Bạn có bao giờ nhận thấy hộp tìm kiếm gợi ý các từ khi bạn nhập không? Hóa ra, hầu hết những đề xuất này đều hiển thị theo thứ tự bảng chữ cái đơn giản và không hữu ích lắm.
Nhưng điều gì sẽ xảy ra nếu hộp tìm kiếm có thể trở nên thông minh hơn theo thời gian?
Tìm hiểu từ những gì mọi người thực sự nhấp vào và hiển thị các kết quả phổ biến nhất trước tiên?
Đây là những gì chúng tôi sẽ xây dựng:
Chúng ta sẽ xem cách Redis Sorted Sets có thể hỗ trợ một hệ thống tự động hoàn thành thông minh học hỏi từ hành vi của người dùng và trở nên chính xác hơn (hiển thị các kết quả phổ biến trước tiên) theo thời gian.
Ý tưởng về hệ thống tự động hoàn thành thông minh
Hộp tìm kiếm cơ bản sẽ sử dụng phương pháp gọi là khớp tiền tố để quyết định kết quả nào sẽ hiển thị đầu tiên.
Khi bạn nhập, nó sẽ hiển thị các kết quả khớp theo thứ tự A-Z. Nó thực sự không quan tâm đến kết quả nào mọi người thực sự nhấp vào nhiều nhất.
Chúng tôi sẽ làm cho nó thông minh hơn. Hộp tìm kiếm của chúng tôi sẽ tìm hiểu từ những gì mọi người chọn . Khi mọi người nhấp vào kết quả tìm kiếm, chúng tôi sẽ hiển thị kết quả đó đầu tiên vào lần tiếp theo.
Điều này có nghĩa là tìm kiếm của chúng tôi ngày càng tốt hơn và hữu ích hơn bằng cách tự động hiển thị các kết quả phổ biến nhất ở trên cùng.
Tại sao điều này lại quan trọng đối với các ứng dụng tìm kiếm
Hãy xem xét một ứng dụng tìm kiếm phim:khi người dùng gõ "int". Họ có thể thấy:
- "Đánh chặn"
- "Xa lộ tiểu bang 60"
- "Liên vì sao"
Trong hệ thống "truyền thống", chúng sẽ xuất hiện theo thứ tự bảng chữ cái. Tuy nhiên, nếu người dùng liên tục nhấp vào "Interstellar", chúng tôi muốn quảng bá nó lên đầu các đề xuất tự động hoàn thành.
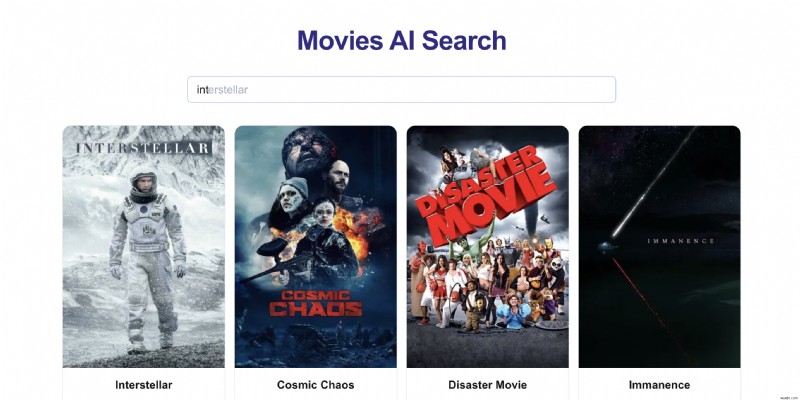
Hệ thống xếp hạng thông minh này hoạt động thực sự hiệu quả đối với:
- Dịch vụ phát trực tuyến như Netflix hoặc YouTube để hiển thị nội dung mọi người đang xem nhiều nhất
- Cửa hàng trực tuyến để hiển thị các sản phẩm phổ biến đầu tiên khi tìm kiếm
- Trung tâm trợ giúp để hiển thị những câu hỏi phổ biến nhất mà mọi người hỏi
- Bất kỳ trang web nào có tìm kiếm để hiển thị nội dung mà hầu hết mọi người nhấp vào đầu tiên
Tìm hiểu về các bộ được sắp xếp bằng Redis
Hãy hiểu tại sao Bộ sắp xếp Redis lại tuyệt vời để xây dựng hệ thống tự động hoàn thành.
Bộ sắp xếp Redis giống như một danh sách thông minh trong đó:
- Mỗi món đồ là duy nhất (như một bộ)
- Mỗi món đều có một điểm (để đặt hàng)
- Các mục có thể được sắp xếp nhanh chóng theo điểm số
Đối với hệ thống tự động hoàn thành của chúng tôi, chúng tôi sẽ sử dụng hai bộ được sắp xếp:
- Một để khớp tiền tố văn bản (ví dụ:"int" khớp với "interstellar")
- Một cách khác để theo dõi mức độ phổ biến của từng đề xuất
Hai bộ này phối hợp với nhau để đề xuất những kết quả phù hợp nhất khi người dùng nhập.
Nền tảng:Thứ tự bảng chữ cái
Bộ sắp xếp Redis duy trì thứ tự bảng chữ cái khi tất cả các thành viên có cùng số điểm. Điều này hoàn hảo cho việc xây dựng đề xuất tìm kiếm vì nó cho phép chúng tôi:
- Lưu trữ tất cả tiền tố các thuật ngữ có thể tìm kiếm trong một cấu trúc dữ liệu
- Sử dụng
ZRANKđể tìm vị trí bắt đầu của bất kỳ tiền tố nào trong thời gian O(log N) - Sử dụng
ZSCANđể truy xuất hiệu quả tất cả các kết quả phù hợp bắt đầu từ vị trí đó - Sử dụng
ZMSCOREđể có được điểm phổ biến của mỗi trận đấu - Sử dụng
ZINCRBYđể tăng điểm phổ biến của mỗi trận đấu
Hãy xem xét một ví dụ đơn giản. Khi chúng tôi thêm phim "INTERSTELLAR" vào hệ thống tìm kiếm của mình, chúng tôi chia nhỏ phim như thế này:
- Điểm:0, Thành viên:"Tôi"
- Điểm:0, Thành viên:"IN"
- Điểm:0, Thành viên:"INT"
- Điểm:0, Thành viên:"INTE"
- Điểm:0, Thành viên:"INTER"
- Điểm:0, Thành viên:"INTERSTELLAR$Interstellar" (hoàn thành mục nhập với định dạng hiển thị)
Xem cách chúng tôi sử dụng $ để tách phiên bản tìm kiếm khỏi phiên bản hiển thị? Bằng cách này, người dùng có thể tìm kiếm mà không cần lo lắng về chữ hoa hoặc chữ thường, nhưng chúng tôi vẫn hiển thị tiêu đề phim chính xác như thế nào.
Cách chúng tôi lưu trữ dữ liệu
Chúng tôi sử dụng hai bộ được sắp xếp Redis để thực hiện công việc tự động hoàn thành:
1. Danh sách tựa phim
Hãy theo dõi một tập hợp được sắp xếp có tên movies . Hãy coi điều này giống như một cuốn từ điển giúp chúng ta tìm phim nhanh chóng. Khi ai đó gõ "int", chúng tôi có thể tìm thấy ngay tất cả các phim bắt đầu bằng những chữ cái đó.
Lần xuất hiện đầu tiên của "int" sẽ được tìm thấy bởi ZRANK và sau đó bắt đầu từ vị trí đó tên phim đầy đủ với ký tự đại diện INT*$* sẽ được tìm nạp.
2. Danh sách phim nổi tiếng
Chúng ta cũng hãy theo dõi một tập hợp được sắp xếp có tên movie-popularity . Đây là danh sách "phim thịnh hành" của chúng tôi.
Mỗi khi ai đó nhấp vào một bộ phim trong kết quả tìm kiếm, bộ phim đó sẽ trở nên phổ biến hơn bằng cách tăng điểm bằng cách sử dụng ZINCRBY . Những bộ phim được nhấp chuột nhiều nhất sẽ hiển thị đầu tiên trong các tìm kiếm trong tương lai.
Giống như cách Netflix hiển thị cho bạn những bộ phim thịnh hành - càng có nhiều người xem nội dung nào đó thì nội dung đó càng xuất hiện cao hơn trong danh sách đề xuất.
Trong trường hợp của chúng tôi, sau khi tìm ra kết quả khớp chính xác cho INT*$* , chúng ta đi kiểm tra điểm số của họ tại movie-popularity để có được những cái phổ biến nhất.
Luồng thuật toán
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> AKhi người dùng tìm kiếm và nhấp vào đề xuất, hệ thống sẽ tìm hiểu và cải thiện. Càng nhiều người sử dụng thì nó càng hiển thị tốt hơn những đề xuất phù hợp nhất trước tiên.
Hãy xây dựng hệ thống tự động hoàn thành
Hãy xem cách chúng tôi xây dựng hệ thống tự động hoàn thành này từng bước một. Chúng tôi sẽ làm mọi việc thật đơn giản!
Bước 1:Thêm tiêu đề phim vào Redis
Đầu tiên, chúng ta cần thêm tựa phim của mình vào Redis để có thể tìm kiếm chúng sau này. Bạn có thể bắt đầu với một danh sách phim đơn giản từ mọi nơi - có thể là cơ sở dữ liệu của bạn hoặc chỉ là một tệp văn bản. Đây là cách chúng tôi thêm chúng:
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();Hãy cùng phân tích chức năng của đoạn mã trên:
-
Đối với mỗi tựa phim, chúng tôi lưu trữ:
- Tất cả các kết quả khớp một phần có thể có (như "INT", "INTE", "INTER" cho "Interstellar")
- Tiêu đề đầy đủ
- Phiên bản được định dạng để hiển thị
-
Chúng tôi cũng tạo một danh sách riêng để theo dõi mức độ phổ biến của từng bộ phim, bắt đầu từ số lượt xem bằng 0
Điều này cung cấp cho chúng tôi mọi thứ chúng tôi cần để hiển thị các đề xuất thông minh khi người dùng nhập và tìm hiểu từ nội dung họ nhấp vào.
Bước 2:Tìm kết quả phù hợp nhất
Tiếp theo, chúng ta sẽ xem cách chúng ta tìm kiếm thông qua các tựa phim này để tìm kết quả phù hợp. matchQuery của chúng tôi chức năng thực hiện tất cả các công việc nặng nhọc:
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};Học hỏi từ lựa chọn của người dùng
Khi ai đó chọn tên phim, chúng tôi cộng 1 điểm vào điểm của phim. Phim có nhiều điểm hơn sẽ hiển thị cao hơn trong danh sách gợi ý. Thật đơn giản!
Hệ thống ngày càng thông minh hơn bằng cách theo dõi những gì mọi người thực sự chọn.
const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};Nó nhanh như thế nào?
Hãy xem giải pháp này nhanh như thế nào bằng cách chia nhỏ thời gian thực hiện của mỗi thao tác:
- ZRANK :O(log N) - Thời gian tra cứu logarit
- ZSCAN :O(log N + M) - Trong đó M là số phần tử trả về
- ZMSCORE :O(N) - Trong đó N là số kết quả trùng khớp, không phải tổng kích thước tập dữ liệu
- ZINCRBY :O(log N) - Gia số nguyên tử với độ phức tạp logarit
Khi chúng tôi thêm nhiều tựa phim hơn, hiệu suất vẫn ổn định.
Kết luận:Những gì chúng ta đã cùng nhau xây dựng
Bạn vừa học cách xây dựng hộp tìm kiếm thông minh ngày càng tốt hơn mà không cần bất kỳ AI nào!
Tính năng tự động hoàn thành của chúng tôi tìm hiểu từ những gì mọi người chọn và sử dụng thông tin đó để hiển thị các đề xuất tốt hơn.
Nó nhanh chóng, đơn giản và trở nên hữu ích hơn khi có nhiều người sử dụng hơn.
Bạn muốn nói về chiến lược tối ưu hóa Redis hoặc chia sẻ cách triển khai của riêng bạn? Hãy tham gia cùng chúng tôi trên Discord!