Vấn đề:
Một trong những vấn đề khó khăn nhất đối với một chuyên gia phân tích dữ liệu là thu thập dữ liệu. Trong khi thực tế là có rất nhiều dữ liệu có sẵn trên web, nó chỉ là trích xuất dữ liệu thông qua tự động hóa.
Giới thiệu ..
Tôi muốn trích xuất dữ liệu hoạt động cơ bản được nhúng trong bảng HTML từ https://www.tutorialspoint.com/python/python_basic_operators.htm.
Hmmm, Dữ liệu nằm rải rác trong nhiều bảng HTML, nếu chỉ có một bảng HTML rõ ràng tôi có thể sử dụng Sao chép &Dán vào tệp .csv.
Tuy nhiên, nếu có hơn 5 bảng trong một trang thì rõ ràng đó là một điều khó khăn. Phải không?
Cách thực hiện ..
1.Tôi sẽ nhanh chóng chỉ cho bạn cách tạo tệp csv một cách dễ dàng nếu bạn muốn tạo tệp csv.
import csv
# Open File in Write mode , if not found it will create one
File = open('test.csv', 'w+')
Data = csv.writer(File)
# My Header
Data.writerow(('Column1', 'Column2', 'Column3'))
# Write data
for i in range(20):
Data.writerow((i, i+1, i+2))
# close my file
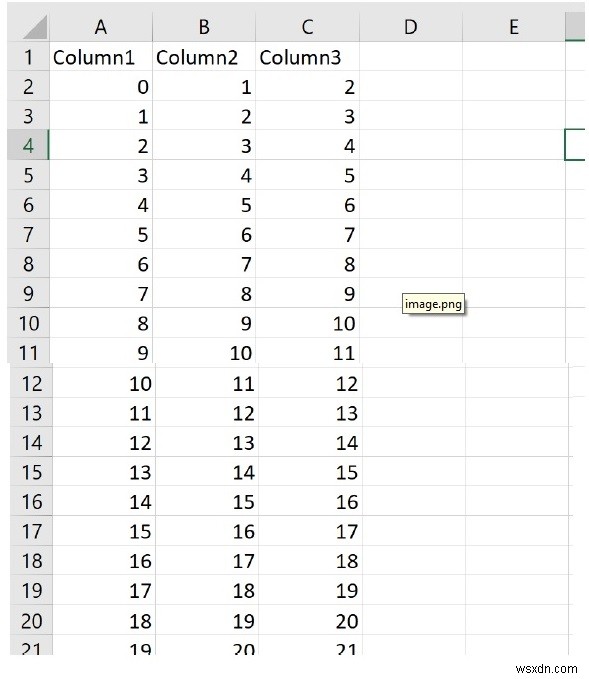
File.close() Đầu ra
Đoạn mã trên khi được thực thi sẽ tạo ra tệp test.csv có trong cùng thư mục với mã này.
2. Bây giờ, hãy để chúng tôi truy xuất bảng HTML từ https://www.tutorialspoint.com/python/python_dictionary.htm và viết nó dưới dạng tệp CSV.
Bước đầu tiên là nhập khẩu.
import csv from urllib.request import urlopen from bs4 import BeautifulSoup url = 'https://www.tutorialspoint.com/python/python_dictionary.htm'
-
Mở tệp HTML và lưu trữ trong đối tượng html bằng cách sử dụng urlopen.
Đầu ra
html = urlopen(url) soup = BeautifulSoup(html, 'html.parser')
-
Tìm các bảng bên trong bảng html và Hãy để chúng tôi cung cấp dữ liệu bảng. Với mục đích trình diễn, tôi sẽ chỉ trích xuất bảng đầu tiên [0]
Đầu ra
table = soup.find_all('table')[0]
rows = table.find_all('tr') Đầu ra
print(rows)
Đầu ra
[<tr> <th style='text-align:center;width:5%'>Sr.No.</th> <th style='text-align:center;width:95%'>Function with Description</th> </tr>, <tr> <td class='ts'>1</td> <td><a href='/python/dictionary_cmp.htm'>cmp(dict1, dict2)</a> <p>Compares elements of both dict.</p></td> </tr>, <tr> <td class='ts'>2</td> <td><a href='/python/dictionary_len.htm'>len(dict)</a> <p>Gives the total length of the dictionary. This would be equal to the number of items in the dictionary.</p></td> </tr>, <tr> <td class='ts'>3</td> <td><a href='/python/dictionary_str.htm'>str(dict)</a> <p>Produces a printable string representation of a dictionary</p></td> </tr>, <tr> <td class='ts'>4</td> <td><a href='/python/dictionary_type.htm'>type(variable)</a> <p>Returns the type of the passed variable. If passed variable is dictionary, then it would return a dictionary type.</p></td> </tr>]
5.Bây giờ chúng tôi sẽ ghi dữ liệu vào tệp csv.
Ví dụ
File = open('my_html_data_to_csv.csv', 'wt+')
Data = csv.writer(File)
try:
for row in rows:
FilteredRow = []
for cell in row.find_all(['td', 'th']):
FilteredRow.append(cell.get_text())
Data.writerow(FilteredRow)
finally:
File.close() 6.Kết quả hiện được lưu vào tệp my_html_data_to_csv.csv.
Ví dụ
Chúng tôi sẽ tổng hợp mọi thứ được giải thích ở trên lại với nhau.
Ví dụ
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
# set the url..
url = 'https://www.tutorialspoint.com/python/python_basic_syntax.htm'
# Open the url and parse the html
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
# extract the first table
table = soup.find_all('table')[0]
rows = table.find_all('tr')
# write the content to the file
File = open('my_html_data_to_csv.csv', 'wt+')
Data = csv.writer(File)
try:
for row in rows:
FilteredRow = []
for cell in row.find_all(['td', 'th']):
FilteredRow.append(cell.get_text())
Data.writerow(FilteredRow)
finally:
File.close() Bảng trong trang html.