Bạn có thể đã nghe nói về điều này. Google đang xem xét ý tưởng thay đổi cách mọi người tương tác với các trang web. Cụ thể hơn, cách mọi người tương tác với URL, địa chỉ Web mà con người có thể đọc được mà nhờ đó chúng tôi xác định và ghi nhớ phần lớn các trang web mà chúng tôi truy cập. Ít nhất phải nói rằng hiệu ứng lan tỏa xung quanh đề xuất này khá thú vị. Và nó khiến tôi phải suy nghĩ.
Thứ nhất, phản ứng dữ dội thực sự chống lại sự thay đổi bộc lộ nhiều hơn bản thân sự thay đổi. Thứ hai, liệu có thực sự xứng đáng khi cố gắng làm cho các URL bằng cách nào đó có ý nghĩa và/hoặc hữu ích hơn so với hình thức hiện tại của chúng không? Vì mục tiêu đó, bạn đang đọc bài viết này.
Tổng quan về URL
Con người liên kết ký ức với các từ hơn là các con số. Chúng ta dễ dàng ghi nhớ toàn bộ câu hoặc đoạn văn hơn là một chuỗi số. Điều này là do ngôn ngữ của chúng tôi được xây dựng chủ yếu bằng các từ. Chúng tôi đấu tranh với bất kỳ dãy số nào dài hơn tám hoặc chín chữ số. Lý do đơn giản là, với các chữ cái, tính duy nhất của thông tin tương đối nhỏ - 1001 và 1002 chỉ cách nhau một chữ cái, có thể nói như vậy, nhưng nó chỉ là mảnh ghép cuối cùng mang lại ý nghĩa cho sự khác biệt. Với các từ, có tương đối ít cách kết hợp không rõ ràng ngoài một chuỗi ký tự và/hoặc âm thanh ngắn.
Do đó, khi Web xuất hiện, việc sử dụng các từ - chuỗi - để xác định các Trang web trở nên hợp lý hơn thay vì diễn giải bằng máy. Đó là một chu kỳ buồn cười. Chúng tôi chuyển đổi các từ (mã) thành ngôn ngữ máy và sau đó chúng tôi làm ngược lại để mọi người có thể tương tác với máy tính một cách có ý nghĩa. Truy cập trang web bằng cách sử dụng các con số là cách máy móc. Chuỗi là cách của con người.Vấn đề là - URL là một dạng kết hợp giữa ngôn ngữ của con người và máy. Một mặt, bạn có yếu tố con người, chính địa chỉ (như dedoimedo.com), nhưng tất cả phần còn lại là khá nhiều hướng dẫn để máy chủ từ xa tìm, tìm kiếm và trình bày thông tin lại cho người dùng. Điều này gây ra một vấn đề là mọi người tương tác với các trang web theo cách không phải lúc nào cũng có ý nghĩa đối với bộ não con người bình thường.
Một vấn đề khác là - URL không có bất kỳ thông tin nhúng nào có độ trung thực. Giống như các địa chỉ vật lý trong thế giới thực. Nếu bạn đến 17 Orchard Drive, nó sẽ không cho bạn biết địa chỉ đó là GÌ. Có thể là văn phòng, có thể là tư gia, có thể là vũ trường. Cũng không có thông tin về NỘI DUNG, cũng như những gì bạn sẽ tìm thấy ở đó - con người, đống đổ nát, bàn thờ hiến tế, v.v.
Theo cách tương tự, các URL không phản ánh đích đến (trang web bạn đang kết nối) theo bất kỳ cách nào. Đôi khi, có thể có một số mối tương quan, nhưng nhìn chung, nó không có ý nghĩa trừ khi bạn biết trang web đó nói về cái gì và nó có nghĩa là gì. Điều này đúng với các trang web nhỏ cũng như các công ty lớn.
Chẳng hạn, Google không thực sự cho bạn biết đó là một công cụ tìm kiếm. Yahoo không cho bạn biết đó là một công cụ tìm kiếm. Bing nghĩa là gì? Amazon là một dòng sông, một khu rừng hay một thị trường trực tuyến khổng lồ? Bạn đã tin tưởng những trang web này thông qua việc sử dụng và danh tiếng chung, không phải vì có bất kỳ giá trị nguyên mẫu nào trong thông tin URL. Nhưng nó trở nên tốt hơn, hay đúng hơn là tệ hơn:
- Không có mối tương quan giữa chuỗi trang web và mục đích của trang web.
- Không có mối tương quan giữa chuỗi trang web và tên trang web (hoặc doanh nghiệp đằng sau nó).
- Không có mối tương quan giữa tiêu đề trang web và tên trang web.
- Không có thông tin về mục đích của trang web.
Hơn nữa, khi bạn truy cập vào một trang cụ thể, có thể không có mối tương quan nào giữa tiêu đề trang, URL và nội dung. Bạn có thể truy cập một số trang web, đến một trang có tên là kittens.html, nhưng đó có thể là về đề can hình con mèo cho ô tô, hoặc thực sự là về những thứ nhỏ có lông. Hoặc một cái gì đó khác hoàn toàn. Và trang web thực sự có thể được gọi là cửa hàng của Dany và URL có thể giống như mysitenstuff.org.
Và nó vẫn còn tồi tệ hơn. Hiện tại, chúng ta mới chỉ thảo luận về yếu tố con người của phương trình. Sau đó, có phần máy móc. Tên miền phụ. Những thứ như m, www, www3. Các giao thức như http, https, ftp. Dấu phân cách, thư mục con. Cách không thống nhất mà các trang web trình bày trang của họ - ngày tháng, số ngẫu nhiên, chuỗi, v.v. Sau đó, bạn cũng có hướng dẫn. Một trang có thể có thứ gì đó như &uid=1234567&ref=true được thêm vào cuối chuỗi URL, điều này không có ý nghĩa gì đối với bạn với tư cách là người dùng, nhưng nó cho biết một số điều nhất định đối với máy chủ Web và/hoặc ứng dụng đang cung cấp hoặc phân tích nội dung .
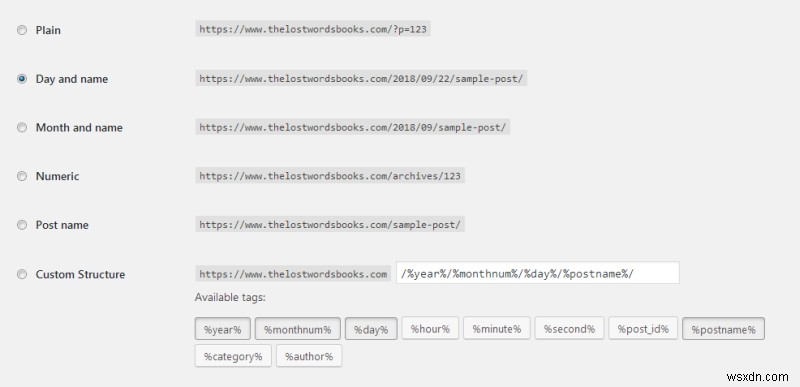
Tất cả các tùy chọn URL này sẽ phân giải thành cùng một nội dung, nhưng tất cả chúng đều có giao diện và hiển thị khác nhau.
Cuối cùng, không có biện pháp tin tưởng. Các trang web có giá trị như nhau cho đến khi chúng được xác thực theo một cách nào đó. Ngay từ đầu, khi mua sắm trực tuyến trở nên phổ biến hơn, khái niệm chứng chỉ kỹ thuật số đã xuất hiện, với các cơ quan đáng tin cậy xác nhận cả độ tin cậy và bảo mật đằng sau các huy hiệu được mã hóa và chống giả mạo. Nỗ lực của cộng đồng và xếp hạng trang (đôi khi là độc quyền) đã trở thành thước đo giá trị phụ được liên kết với miền (trang web) và nội dung của chúng, nhưng về cơ bản, điều này không hề được phản ánh trong chính URL.
Vậy câu hỏi đặt ra là chúng ta có cần thay đổi không? Có lẽ. Có thể không. Internet hoạt động và có quy mô tốt.
Câu trả lời nằm trong giải pháp. Nhưng trước tiên, một chút triết học.Bạn phản ứng thế nào khi nghe về đề xuất này?
Từ những gì tôi đã thấy, có hai trại chính ở đây. Những người hoan nghênh sự thay đổi, cảm thấy điều này sẽ làm cho Web tốt hơn (số lượng tốt hơn cần được xác định, nếu không thì đó chỉ là lời nói suông). Và những người phản đối sự thay đổi. Nhóm thứ hai có thể được chia thành ba nhóm:những người chống lại sự thay đổi vì lợi ích, những người phản đối giá trị kỹ thuật và những lợi ích được cho là, và nhóm thứ ba không tin tưởng vào một công ty vì lợi nhuận đề xuất hoặc dẫn dắt sự thay đổi này.
Thật vậy, điều này đặt ra một câu hỏi triết học lớn hơn nhiều. Google có nên được phép dẫn dắt việc này không?
Xét cho cùng, trong những năm qua, nhiều công ty vì lợi nhuận đã tạo ra những sản phẩm tốt mà chúng ta sử dụng ngày nay mà không cần suy nghĩ về nó. Sự phẫn nộ và tranh luận ban đầu đã bị lãng quên từ lâu. Nhưng có liên quan đến tiền, đó là một yếu tố thúc đẩy mạnh mẽ, và mọi thứ đã được thực hiện để củng cố lợi nhuận của công ty. Điều tương tự chắc chắn sẽ xảy ra với bất kỳ công ty nào có trách nhiệm với các cổ đông của mình, bất kể tên của nó là gì. Google có vị trí dẫn đầu vì ảnh hưởng to lớn của nó trong thế giới di động và lĩnh vực tìm kiếm. Nhưng đây có thể là bất kỳ công ty nào và cuối cùng, các yếu tố cơ bản đều giống nhau. Đối với một số người, đây là tất cả những gì quan trọng. Nếu nó vì lợi nhuận, nó không thể là một giải pháp vô tư mang lại lợi ích cho nhân loại. Có thể, như một tác dụng phụ, nhưng không phải là mục tiêu chính.
Và đây là một trong những thực sự hấp dẫn. Sự kháng cự phản ánh nhiều hơn về Google trong những năm qua hơn là bất cứ điều gì liên quan đến công nghệ. Có vẻ như, từ một công ty hoàn toàn bình thường (đã biến mất khỏi bảng kê khai của công ty) thành một công ty bình dân khác.
Một ví dụ khác củng cố trường hợp này là sự khăng khăng của Google đối với AMP, dự án được tối ưu hóa cho thiết bị di động của riêng họ, bao bọc HTML thông thường trong các chỉ thị AMP đặc biệt. Mặc dù nó có một số ưu điểm khi tải trang và như vậy, nhưng về tổng thể, điều này thực sự tồi tệ. Đó là sự lặp lại của vấn đề mà chúng tôi đã thấy với Internet Explorer 6, nơi Microsoft đã đưa ra một loạt các chỉ thị mới không tuân thủ các tiêu chuẩn Web, tạo ra sự hỗn loạn HTML/CSS dành riêng cho trình duyệt mà chỉ mới được làm sáng tỏ gần đây - một phần.
Khi tôi bắt đầu Dedoimedo vào năm 2006, đây là một vấn đề lớn. Hầu hết mọi trang web hồi đó đều có phần ghi đè IE6/7/8 trong HTML của họ. Tôi đã quyết định không triển khai những điều đó và tuân thủ các thông số kỹ thuật của W3C, bất kể khách truy cập có thể bị phạt hay không, bởi vì cách duy nhất để thiết kế theo một kiểu chung và chuẩn hóa là cách mà huyền thoại Tim Berners-Lee đã hình dung ra nó. Lịch sử đã chứng minh tôi đúng. Thậm chí ngày nay, tôi đảm bảo rằng tất cả các trang của mình đều có HTML và CSS hợp lệ, đây là điều mà bạn hiếm khi thấy trên thị trường hiện nay. Và nếu bạn sử dụng các phần ghi đè đặc biệt cho trình duyệt này hoặc trình duyệt kia, thì bạn đang góp phần làm cho Internet trở nên kém tốt hơn.
HTML hợp lệ, một loài có nguy cơ tuyệt chủng.
Giờ đây, Google đang tạo lại sự cố phân kỳ tuân thủ HTML/CSS với AMP. Trang web phải trung lập và tuân thủ các tiêu chuẩn quốc tế, khách quan. Nó không bao giờ nên được định hình theo bất cứ điều gì mà bất kỳ công ty nào muốn.
Do đó, URL chỉ là chất xúc tác làm gia tăng sự ngờ vực đối với các tập đoàn lớn, đặc biệt là những tập đoàn kinh doanh dữ liệu cá nhân. Đó là vấn đề cần giải quyết trước tiên để tách cảm xúc ra khỏi kỹ thuật. Nếu không, tất cả các đề xuất trong tương lai sẽ có sai sót vì chúng sẽ tìm cách giải quyết các nhu cầu về cảm xúc hơn là nhu cầu kỹ thuật.
Tôi không có giải pháp cho vấn đề này - chỉ Google mới có thể thay đổi Google. Tất nhiên là nếu họ muốn.
Mọi thứ thay đổi
Chúng ta không được quên điều này. Những ý tưởng nhân từ bị cuốn theo đà của cuộc sống, trở thành những phiên bản biến thái của những khái niệm ban đầu của chúng. Điều này đôi khi xảy ra thông qua thiết kế có chủ ý, và đôi khi do tình cờ, thông qua hàng triệu quyết định và ràng buộc nhỏ không thể nhìn thấy hoặc lên kế hoạch trước. Hãy suy nghĩ về khá nhiều sản phẩm bạn đang sử dụng. Hãy nhìn xem nó đã như thế nào cách đây 5 hay 10 năm, nếu nó tồn tại cách đây rất lâu. Bạn có thấy một sự thay đổi? Bạn có thích nó không? Và sau đó hãy nhớ rằng bạn cũng đã thay đổi với tư cách là một con người và cách bạn nhìn nhận thế giới ngày nay không hoàn toàn giống như cách bạn cảm nhận vài năm trước.
Giải pháp của Google - hoặc của bất kỳ ai về vấn đề đó - có thể là điều tốt nhất trên thế giới. Mười bảy hoặc hai mươi năm kể từ bây giờ, nó có thể thay đổi theo cách không thể dự đoán được, bất chấp những ý định tốt nhất và tất cả các nghiên cứu sâu trên thế giới. Không cần phải có bất kỳ ác ý nào trong đó. Chỉ là sự chậm chạp của cách mọi thứ được thực hiện, mọi người làm quen và chấp nhận các chuẩn mực mới như truyền thống cũ, và tiếp tục cho đến khi điều ban đầu bị lãng quên từ lâu.
Vấn đề lớn nằm ở chỗ đó. Bất kể đề xuất đã được thống nhất ngày hôm nay là gì, ngay cả khi giải pháp của Google là HOÀN HẢO, thì không có gì ngăn cản bất kỳ công ty nào thực hiện triển khai riêng tư, độc quyền, bao gồm cả chính Google cho vấn đề đó. Hoặc bất kỳ đối thủ cạnh tranh nào.
Việc tư nhân hóa Internet thực sự đã xảy ra. Internet ngày càng nhỏ hơn. Đầu tiên, bạn đang sử dụng hầu hết thông tin của mình thông qua các nhà môi giới - công cụ tìm kiếm, cổng thông tin. Bạn sẽ hiếm khi tìm thấy nội dung mới trừ khi nó được liệt kê trên các trang tìm kiếm phổ biến và thậm chí sau đó, ở vị trí cao trong danh sách. Trên điện thoại di động, nó thậm chí còn tồi tệ hơn. Mọi người hầu như không duyệt nữa. Họ sử dụng các ứng dụng do một cửa hàng tập trung duy nhất cung cấp.
Chỉ cần nhìn vào điện thoại thông minh hoặc TV thông minh điển hình là gì - một nền tảng được kiểm soát chặt chẽ với nội dung được tuyển chọn và lọc. Khi bạn khởi chạy một ứng dụng điện thoại, bạn không biết nó đang làm gì trong nền hoặc nó đang kết nối với những URL nào. Hoặc bạn tin tưởng nền tảng sẽ làm những gì nó nói hoặc bạn không sử dụng nó, điều này đang trở nên khó khăn hơn do công nghệ xâm nhập và cần thiết như thế nào trong cuộc sống hàng ngày. Và điều này đã xảy ra trong, cái gì, chỉ mười hay mười lăm năm kể từ khi Internet thực sự bùng nổ? Hãy tưởng tượng điều gì sẽ xảy ra trong hai mươi hay năm mươi năm nữa.
Internet là quyền của con người
Có thể nói, Internet đã được thêm vào Tuyên ngôn Quốc tế Nhân quyền. Nhưng điều đó vẫn chưa đủ.
Chúng tôi đã có lực lượng đặc nhiệm Internet. Chúng tôi có tiêu chuẩn. Chúng tôi cũng có luật riêng tư, chủ yếu là quốc gia. Nhưng không có cơ quan siêu chính phủ nào đảm bảo quyền tự do kỹ thuật số và sự không can thiệp của các bên tư nhân vào tính trung lập của Web cho đến cấp độ cá nhân. Rất có thể điều này sẽ không bao giờ xảy ra, vì chiếc bánh quá to và mọng nước để có thể bỏ đi.
Chà, nếu bạn hỏi tôi, cách duy nhất để thực sự đảm bảo một số phần nhất định của Web thực sự không thể chạm tới là lưu giữ chúng trong một quy ước giống như Geneva kỹ thuật số. Điều này nghe có vẻ ngây thơ và lý tưởng, nhưng sau đó, ngày nay, bạn là người phụ thuộc vào bất kỳ ai kiểm soát Internet của bạn và cách họ quyết định cung cấp Internet cho bạn.
Đề xuất của tôi
Được rồi, cuối cùng là phần kỹ thuật.
Dù sao, cấu trúc URL phần lớn là:machine | con người | máy.
Các yếu tố thúc đẩy là:tính trung lập, bảo mật, toàn vẹn, dễ sử dụng. Tính bảo mật và tính toàn vẹn đã được giải quyết tương đối tốt bằng các chứng chỉ kỹ thuật số - nhưng chúng có thể được cải thiện. Tính trung lập được nhúng vào phần con người của chuỗi URL và tính dễ sử dụng nằm ở phần đầu tiên và phần cuối cùng.
Chi tiết máy 1
Như bạn đã biết, các trình duyệt hiện đại đã cố gắng tách phần máy khỏi phần con người của chuỗi địa chỉ Web bằng cách không hiển thị phần https:// và/hoặc www của địa chỉ, vì các trình duyệt này hiếm khi phục vụ các giao thức khác ngoài http hoặc https. Điều này không quá tệ. Tuy nhiên, khái niệm Secure-Not Secure vẫn chưa đủ rõ ràng. Điều đó thật đáng báo động và an ủi nhưng không phải vì những lý do chính đáng - chúng ta sẽ nói về điều này trong phần con người.
HTTP:// hoặc HTTPS:// không có ý nghĩa gì đối với 99% mọi người. Chúng rất hữu ích nếu bạn chuyển chuỗi URL cho các ứng dụng khác để chúng có thể sử dụng đúng giao thức để kết nối. Hơn nữa, chúng tôi thực sự có một sự dư thừa ở đây. Các chứng chỉ đã thực hiện công việc xác định tính bảo mật của kết nối.
Câu trả lời là loại bỏ hoàn toàn tiền tố (phần máy 1) và chỉ sử dụng chứng chỉ hoặc vì lý do tượng trưng, thay thế tiền tố bằng thứ gì đó như web - dấu phân cách thực tế và không chịu sự giám sát riêng biệt. Điều này có khả năng mở ra một địa điểm cho việc triển khai các giao thức phi web khác trong tương lai, như thực tế ảo, truyền phát đa phương tiện thuần túy, trò chuyện, v.v. Và cũng phù hợp với các trang nội bộ dành riêng cho trình duyệt như config, chrome, v.v.
Phần người
Phần con người phải là bất khả xâm phạm - bất kể địa chỉ trang web là gì, nó phải được giữ nguyên và nó phải luôn được hiển thị cho người dùng mà không có bất kỳ sự che giấu nào. Cần có hướng dẫn về các phương pháp thực hành URL tốt mà các ứng dụng có thể tuân theo, bao gồm tên miền, mục đích, logic, ngày tháng và tiêu đề phù hợp, điều mà một số máy chủ thực hiện. Nhưng đây chỉ là địa chỉ vật lý. We don't get to choose how streets are named, or how the home address is formed, and there are so many options worldwide. Same here.
This is part of what we are - and changing this language also breaks communication. There is no universal piece of objective information in a domain name, page title or similar. It's all down to what we want to write, and so, trying to tame this into submission is the wrong way forward.
But what about trust, integrity, spoofing?
If you mistype a site name, you could land on a wrong page. Or people ignore security warnings and give their credentials out on fake domains. Are there ways to work around these without breaking the human communication?
Well, certificates help - but they won't stop you going to a digitally signed site that is serving bogus content. Nor can they stop you from giving out your personal data. But on its own, technology CANNOT stop human stupidity or ignorance. It can be mitigated, but the unholy obsession with security degrades the user experience and breaks the Internet. So what to do?
I believe it is better to compromise on security than on user experience. The benefits outweigh the costs. There is crime out there, but largely, there's no breakdown of society and no anarchy. Because if we compromise on freedom for the sake of security, well, you know where this leads.
All that said, if the question is how to guarantee human users can differentiate between legitimate and fake sources supposedly serving identical content, beyond what we already have, then the answer lies in another question. If you give out two seemingly identical pages to a user, what is the one piece that separates them? The immediate answer is:URL. But if the user is not paying attention to the URL, what then?
The answer to that question could be a whitelist mechanism. In other words, if a user tries to input information on a page that is not recognized (in some way) as a known (read good) source, the browser could prompt the user with something like:You're currently on a page XYZ and about to fill in personal information, is this what you expect?
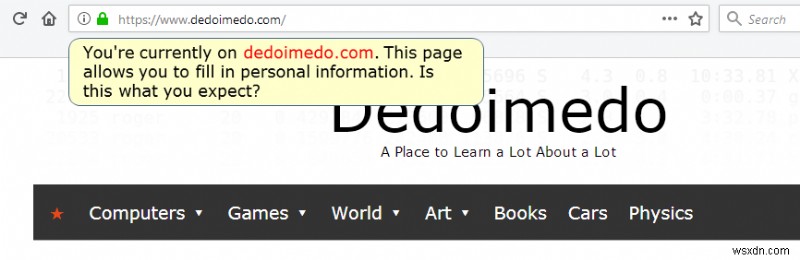
Crude illustration/mockup of what could be used to warn users when they are about to provide personal information on websites that are not "whitelisted" in some way.
People might still proceed and give away their data, but hey, nothing stops people from electrocuting themselves with toaster ovens in a bath tub, either. It is NOT about changing the URL - it's about helping people understand they are at the RIGHT address. In a way that does not break the user experience.
Now, let's talk about the machine string some more, shall we.
Machine part 2
The second part needs to be standardized. Today, servers and applications parse, mangle and structure URLs any which way they want. You can add all sorts of qualifies and key pair values, and end up with things like video autoplay, shopping cart contents, pre-filled forms, and more. In a way, this is lazy, convenient coding.
The standardization needs to be neutral - not dependent on how the browser or the site wants to present its information, because it's part of the problem today (including phishing and whatnot). I think that websites need to be forced to present a simple URL structure to the user that responds in a valid way.
The answer is:URL language. The same way browsers parse HTML and CSS, there could be a URL standard for the machine part. This could be a relatively small dictionary, and it would include somewhat STILL human-readable keys like (just a small subset of possible examples):
- unique-user-identifier - this would be a value that maps to an individual browser/user.
- javascript-status - if the client supports or runs Javascript.
- media-autoplay - whether media should play.
- media-timestamp - playback position for media.
- page - navigation element.
- Other similar keys.
And the rest would be ignored by the browser - provided all browsers adhere to the international standards and offer the same behavior and responses. Yes, the same way if you invent a new CSS class or HTML directive, and it does not exist and/or hasn't been properly declared, it gets ignored. The same way the remote application should ignore non-existent standard keys.
There must be special keys (flags), like dev=1 or debug=1 that would force the browser to interpret all provided machine parts and forward them to the server, which would also allow site devs/owners to troubleshoot their applications and offer full backward compatibility to everything we have on the market today. But then, the user could be prompted if such a combo is spotted in the URL address:
This site wants to run in dev mode. Do you want to allow it?
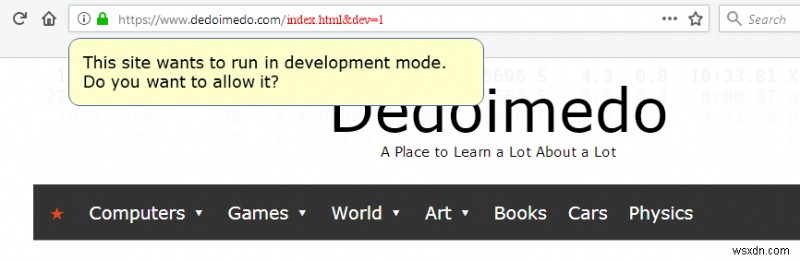
Crude illustration/mockup of what a standardized URL construct might be, with dev/debug flags.
This might enhance security too. Theoretically, the browsers could allow the user to block tracking via URL and not just on loaded pages. For instance, lots of email invitations and such come with a whole load of tracking, embedded in the URL. Privacy-conscious browsers could strip those away - or ask the user.
The URL is convenient for passing information to the application - but there's no real reason for this. When you click Buy on Amazon or PayPal, you don't see what happens. When you read Gmail, you don't see what happens. Buttons hide functionality, and it is not reflected in the URL.
To sum it up:the machine-part of the URL would contain a limited dictionary of standardized keys that would allow the information to be passed this way, but the rest would be ignored unless special flags like dev or debug are used, with the option to prompt the user. Enhanced security, enhanced privacy.
If ever defined, standardized and adopted, this will take time - an industry-wide effort. Now, is there a way to ignore forty years of legacy and existing implementations? The answer is, no bloody way. A change to the URL structure is something that will take decades. If you think IPv4 to IPv6 is complex, the URL journey will be even longer.
Finally, Quis custodiet ipsos custodes? Back to square one.
Kết luận
The URL change is not important on its own - it is, but the technical part is relatively easy. The bigger issue is that, at the moment, people still have a fairly unrestricted access to the Web, largely due to the nerdy nature of the human-readable Web addresses. The URL is one of the old pieces of the Internet, and as such, it is mostly unfiltered and without abstractions. Once that goes away, we truly lose control of information. The world becomes a walled garden.
Google's general call to action makes sense, from the technical perspective, but the change could accidentally lead to something far bigger. Something sinister. Something sad. The death of the Internet as we know it. The ugly, cumbersome URL was invented in an age of innocence and exploration. As confusing as it is, it's the one piece that does not really belong to anyone. Any future change must preserve that neutrality.
If I were Google, I wouldn't worry about the URL. I would focus on why people don't want Google to be the arbiter of their Internet. Understand why people oppose you, regardless of the technical detail. Because, in the end, it's not about the URL. It's about freedom. Once that piece clicks into place, the technical solution will be trivial.
Food for thought.
Chúc mừng.