Tôi chưa có con, nhưng khi có con, tôi muốn chúng học được hai điều:
- Tài chính cá nhân
- Máy học
Cho dù bạn có tin rằng điểm kỳ dị gần kề hay không, không thể phủ nhận rằng thế giới chạy trên dữ liệu. Hiểu cách dữ liệu đó được chuyển hóa thành kiến thức là rất quan trọng đối với bất kỳ ai đến tuổi ngày nay - và thậm chí còn hơn thế nữa đối với các nhà phát triển.
Đây là bài viết đầu tiên trong loạt bài sẽ cố gắng làm cho việc học máy (ML) có thể truy cập được đối với các nhà phát triển Ruby đầy đủ. Bằng cách hiểu các công cụ ML theo ý của bạn, bạn sẽ có thể giúp các bên liên quan của mình đưa ra quyết định tốt hơn. Các bài viết trong tương lai sẽ tập trung vào các kỹ thuật riêng lẻ và các ví dụ thực tế, nhưng trong bài này, chúng tôi đang tạo tiền đề - hiển thị cho bạn bản đồ và đặt một ghim cho biết "bạn đang ở đây".
Khởi đầu khiêm tốn

Trí tuệ nhân tạo (AI) và máy học không có gì mới. Quay trở lại những năm 1950, Arthur Samuel đã xây dựng một chương trình máy tính có thể chơi cờ caro. Ông đã sử dụng "alpha-beta trimning" - một thuật toán tìm kiếm phổ biến.
Những năm 1960 đã chứng kiến sự ra đời của mạng nơ-ron nhiều lớp và thuật toán láng giềng gần nhất, được sử dụng để tìm ra khả năng xử lý tối ưu trong các nhà kho.
Vậy nếu AI đã quá cũ thì tại sao các công ty khởi nghiệp AI lại trở nên hợp thời? Theo tôi, có hai lý do cho điều này:
- Sức mạnh tính toán (xem Định luật Moore)
- Lượng dữ liệu được thêm vào internet mỗi ngày
Có hai số liệu thống kê liên quan đến lượng dữ liệu được tạo ra hàng ngày khiến tôi suy nghĩ mỗi khi nghĩ về chúng:
- Tính đến năm 2018, chúng tôi đang sản xuất 2,5 nghìn tỷ byte dữ liệu mỗi ngày. Không nghi ngờ gì nữa, con số này chỉ tăng lên kể từ khi bài báo Forbes này được xuất bản.
- Chỉ trong hai năm qua, 90% dữ liệu trên thế giới đã được tạo.
Cùng với nhau, điều này có nghĩa là (1) phần cứng cần thiết để lưu trữ dữ liệu và chạy các thuật toán tiếp tục trở nên hợp lý hơn và (2) lượng dữ liệu có sẵn để đào tạo các mô hình ML đang tăng lên với tốc độ cực nhanh.
Hàng ngày chúng ta đang tương tác, chịu ảnh hưởng và đóng góp vào thế giới trí tuệ nhân tạo và máy học. Ví dụ:bạn có thể cảm ơn (hoặc đổ lỗi) cho các thuật toán vì những điều sau:
- Hạn mức tín dụng của bạn
- Giúp chẩn đoán bệnh
- Thậm chí có thể bạn đã nhận được công việc hay chưa
- Giúp bạn tìm tuyến đường hiệu quả nhất với điều kiện giao thông hiện tại
- Alexa hiểu chính xác ý của bạn khi bạn nói với cô ấy rằng bạn vừa hắt hơi
- Spotify giới thiệu với bạn bài hát yêu thích mới của bạn
Lý do tôi đưa ra giả thuyết về những đứa trẻ trong tương lai của mình là:Tôi muốn chúng hiểu cuộc sống kỹ thuật số ảnh hưởng như thế nào đến cuộc sống "thực" của chúng, tác động của các quyết định về quyền riêng tư dữ liệu của chúng và cách hình thành ý kiến của riêng chúng về thời điểm chúng nên tin tưởng vào máy so với khi nào họ không nên.
Trong phần còn lại của bài đăng này, tôi muốn giới thiệu tổng quan về ba loại học máy mà tôi đã nghiên cứu:học có giám sát, học không giám sát và học tăng cường. Chúng ta sẽ nói về điều gì làm cho mỗi cách tiếp cận trở nên độc đáo và các vấn đề mà mỗi cách giải quyết đều đặc biệt tốt.
Học tập có Giám sát
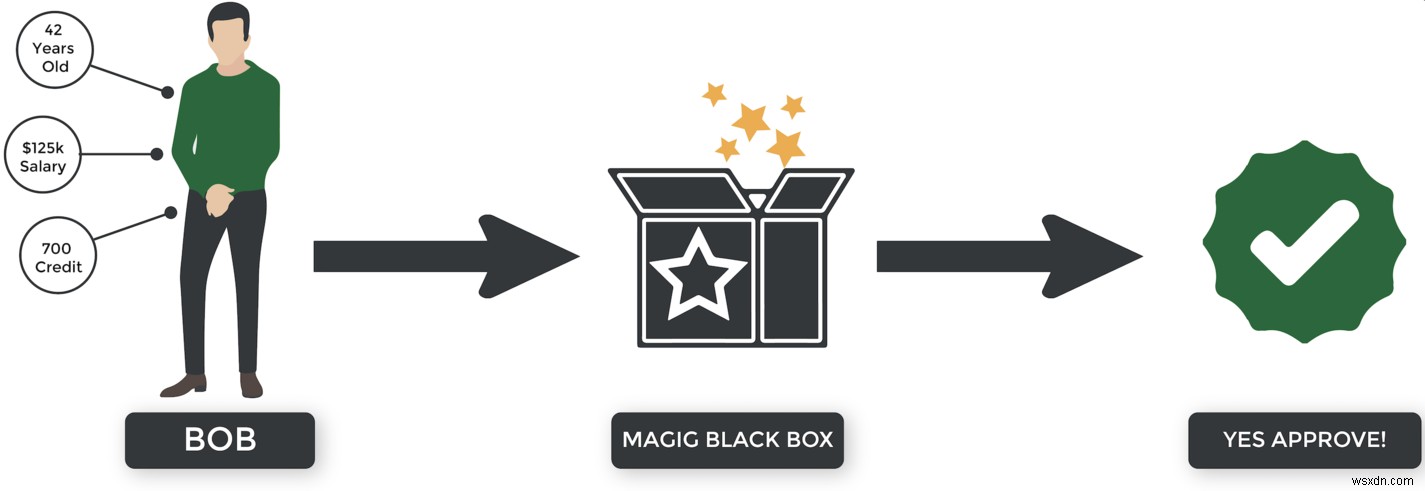
Học tập có giám sát là ... tốt, được giám sát bởi con người. :) Hãy tưởng tượng rằng chúng ta đang xây dựng một hệ thống học tập có giám sát để quyết định xem ai được chấp thuận cho vay thế chấp. Đây là cách nó có thể hoạt động:
- Ngân hàng biên soạn một tập dữ liệu ánh xạ các thuộc tính của khách hàng (tuổi, lương, v.v.) với kết quả (trả nợ, vỡ nợ, v.v.).
- Chúng tôi đào tạo hệ thống của mình bằng cách sử dụng dữ liệu.
- Hệ thống sử dụng những gì nó học được để đoán kết quả trong tương lai dựa trên các thuộc tính của người đăng ký.
- Nếu thuật toán đoán đúng, chúng tôi sẽ nói với nó, "Làm tốt lắm! Bạn nói đúng." Nhưng nếu nó sai, chúng tôi nói với nó, "Không, bạn không chính xác. Vui lòng cải thiện và thử lại."
Ví dụ này được coi là một vấn đề "phân loại" vì đầu ra của thuật toán là một danh mục - trong trường hợp này, được chấp thuận hoặc không được chấp thuận. Các ví dụ khác về vấn đề phân loại bao gồm quyết định có hay không:
- một người bị bệnh
- chụp X-quang có một đoạn xương bị gãy
- một e-mail là spam
Nếu bạn tò mò muốn tìm hiểu thêm về toán học đằng sau các thuật toán phân loại ML, hãy Google bất kỳ thứ nào trong số này:bộ phân loại Bayes ngây thơ, máy vectơ hỗ trợ, hồi quy logistic, mạng nơ-ron, rừng ngẫu nhiên.
Ngoài các vấn đề phân loại đưa ra kết quả "có / không", học có giám sát cũng có thể được sử dụng để giải quyết các vấn đề hồi quy - ở đây, chúng tôi đưa ra dự đoán trên thang đo liên tục, ví dụ:
- giá trị tương lai của cổ phiếu
- xác suất để những người yêu nước ở New England giành chiến thắng trong Super Bowl
- mức lương trung bình mà một công ty cần đưa ra để một ứng viên chấp nhận
Ví dụ về các thuật toán được sử dụng cho các bài toán hồi quy có giám sát bao gồm hồi quy tuyến tính, hồi quy phi tuyến tính và hồi quy tuyến tính Bayes.
Học không được giám sát
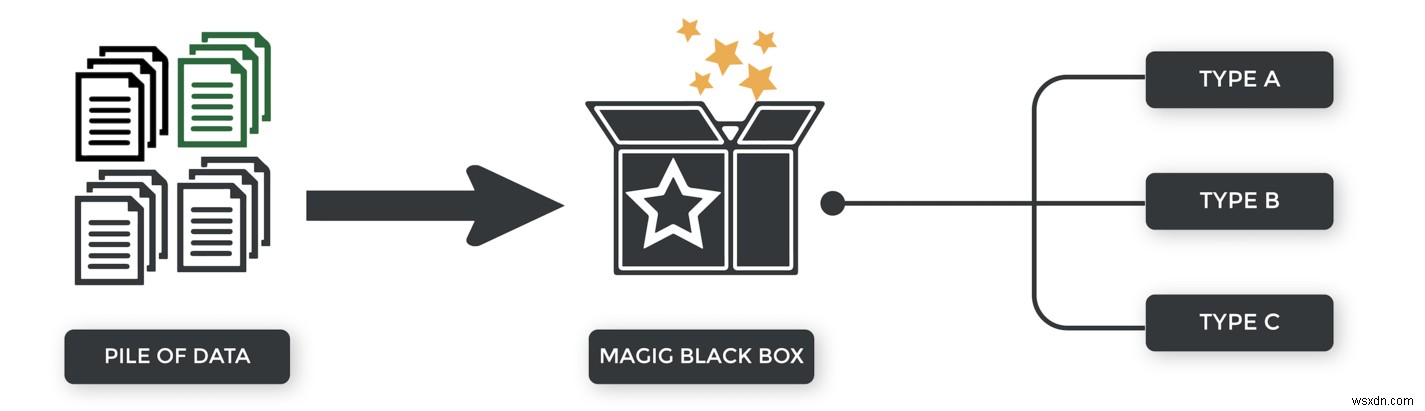
Với ví dụ học tập có giám sát của chúng tôi, chúng tôi đã xác định trước các danh mục phân loại. Người nộp đơn thế chấp đã được chấp thuận hoặc bị từ chối.
Với việc học tập không có giám sát, chúng tôi không cung cấp các danh mục. Chúng không có sẵn cho chúng tôi. Thuật toán phải đưa ra kết luận của riêng nó.
Tại sao chúng ta muốn sử dụng phương pháp không giám sát?
1) Đôi khi chúng ta không biết trước các danh mục. Phần lớn dữ liệu trôi nổi trên internet là không có cấu trúc - tức là thiếu nhãn.
2) Trong trường hợp khác, chúng tôi không biết mình đang tìm kiếm gì, vì vậy chúng tôi có thể yêu cầu thuật toán tìm các mẫu / tính năng có thể hữu ích cho việc phân loại.
Một cách khác để xử lý dữ liệu phi cấu trúc với máy học là chỉ cần con người nhìn vào nó và gắn nhãn thủ công. Có rất nhiều công ty thuê nhân công phân loại dữ liệu theo cách thủ công:ghi nhãn dữ liệu.
Phương pháp tiếp cận phương pháp học tập không được giám sát
Hai kỹ thuật thường được sử dụng trong học tập không giám sát là liên kết và phân cụm .
Liên kết: Hãy tưởng tượng rằng bạn là Amazon. Bạn có nhiều dữ liệu khách hàng, lịch sử mua hàng, v.v. Bằng cách sử dụng phương pháp học không giám sát, bạn có thể phân chia khách hàng thành "loại người mua hàng" - có thể phát hiện ra rằng những người mua ô màu hồng có nhiều khả năng cũng mua trà Matcha hơn.
Nhóm: Phân cụm xem xét dữ liệu của bạn và phân vùng dữ liệu đó thành một số nhóm hoặc cụm cụ thể. Ví dụ:có thể bạn có một loạt dữ liệu về nhà ở và bạn muốn xem liệu có bất kỳ tính năng nào (có thể là dữ liệu tội phạm?) Có thể dự đoán khu vực lân cận ngôi nhà đó hay không. Hoặc, có thể sử dụng các kỹ thuật như tương tự cosine để phân loại văn bản ( ví dụ:bài viết này về quần vợt, nấu ăn hay không gian?).
Nếu bạn muốn tìm hiểu thêm về các kỹ thuật học tập không có giám sát cụ thể, hãy tìm kiếm Google phân cụm k-mean, tính tương tự cosine, phân cụm phân cấp và phân cụm k-hàng xóm gần nhất.
Học củng cố

Tập hợp con của học máy này thường được sử dụng trong các trò chơi vì nó sử dụng các thuật toán hướng đến mục tiêu. Không giống như học có giám sát, mỗi quyết định KHÔNG độc lập - với đầu vào hiện tại, thuật toán đưa ra quyết định và đầu vào tiếp theo phụ thuộc vào quyết định này .
Giống như việc tôi vỗ nhẹ vào đầu con chó của mình khi nó ngừng sủa liên tục khi chuông cửa reo hoặc đưa nó vào cũi khi nó không đóng cửa, các thuật toán tăng cường sẽ được thưởng khi đưa ra quyết định tối ưu hóa mục tiêu (ví dụ:ghi điểm số điểm tối đa) và bị phạt khi làm bài kém.
Các ứng dụng rõ ràng cho các thuật toán học tăng cường bao gồm:
- các trò chơi như cờ vua và cờ vây (Tôi thực sự khuyên bạn nên xem phim tài liệu về AlphaGo trên Netflix, nếu bạn chưa xem.)
- robot (dạy bot hoàn thành các nhiệm vụ mong muốn)
- xe tự hành
- cố vấn rô-bốt được đào tạo để đánh bại thị trường chứng khoán
Nếu bạn quan tâm đến việc tìm hiểu thêm về các thuật toán đằng sau việc học tăng cường, hãy tìm kiếm Google Q-learning, state-action-khen thưởng-state-action (SARSA), DQN và nhà phê bình tác nhân lợi thế không đồng bộ.
Kết luận
Tôi hy vọng rằng những ví dụ này đã giúp bạn nắm bắt được các kỹ thuật học máy và cách chúng được sử dụng để ảnh hưởng đến thế giới điên rồ mà chúng ta đang sống ngày nay. Mặc dù đôi khi tôi thấy mình bị choáng ngợp với tất cả những gì phải học, nhưng bắt đầu từ một nơi nào đó tốt hơn là không làm gì cả và hãy nhớ rằng phần lớn điều này thực sự không mới lắm - chúng ta chỉ đang nghe về nó nhiều hơn khi dữ liệu trở nên sẵn có hơn và xử lý điện rẻ hơn.