Từ việc xây dựng Mạng Neural Hợp pháp đến triển khai OCR cho iOS
Động lực cho Dự án ✍️ ??
Trong khi tôi đang học cách tạo mô hình học sâu cho tập dữ liệu MNIST vài tháng trước, tôi đã tạo ra một ứng dụng iOS nhận dạng các ký tự viết tay.
Bạn tôi, Kaichi Momose đang phát triển một ứng dụng học tiếng Nhật, Nukon. Tình cờ anh ấy muốn có một tính năng tương tự trong đó. Sau đó, chúng tôi đã hợp tác để xây dựng một thứ phức tạp hơn một trình nhận dạng chữ số:OCR (Nhận dạng ký tự quang học / Trình đọc) cho các ký tự tiếng Nhật (Hiragana và Katakana).
Trong quá trình phát triển Nukon, không có API nào có sẵn để nhận dạng chữ viết tay trong tiếng Nhật. Chúng tôi không có lựa chọn nào khác ngoài việc xây dựng OCR của riêng mình. Lợi ích lớn nhất mà chúng tôi nhận được từ việc xây dựng một từ đầu là hoạt động ngoại tuyến. Người dùng có thể ở sâu trong núi mà không có internet mà vẫn mở Nukon để duy trì thói quen học tiếng Nhật hàng ngày. Chúng tôi đã học được rất nhiều điều trong suốt quá trình này, nhưng quan trọng hơn, chúng tôi rất vui mừng được giao một sản phẩm tốt hơn cho người dùng của mình.
Bài viết này sẽ chia nhỏ quá trình chúng tôi tạo OCR tiếng Nhật cho ứng dụng iOS. Đối với những người muốn xây dựng một ngôn ngữ / ký hiệu khác, vui lòng tùy chỉnh nó bằng cách thay đổi tập dữ liệu.
Nếu không có thêm lời khuyên, hãy xem những gì sẽ được đề cập:
Phần 1️⃣:Lấy tập dữ liệu và hình ảnh tiền xử lý
Phần 2️⃣:Xây dựng và đào tạo CNN (Mạng thần kinh hợp pháp)
Phần 3️⃣:Tích hợp mô hình được đào tạo vào iOS
Lấy tập dữ liệu &Hình ảnh tiền xử lý?
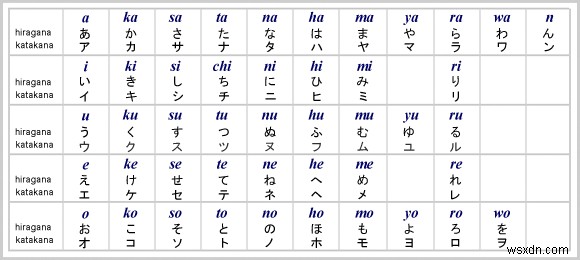
Bộ dữ liệu đến từ Cơ sở dữ liệu ký tự ETL, chứa chín bộ hình ảnh của các ký tự và ký hiệu viết tay. Vì chúng tôi sẽ xây dựng một OCR cho Hiragana, ETL8 là tập dữ liệu mà chúng tôi sẽ sử dụng.
Để lấy hình ảnh từ cơ sở dữ liệu, chúng tôi cần một số hàm trợ giúp đọc và lưu trữ hình ảnh trong .npz định dạng.
import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
Khi chúng ta có hiragana.npz đã lưu, hãy bắt đầu xử lý hình ảnh bằng cách tải tệp và định hình lại kích thước hình ảnh thành 32x32 pixel . Chúng tôi cũng sẽ bổ sung thêm dữ liệu để tạo thêm hình ảnh được xoay và thu phóng. Khi mô hình của chúng tôi được đào tạo về hình ảnh nhân vật từ nhiều góc độ khác nhau, mô hình của chúng tôi có thể thích ứng tốt hơn với chữ viết tay của mọi người.
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)Xây dựng và đào tạo CNN? ️
Bây giờ đến phần thú vị! Chúng tôi sẽ sử dụng Keras để xây dựng CNN (Mạng nơron hợp pháp) cho mô hình của chúng tôi. Khi tôi lần đầu tiên xây dựng mô hình, tôi đã thử nghiệm với các siêu thông số và điều chỉnh chúng nhiều lần. Sự kết hợp dưới đây cho tôi độ chính xác cao nhất - 98,77%. Hãy tự mình thử nghiệm với các thông số khác nhau.
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))Dưới đây là một số mẹo nếu bạn thấy hiệu suất của mô hình không đạt yêu cầu trong bước đào tạo:
Mô hình là overfitting
Điều này có nghĩa là mô hình không được khái quát hóa tốt. Hãy xem bài viết này để biết những giải thích trực quan.
Cách phát hiện trang phục thừa :acc (độ chính xác) tiếp tục tăng lên, nhưng val_acc (độ chính xác của xác nhận) làm ngược lại trong quá trình đào tạo.
Một số giải pháp để trang bị quá nhiều :chính quy hóa (ví dụ:học sinh bỏ học), tăng dữ liệu, cải thiện chất lượng của tập dữ liệu
Cách biết liệu mô hình có đang "đang học" hay không
Mô hình không học nếu val_loss (mất xác thực) tăng lên hoặc không giảm khi quá trình đào tạo tiếp tục.
Sử dụng TensorBoard - nó cung cấp các hình ảnh trực quan về hiệu suất của mô hình theo thời gian. Nó giúp loại bỏ nhiệm vụ mệt mỏi là xem xét từng kỷ nguyên và so sánh các giá trị liên tục.
Vì chúng tôi hài lòng với độ chính xác của mình, chúng tôi loại bỏ các lớp bỏ qua trước khi lưu trọng số và cấu hình mô hình dưới dạng tệp.
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
Nhiệm vụ duy nhất còn lại trước khi chuyển sang phần iOS là chuyển đổi hiraganaModel.h5 sang mô hình CoreML.
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
output_labels là tất cả các kết quả có thể có mà chúng ta sẽ thấy trong iOS sau này.
Sự thật thú vị:nếu bạn hiểu tiếng Nhật, bạn có thể biết rằng thứ tự của các ký tự đầu ra không khớp với “thứ tự bảng chữ cái” của Hiragana. Chúng tôi đã mất một thời gian để nhận ra rằng hình ảnh trong ETL8 không theo "thứ tự bảng chữ cái" (cảm ơn Kaichi đã nhận ra điều này). Tuy nhiên, tập dữ liệu được biên soạn bởi một trường đại học Nhật Bản…?
Tích hợp Mô hình đã Đào tạo vào iOS?
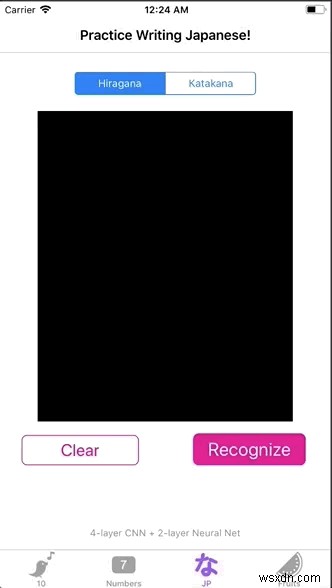
Cuối cùng thì chúng tôi cũng đang kết hợp mọi thứ lại với nhau! Kéo và thả hiraganaModel.mlmodel vào một dự án Xcode. Sau đó, bạn sẽ thấy một cái gì đó như thế này:
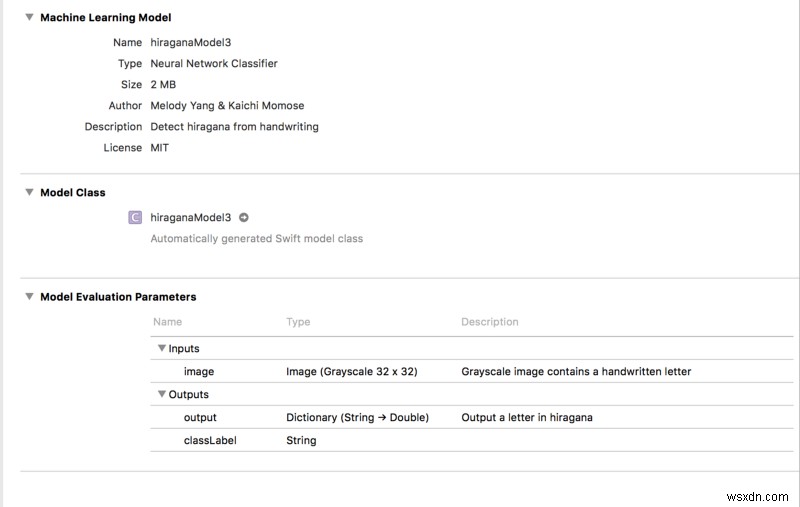
Lưu ý :Xcode sẽ tạo không gian làm việc khi sao chép mô hình. Chúng tôi cần chuyển môi trường mã hóa của mình sang không gian làm việc nếu không thì mô hình ML sẽ không hoạt động!
Mục tiêu cuối cùng là mô hình Hiragana của chúng tôi dự đoán một ký tự bằng cách truyền vào một hình ảnh. Để đạt được điều này, chúng tôi sẽ tạo một giao diện người dùng đơn giản để người dùng có thể viết và chúng tôi sẽ lưu trữ văn bản của người dùng ở định dạng hình ảnh. Cuối cùng, chúng tôi truy xuất các giá trị pixel của hình ảnh và đưa chúng vào mô hình của chúng tôi.
Hãy làm điều đó từng bước:
- Các ký tự “Vẽ” trên
UIViewvớiUIBezierPath
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
strokeLayer.strokeColor có thể là bất kỳ màu nào. Tuy nhiên, màu nền của canvas phải là đen . Mặc dù hình ảnh đào tạo của chúng tôi có nền trắng và các nét vẽ màu đen, nhưng mô hình ML không phản ứng tốt với hình ảnh đầu vào có kiểu này.
2. Xoay UIView thành UIImage và truy xuất các giá trị pixel bằng CVPixelBuffer
Trong phần mở rộng, có hai chức năng trợ giúp. Cùng nhau, chúng dịch các hình ảnh thành một bộ đệm pixel, tương đương với các giá trị pixel. Đầu vào width và height cả hai phải là 32 vì kích thước đầu vào của mô hình của chúng tôi là 32 x 32 pixel.
Ngay sau khi chúng tôi có pixelBuffer , chúng ta có thể gọi model.prediction() và chuyển vào pixelBuffer . Và chúng ta bắt đầu! Chúng ta có thể có kết quả đầu ra là classLabel !
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
3. Hiển thị đầu ra với UIAlertController
Bước này là hoàn toàn tùy chọn. Như được hiển thị trong GIF ở phần đầu, tôi đã thêm một bộ điều khiển cảnh báo để thông báo kết quả.
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}Thì đấy! Chúng tôi vừa xây dựng một OCR sẵn sàng dùng thử (và sẵn sàng cho App-Store)! ??
Kết luận?
Xây dựng một OCR không khó lắm. Như bạn đã thấy, bài viết này bao gồm các bước và các vấn đề và tôi đã gặp phải khi xây dựng dự án này. Tôi rất thích quá trình tạo ra một loạt mã Python có thể trình diễn được bằng cách kết nối nó với iOS và tôi dự định sẽ tiếp tục làm như vậy.
Tôi hy vọng bài viết này cung cấp một số thông tin hữu ích cho những ai muốn xây dựng một OCR nhưng không biết bắt đầu từ đâu.
Bạn có thể tìm thấy mã nguồn tại đây .
Phần thưởng :nếu bạn quan tâm đến việc thử nghiệm các thuật toán nông cạn, thì hãy tiếp tục đọc!
[Tùy chọn] Đào tạo với các thuật toán nông?
Trước khi triển khai CNN, Kaichi và tôi đã thử nghiệm các thuật toán học máy khác để tìm hiểu xem liệu chúng có thể hoàn thành công việc hay không (và giúp chúng tôi tiết kiệm một số chi phí tính toán!). Chúng tôi đã chọn KNN và Rừng ngẫu nhiên.
Để đánh giá hiệu suất của họ, chúng tôi đã xác định độ chính xác cơ bản của chúng tôi là 1/71 =0,014.
Chúng tôi cho rằng một người không có chút kiến thức nào về tiếng Nhật có thể có 1,4% cơ hội đoán đúng một ký tự.
Do đó, mô hình sẽ hoạt động tốt nếu độ chính xác của nó có thể vượt qua 1,4%. Hãy xem nếu nó là trường hợp. ?
KNN
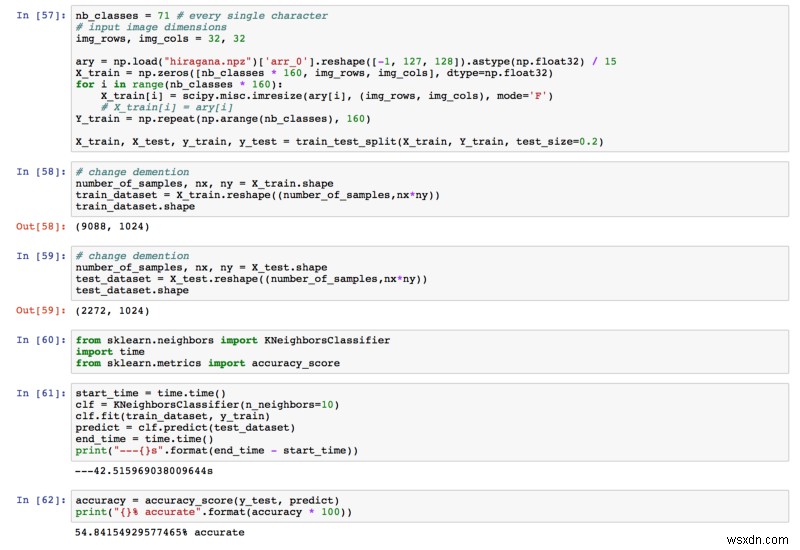
Độ chính xác cuối cùng mà chúng tôi nhận được là 54,84%. Đã cao hơn rất nhiều so với 1,4%!
Rừng Ngẫu nhiên
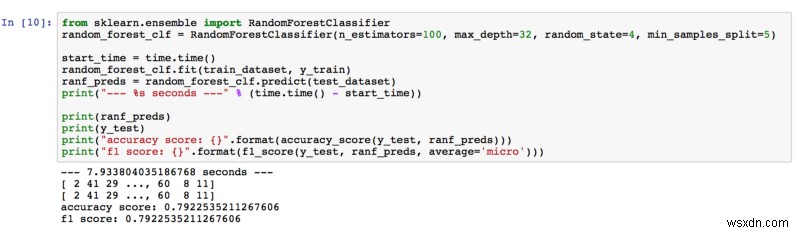
Độ chính xác là 79,23%, vì vậy Rừng Ngẫu nhiên đã vượt quá mong đợi của chúng tôi. Trong khi điều chỉnh siêu tham số, chúng tôi đã thu được kết quả tốt hơn bằng cách tăng số lượng công cụ ước tính và độ sâu của cây. Chúng tôi nghĩ rằng có nhiều cây hơn (công cụ ước lượng) trong rừng có nghĩa là sẽ học được nhiều đặc điểm hơn trong ảnh. Ngoài ra, cây càng sâu, nó càng học được nhiều chi tiết từ các tính năng.
Nếu bạn muốn tìm hiểu thêm, tôi đã tìm thấy bài báo này thảo luận về phân loại hình ảnh với Rừng ngẫu nhiên.
Cảm ơn bạn đã đọc. Mọi suy nghĩ và phản hồi đều được hoan nghênh!