Những gì chúng tôi đang xây dựng
Trong bài viết này, chúng tôi đang xây dựng các luồng LLM cực kỳ bền bỉ và dễ dàng tồn tại:
- Mạng ngừng hoạt động
- Làm mới trang
- Đóng trang web
- Đóng nắp máy tính xách tay
Phần thưởng:Bạn có thể xem cùng một luồng trên nhiều thiết bị (ví dụ:điện thoại và máy tính xách tay) cùng một lúc .
Cho dù bạn có cố gắng ngắt luồng đến mức nào thì nó vẫn tiếp tục ở chế độ nền khi bạn bị ngắt kết nối và tiếp tục suôn sẻ khi bạn quay lại. Đây là một điều đáng kinh ngạc trải nghiệm người dùng.
Bản trình diễn luồng LLM bền vững 👇
Cảm hứng
Khi xây dựng bằng AI, cách tốt nhất là truyền trực tiếp phản hồi của AI theo thời gian thực.
Thay vì chờ đợi toàn bộ phản hồi, người dùng của bạn sẽ thấy nội dung theo thời gian thực khi nó được tạo - điều này thật tuyệt vời đối với UX. Các công cụ như AI SDK của Vercel đã giúp việc này trở nên cực kỳ dễ dàng:
import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});Để luồng LLM thời gian thực hoạt động ở cấp độ kỹ thuật, bạn kết nối máy khách với API và truyền dữ liệu trở lại bằng các giao thức như Sự kiện gửi máy chủ (SSE):
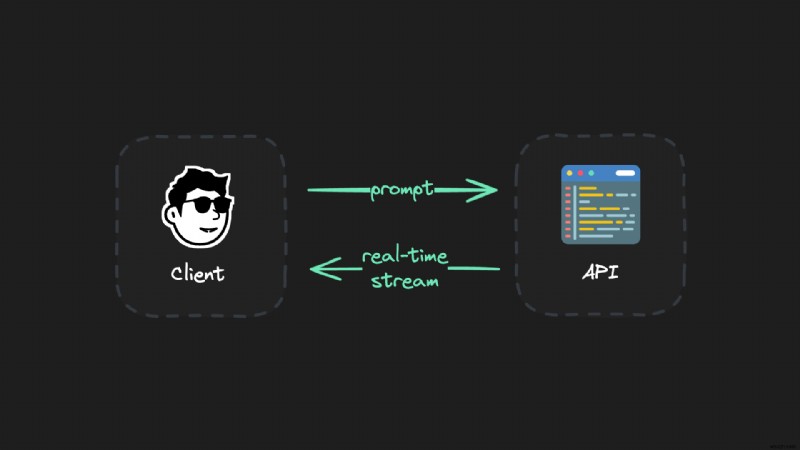
Nhưng:thiết lập này có vấn đề.
Nếu có bất kỳ điều gì xảy ra trong quá trình phát trực tuyến, chẳng hạn như ngắt kết nối internet, đóng nắp máy tính xách tay hoặc trục trặc mạng, toàn bộ thế hệ sẽ bị mất. Bạn cần phải bắt đầu lại và chờ đợi cả thế hệ một lần nữa. Điều này đặc biệt khó chịu đối với các thế hệ dài hơn (ví dụ:với các mẫu máy đắt tiền như O1).
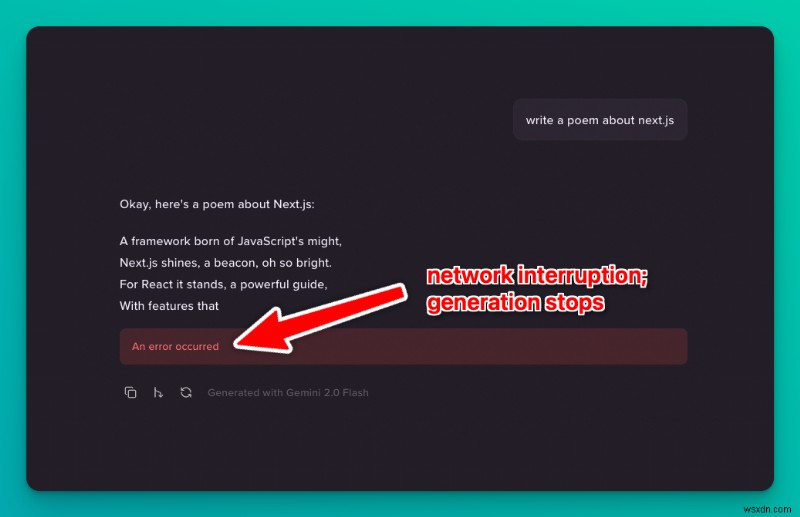
Rõ ràng vấn đề này nằm trong tầm quan tâm của mọi người. Nhu cầu phát trực tuyến LLM theo thời gian thực đáng tin cậy đang có nhu cầu thực sự và ngày càng có nhiều nhà phát triển đang thử nghiệm các cách để khiến tính năng này hoạt động:
Xây dựng luồng LLM có độ bền cao
Nước sốt bí mật để tạo ra các luồng LLM thực sự bền bỉ và có thể tiếp tục đang tách khách hàng khỏi môi trường tạo. Kết nối máy khách không ổn định và có thể bị ngắt kết nối vì nhiều lý do, như đóng máy tính xách tay, sự cố mạng hoặc làm mới trang.
Bằng cách tách biệt các quy trình tạo và khách hàng, quá trình tạo luôn tiếp tục không bị gián đoạn. Khách hàng có thể kết nối lại bất kỳ lúc nào mà không làm gián đoạn quá trình tạo đang diễn ra.
Ý tưởng tồi:Kết nối trực tiếp, liên tục:
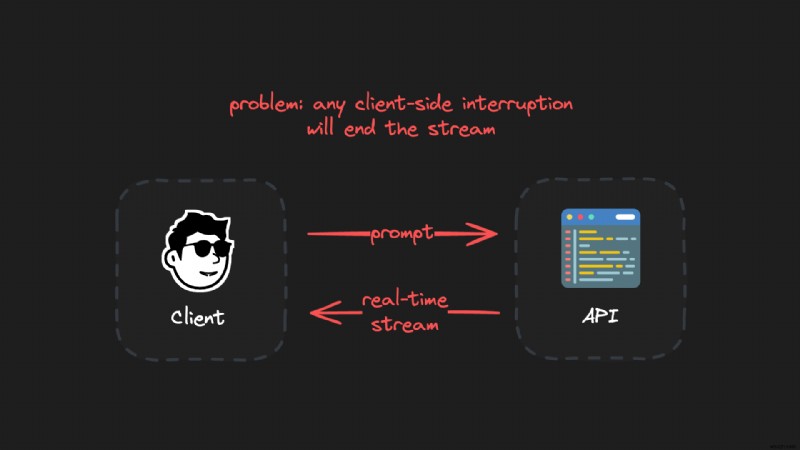
Ý tưởng hay:Kết nối luồng có thể thay thế, bị gián đoạn:
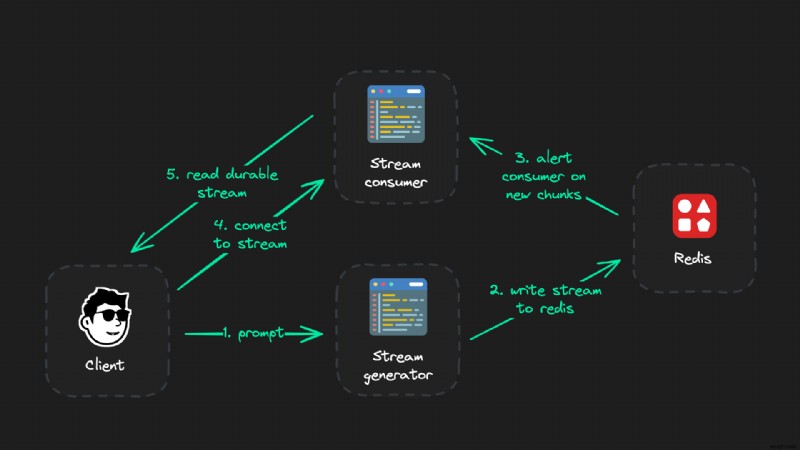
Và đúng vậy - kiến trúc này có thể trông khá phức tạp đối với một luồng AI đơn giản. Tuy nhiên, như bạn sẽ thấy trong mã ngay bây giờ, đây chỉ là một vài dòng mã và mất vài phút để triển khai.
Thiết lập luồng bền
Thiết lập luồng LLM cực kỳ đáng tin cậy có ba phần:
- Khách hàng (giao diện người dùng)
- Trình tạo luồng (một tuyến API)
- Người tiêu dùng truyền phát (cũng là một tuyến API)
Tất cả các kết nối trực tiếp tới máy khách có thể bị gián đoạn hoặc tạm dừng bất cứ lúc nào. Do đó, phần logic chịu trách nhiệm tạo luồng đầu ra LLM (trình tạo luồng) phải là một API độc lập không bao giờ có kết nối hoạt động với máy khách.
Thay vào đó, chúng tôi sẽ kết nối với khách hàng thông qua một người tiêu dùng - chỉ đọc dữ liệu từ Redis và khá "ngu ngốc". Mục đích duy nhất của nó là đọc đầu ra của trình tạo và cung cấp tất cả các khối LLM mà khách hàng chưa thấy bất cứ khi nào khách hàng kết nối với nó. Thế thôi.
Tóm tắt nhanh - nhiệm vụ của từng phần:
- Khách hàng: Kích hoạt trình tạo luồng (nhưng không bao giờ duy trì kết nối mở) và hiển thị luồng thời gian thực
- Trình tạo luồng: Tạo đầu ra LLM trong thời gian thực và xuất bản lên Redis
- Người tiêu dùng truyền trực tuyến: Đọc luồng của trình tạo và đẩy các đoạn tới máy khách
Trình tạo chỉ chịu trách nhiệm đọc luồng LLM và xuất bản nó lên Redis trong thời gian thực. Chúng tôi nhận được một kết nối có thể thay thế từ máy khách đến thiết bị tiêu thụ luồng. Kết nối này có thể được kết thúc, kết nối lại, v.v.-không có gì ảnh hưởng đến trình tạo luồng.
Ví dụ về mã
Trong phần này, chúng ta sẽ xem xét mã. Để làm rõ các nguyên tắc, chúng ta sẽ xem xét việc triển khai mã sản xuất hoàn chỉnh và thực tế ở phần cuối.
Hiện tại, việc hiểu mã sẽ dễ dàng hơn nhiều nếu chúng ta xem xét các đoạn mã cốt lõi và mục đích của chúng thay vì toàn bộ tệp mã.
1. Khách hàng
Khách hàng chỉ có 3 trách nhiệm:
- Tạo ID phiên
- Kích hoạt trình tạo
- Hiển thị luồng tạo
Chúng ta hãy xem từng cái một:
Khách hàng:Tạo ID phiên
Khi một máy khách kết nối hoặc kết nối lại với một luồng, chúng tôi muốn gửi tất cả các tin nhắn mà máy khách chưa xem. Điều đó có nghĩa là trong một luồng đang hoạt động, mỗi tin nhắn chỉ chứa delta chính xác mà khách hàng cần xem chứ không phải toàn bộ luồng.
Khi kết nối lại, toàn bộ luồng đến điểm tạo hiện tại sẽ được gửi và việc đăng ký tất cả các sự kiện trong tương lai hoàn toàn liền mạch mà không bị thiếu bất kỳ đoạn nào.
Làm thế nào?
Redis Streams, một cách để lưu trữ và truy xuất dữ liệu thời gian thực một cách hiệu quả, có chức năng chưa từng thấy này được tích hợp thông qua một thứ gọi là nhóm người tiêu dùng. Điều duy nhất chúng tôi cần làm:đảm bảo mỗi khách hàng có một phiên duy nhất - nghĩa là chúng tôi chỉ định cho mỗi thế hệ một ID duy nhất.
Chúng ta sẽ tìm hiểu thêm về các nhóm người tiêu dùng khi xem xét người tiêu dùng truyền phát. Chúng trông như thế này:
await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});Toàn bộ logic của ứng dụng khách nào đã xem luồng nào cho đến điểm nào và phần nào bị thiếu hoàn toàn được xử lý bởi luồng Redis với độ chính xác được đảm bảo. Chúng tôi không bao giờ thiếu đoạn LLM và luôn gửi chính xác dữ liệu mà khách hàng cần.
Điều duy nhất khách hàng cần làm lúc này:chỉ định ID cho mỗi thế hệ. Chúng tôi chỉ đơn giản sử dụng nanoid :
import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);Khách hàng:Kích hoạt luồng thế hệ
Tương tác duy nhất mà khách hàng từng có với công cụ tạo là kích hoạt nó. Tuy nhiên, về mặt kỹ thuật, bạn có thể kích hoạt quá trình tạo từ bất kỳ nơi nào khác (ví dụ:công việc CRON, quy trình tự động).
Ở dạng đơn giản nhất, đây chỉ là một lệnh gọi tìm nạp đến tuyến API thế hệ:
// 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});Khách hàng:Đọc luồng thế hệ
Sau khi kích hoạt quá trình tạo, trình tạo bắt đầu truyền đầu ra LLM vào kho lưu trữ Redis tập trung - tách biệt hoàn toàn khỏi máy khách. Hãy kết nối với người tiêu dùng luồng để đọc luồng thế hệ:
// 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});Thế thôi!
Đó là ba trách nhiệm của khách hàng. Tất nhiên, chúng ta có thể tinh tế hơn nhiều với các móc tùy chỉnh để tạo ID, truy vấn phản ứng để có độ tin cậy cao hơn và hơn thế nữa - chúng ta sẽ đề cập đến điều đó trong các ví dụ mã hoàn chỉnh sau.
2. Trình tạo luồng
Trình tạo luồng mở luồng LLM và ghi từng đoạn vào luồng Redis. Nó xuất bản một thông báo cho mỗi đoạn được viết để cảnh báo người tiêu dùng truyền phát về dữ liệu mới để cập nhật theo thời gian thực.
Lưu ý:Một lần nữa, đây không phải là một ví dụ về mã đầy đủ. Cuối cùng chúng ta sẽ xem mã đầy đủ-đây là để hiểu khái niệm.
import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)3. Người tiêu dùng truyền phát
Người tiêu dùng luồng kết nối với Redis và nghe các cảnh báo đoạn mới thông qua Redis pub/sub. Mỗi khách hàng có nhóm người tiêu dùng riêng để theo dõi các tin nhắn đã xem và chưa xem.
Lưu ý:Việc xuất bản không chuyển đoạn thực tế mà chỉ thông báo rằng một đoạn mới có sẵn trong luồng.
Khi có đoạn mới, API dành cho người tiêu dùng luồng sẽ đọc đoạn đó từ luồng và chuyển tiếp đoạn đó đến tất cả các máy khách được kết nối. Nhóm người tiêu dùng Redis theo dõi những gì mỗi khách hàng đã thấy để đảm bảo chuyển không bị trùng lặp hoặc thiếu đoạn.
Người tiêu dùng luồng cốt lõi trông như thế này:
const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});Lưu ý:Chúng tôi đang tạo một nhóm người tiêu dùng trên mọi kết nối. Điều này hoạt động rất tốt vì Redis xử lý thao tác này một cách bình thường, ví dụ:không có gì xảy ra nếu nhóm đã tồn tại.
Mã đầy đủ
Tạo SessionID
Cho đến thời điểm hiện tại, chúng tôi đã xem xét từng đoạn mã riêng lẻ để hiểu rõ nhiệm vụ của khách hàng, trình tạo luồng và trình tiêu thụ luồng riêng lẻ. Bây giờ, chúng ta hãy xem các phần này khớp với nhau như thế nào bằng cách xem cách triển khai đầy đủ.
Để bắt đầu, việc tạo sessionId phải linh hoạt hơn việc chỉ sử dụng nanoid() . Rốt cuộc, điều gì sẽ xảy ra nếu trang web được làm mới hoặc đóng cửa? Khi kết nối lại, chúng tôi sẽ mất sessionId đã tạo nếu không lưu trữ nó ở đâu đó - nó cần được duy trì miễn là quá trình tạo chạy.
May mắn thay localStorage là hoàn hảo cho việc này:
import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};Khách hàng
Chúng ta đã thấy hai phần quan trọng nhất của ứng dụng khách:bắt đầu luồng và kết nối với luồng. Sau khi nhận được xác nhận từ API rằng trình tạo đang chạy, chúng tôi sẽ kết nối với luồng bằng cách sử dụng truy vấn phản ứng refetch tiện ích để gọi truy vấn kết nối của chúng tôi.
Đây là cách tất cả các phần khớp với nhau:
app/page.tsx"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}Trình tạo luồng
Đây là toàn bộ mã cho trình tạo luồng. Nếu quá trình tạo LLM không thành công tại bất kỳ thời điểm nào, nó sẽ tự động được thử lại bằng cách sử dụng Upstash Workflow để có độ tin cậy tối đa:
api/llm-stream/route.tsimport {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});Để hoàn toàn an toàn về kiểu, tôi cũng đã viết tất cả các lược đồ thông báo trong zod:
tin nhắn-schema.tsimport { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};Người tiêu dùng truyền phát
Cuối cùng, chúng ta hãy xem toàn bộ quá trình triển khai luồng tiêu dùng. Đây là kết nối có thể thay thế, tự động gửi cùng tất cả các đoạn không nhìn thấy được khi máy khách kết nối:
api/check-stream/route.tsimport { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}Tóm tắt nhanh và lời cuối cùng
Chúng tôi vừa xây dựng luồng LLM cực kỳ mạnh mẽ có thể xử lý tình trạng gián đoạn mạng, làm mới trang và thậm chí là ngắt kết nối hoàn toàn. Đây là những gì chúng tôi đã làm:
-
Việc tạo tách rời khỏi quá trình phân phối: Bằng cách tách việc tạo LLM khỏi kết nối máy khách, quá trình tạo nội dung sẽ tiếp tục bất kể sự cố của máy khách.
-
Bộ nhớ liên tục sử dụng luồng Redis: Chúng tôi đang sử dụng luồng Redis làm trình trung chuyển tin nhắn liên tục để lưu trữ từng đoạn phản hồi LLM khi nó được tạo.
-
Cập nhật theo thời gian thực với Redis Pub/Sub: Chúng tôi đã xây dựng một hệ thống thông báo bằng Redis Pub/Sub để thông báo cho người tiêu dùng phát trực tuyến khi có phần mới.
-
Tự động kết nối lại: Máy khách có thể kết nối lại bất kỳ lúc nào và tự động nhận tất cả nội dung, đảm bảo không bị trùng lặp hoặc thiếu đoạn. Điều này bao gồm nội dung được tạo trong quá trình ngắt kết nối.
-
Quản lý phiên: Chúng tôi đã tạo một hệ thống phiên cho phép người dùng xem luồng trên nhiều thiết bị cùng một lúc.
Tóm lại, chúng tôi hiện đang cung cấp trải nghiệm người dùng (UX) đặc biệt cho người dùng của mình. Tôi thực sự khuyên bạn nên sử dụng phương pháp này, đặc biệt nếu bạn đang xây dựng một dịch vụ giống như dịch vụ trò chuyện LLM.
Chúc mừng bạn đã đọc! Nếu bạn có bất kỳ phản hồi nào hoặc muốn trở thành tác giả khách mời trên Upstash, hãy liên hệ theo số josh@upstash.com 🙌