau khi phân nhánh chúng:
- Sao chép chúng vào máy cục bộ của bạn.
- Điền các biến môi trường của bạn (ví dụ
.envcác tập tin được cung cấp). - Chuyển đến thư mục gốc cho cả hai dự án trong các thiết bị đầu cuối riêng biệt.
- Chạy các lệnh sau:
npm install
npm run devBây giờ bạn có thể xem đơn đăng ký của mình tại http://localhost:3000.
Với Mastra, bạn có thể xây dựng những thứ phức tạp hơn bằng cách sử dụng các mẫu khác của nó như RAG, quy trình công việc và mạng. Có vẻ như bộ nhớ và bộ lưu trữ đóng một vai trò quan trọng trong tất cả các mục đích này. Đây là nơi Upstash tỏa sáng.