Đó là đã nói đúng rằng dữ liệu là tiền trong thế giới ngày nay. Cùng với quá trình chuyển đổi sang thế giới dựa trên ứng dụng là sự tăng trưởng dữ liệu theo cấp số nhân. Tuy nhiên, hầu hết dữ liệu không có cấu trúc và do đó, cần có một quy trình và phương pháp để trích xuất thông tin hữu ích từ dữ liệu và biến nó thành dạng dễ hiểu và có thể sử dụng được.
Khai thác dữ liệu hay “Khám phá tri thức trong cơ sở dữ liệu” là quá trình khám phá các mẫu trong tập dữ liệu lớn bằng trí tuệ nhân tạo, máy học, thống kê và hệ thống cơ sở dữ liệu.
Các công cụ khai thác dữ liệu miễn phí bao gồm từ các môi trường phát triển mô hình hoàn chỉnh như Knime và Orange, đến nhiều thư viện được viết bằng Java, C++ và thường là bằng Python. Có bốn loại nhiệm vụ thường liên quan đến Khai thác dữ liệu:
- Phân loại:nhiệm vụ tổng quát hóa cấu trúc quen thuộc để sử dụng cho dữ liệu mới
- Phân cụm:nhiệm vụ tìm các nhóm và cấu trúc trong dữ liệu giống nhau theo cách này hay cách khác mà không sử dụng các cấu trúc được ghi chú trong dữ liệu.
- Học quy tắc kết hợp:Tìm kiếm mối quan hệ giữa các biến
- Hồi quy:Nhằm mục đích tìm một hàm lập mô hình dữ liệu với lỗi nhỏ nhất.
Liệt kê bên dưới các công cụ phần mềm miễn phí để Khai thác dữ liệu –
Danh sách công cụ khai thác dữ liệu miễn phí tốt nhất năm 2022:-
1. Công cụ khai thác nhanh –
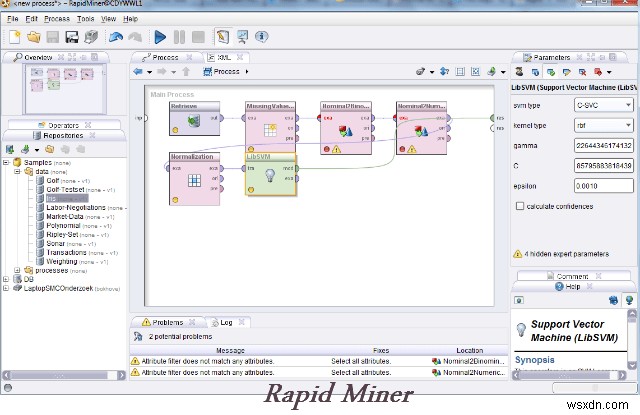
Rapid Miner, trước đây gọi là YALE (Yet another Learning Environment), là một môi trường dành cho các thử nghiệm khai thác dữ liệu và học máy, được sử dụng cho cả nhiệm vụ nghiên cứu và khai thác dữ liệu trong thế giới thực . Không còn nghi ngờ gì nữa, đây là hệ thống nguồn mở hàng đầu thế giới để khai thác dữ liệu. Được viết bằng ngôn ngữ Lập trình Java, công cụ này cung cấp các phân tích nâng cao thông qua các khung dựa trên mẫu.
Nó cho phép các thử nghiệm được tạo thành từ một số lượng lớn các toán tử có thể lồng tùy ý, được trình bày chi tiết trong các tệp XML và được thực hiện bằng giao diện người dùng đồ họa của Rapid Miner. Điều tốt nhất là người dùng không cần phải viết mã. Nó đã có nhiều mẫu và các công cụ khác cho phép chúng tôi phân tích dữ liệu một cách dễ dàng.
2. Trình tạo mô hình SPSS của IBM –
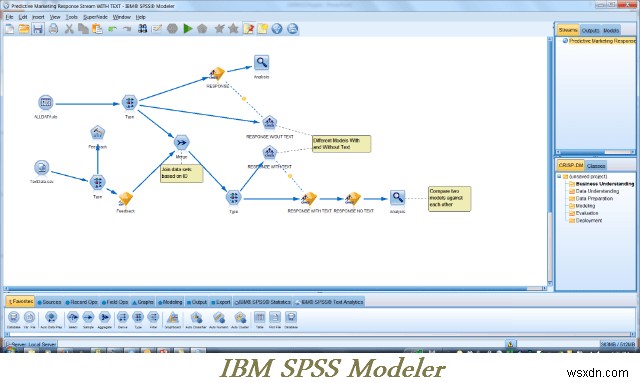
Bàn làm việc của công cụ IBM SPSS Modeler phù hợp nhất để làm việc với các dự án quy mô lớn như phân tích văn bản và giao diện trực quan của nó cực kỳ có giá trị. Nó cho phép bạn tạo nhiều thuật toán khai thác dữ liệu mà không cần lập trình. Nó cũng có thể được sử dụng để phát hiện bất thường, mạng Bayesian, CARMA, hồi quy Cox và các mạng thần kinh cơ bản sử dụng perceptron đa lớp với học lan truyền ngược. Không dành cho người yếu tim.
3. Khai thác dữ liệu Oracle –
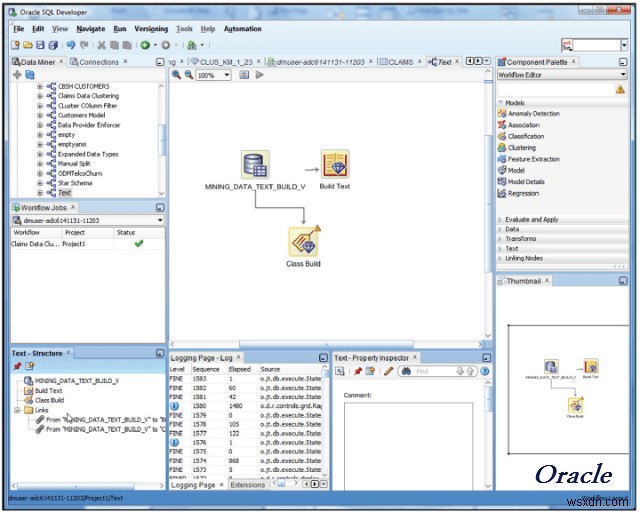
Một đối thủ lớn khác trong lĩnh vực khai thác dữ liệu là Oracle. As part of their Advanced Analytics Database option, Oracle data mining allows its users to discover insights, make predictions and leverage their Oracle data. You can build models to discover customer behavior target best customers and develop profiles.
The Oracle Data Miner GUI enables data analysts, business analysts and data scientists to work with data inside a database using a rather elegant drag and drop solution. It can also create SQL and PL/SQL scripts for automation, scheduling and deployment throughout the enterprise.
4. Teradata –
Teradata recognizes the fact that, although big data is awesome, if you don’t actually know how to analyze and use it, it’s worthless. Imagine having millions upon millions of data points without the skills to query them. That’s where Teradata comes in. They provide end-to-end solutions and services in data warehousing, big data and analytics and marketing applications.
Teradata also offers a whole host of services including implementation, business consulting, training and support.
5. Framed Data –
It’s a fully managed solution which means you don’t need to do anything but sit back and wait for insights. Framed Data takes data from businesses and turns it into actionable insights and decisions. They train, optimize, and store product ionized models in their cloud and provide predictions through an API, eliminating infrastructure overhead. They provide dashboards and scenario analysis tools that tell you which company levers are driving metrics you care about.
6. Kaggle –
Kaggle is the world’s largest data science community. Companies and researchers post their data and statisticians and data miners from all over the world compete to produce the best models.
Kaggle is a platform for data science competitions. It help you solve difficult problems, recruit strong teams, and amplify the power of your data science talent.
3 steps of working –
- Upload a prediction problem
- Submit
- Evaluate and Exchange
7. Weka –
WEKA is a very sophisticated best data mining tool. It shows you various relationships between the data sets, clusters, predictive modelling, visualization etc. There are a number of classifiers you can apply to get more insight into the data.
8. Rattle –

Rattle stands for the R Analytical Tool to Learn Easily. It presents statistical and visual summaries of data, transforms data into forms that can be readily modelled, builds both unsupervised and supervised models from the data, presents the performance of models graphically, and scores new datasets.
It is a free and open source best data mining toolkit written in the statistical language R using the Gnome graphical interface. It runs under GNU/Linux, Macintosh OS X, and MS/Windows.
9. KNIME –
Konstanz Information Miner is a user friendly, intelligible and comprehensive open-source data integration, processing, analysis and exploration platform. It has a graphical user interface which helps users to easily connect the nodes for data processing.
KNIME also integrates various components for machine learning and data mining through its modular data pipelining concept and has caught the eye of business intelligence and financial data analysis.
10. Python –
As a free and open source language, Python is most often compared to R for ease of use. Unlike R, Python’s learning curve tends to be so short it’s become legendary. Many users find that they can start building data sets and doing extremely complex affinity analysis in minutes. The most common business-use case-data visualizations are straightforward as long as you are comfortable with basic programming concepts like variables, data types, functions, conditionals and loops.
11. Orange –
Orange is a component based data mining and machine learning software suite written in Python Language. It is an Open Source data visualization and analysis for novice and experts. Data mining can be done through visual programming or Python scripting. It is also packed with features for data analytics, different visualizations, from scatterplots, bar charts, trees, to dendrograms, networks and heat maps.
12. SAS Data Mining –
Discover data set patterns using SAS Data Mining commercial software. Its descriptive and predictive modelling provides insights for better understanding of the data. They offer an easy to use GUI. They have automated tools from data processing, clustering to the end where you can find best results for taking right decisions. Being a commercial software it also includes advanced tools like Scalable processing, automation, intensive algorithms, modelling, data visualization and exploration etc.
13. Apache Mahout –
Apache Mahout is a project of the Apache Software Foundation to produce free implementations of distributed or otherwise scalable machine learning algorithms focused primarily in the areas of collaborative filtering, clustering and classification.
Apache Mahout supports mainly three use cases:Recommendation mining takes users’ behavior and from that tries to find items users might like. Clustering takes e.g. text documents and groups them into groups of topically related documents. Classification learns from existing categorized documents what documents of a specific category look like and is able to assign unlabeled documents to the (hopefully) correct category.
14. PSPP –
PSPP is a program for statistical analysis of sampled data. It has a graphical user interface and conventional command-line interface. It is written in C, uses GNU Scientific Library for its mathematical routines, and plot UTILS for generating graphs. It is a Free replacement for the proprietary program SPSS (from IBM) predict with confidence what will happen next so that you can make smarter decisions, solve problems and improve outcomes.
15. jHepWork –
jHepWork is a free and open-source data-analysis framework that is created as an attempt to make a data-analysis environment using open-source packages with a comprehensible user interface and to create a tool competitive to commercial programs.
JHepWork shows interactive 2D and 3D plots for data sets for better analysis. There are numerical scientific libraries and mathematical functions implemented in Java. jHepWork is based on a high-level programming language Jython, but Java coding can also be used to call jHepWork numerical and graphical libraries.
16. R programming Language–
There’s no mystery why R is the superstar of free data mining tools on this list. It’s free, open source and easy to pick up for people with little to no programming experience. There are literally thousands of libraries that can be incorporated into the R environment making it a powerful data mining environment. It’s a free software programming language and software environment for statistical computing and graphics.
The R language is widely used among data miners for developing statistical software and data analysis. Ease of use and extensibility has raised R’s popularity substantially in recent years.
17. Pentaho –
Pentaho provides a comprehensive platform for data integration, business analytics and big data. With this commercial tool you can easily blend data from any source. Get insights into your business data and make more accurate information driven decisions for future.
18. Tanagra –
TANAGRA is a data mining software for academic and research purposes. There are tools for exploratory data analysis, statistical learning, machine learning and databases area. Tanagra contains some supervised learning but also other paradigms such as clustering, factorial analysis, parametric and non-parametric statistics, association rule, feature selection and construction algorithms.
19. NLTK –
Natural Language Toolkit, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for the python language. It provides a pool of language processing tools including data mining, machine learning, data scrapping, sentiment analysis and other various language processing tasks. Build python programs to deal with human language data.
We hope our list of best free data mining tools was helpful to you. We would love to know your opinion, please do share your views in the comments section below.