“Đơn giản là sự tinh tế cuối cùng” —Leonardo da Vinci
“ Hầu hết thông tin đều không liên quan và hầu hết nỗ lực đều bị lãng phí, nhưng chỉ chuyên gia mới biết nên bỏ qua điều gì ”—James rõ ràng, thói quen nguyên tử
Bạn có một đường ống dẫn dữ liệu ưa thích với rất nhiều hệ thống khác nhau. Bề ngoài trông có vẻ rất tinh vi, nhưng thực chất bên trong nó là một mớ hỗn độn phức tạp. Nó có thể cần rất nhiều công việc về hệ thống ống nước để kết nối các phần khác nhau, nó có thể cần giám sát liên tục, nó có thể yêu cầu một nhóm lớn với chuyên môn duy nhất để chạy, gỡ lỗi và quản lý nó. Chưa kể, bạn càng sử dụng nhiều hệ thống, càng có nhiều nơi bạn đang sao chép dữ liệu của mình và càng có nhiều khả năng nó không đồng bộ hoặc cũ. Hơn nữa, vì mỗi hệ thống con này được phát triển độc lập bởi các công ty khác nhau, các bản nâng cấp hoặc sửa lỗi của chúng có thể phá vỡ đường ống dẫn và lớp dữ liệu của bạn.
Nếu không cẩn thận, bạn có thể gặp phải tình huống sau như được mô tả trong video dài ba phút bên dưới. Tôi thực sự khuyên bạn nên xem nó trước khi tiếp tục.

Sự phức tạp nảy sinh bởi vì mặc dù mỗi hệ thống có thể trông đơn giản trên bề mặt, nhưng chúng thực sự mang các biến sau vào đường dẫn của bạn và có thể thêm rất nhiều phức tạp:
- Giao thức — hệ thống vận chuyển dữ liệu như thế nào? (HTTP, TCP, REST, GraphQL, FTP, JDBC)
- Định dạng dữ liệu — hệ thống hỗ trợ định dạng nào? (Nhị phân, CSV, JSON, Avro)
- Lược đồ dữ liệu và sự phát triển — dữ liệu được lưu trữ như thế nào? (bảng, Luồng, đồ thị, tài liệu)
- SDK và API — hệ thống có cung cấp các SDK và API cần thiết không?
- ACID và BASE — nó có cung cấp tính nhất quán ACID hoặc BASE không?
- Di chuyển — hệ thống có cung cấp cách dễ dàng để di chuyển tất cả dữ liệu vào hoặc ra khỏi hệ thống không?
- Độ bền — điều gì đảm bảo hệ thống có độ bền?
- tính khả dụng — điều gì đảm bảo hệ thống có tính khả dụng? (99,9%, 99,999%)
- Khả năng mở rộng — khả năng mở rộng như thế nào?
- Bảo mật — hệ thống an toàn đến mức nào?
- Hiệu suất — hệ thống xử lý dữ liệu nhanh như thế nào?
- Tùy chọn lưu trữ — nó được lưu trữ hay chỉ tại chỗ hay kết hợp?
- Clouds — nó có hoạt động trên đám mây, khu vực của tôi, v.v. không?
- Hệ thống bổ sung — nó có cần một hệ thống bổ sung không? (ví dụ:Zookeeper cho Kafka)
Các biến như định dạng dữ liệu, lược đồ và giao thức cộng lại thành phần được gọi là “chi phí chuyển đổi”. Các biến khác như hiệu suất, độ bền và khả năng mở rộng cộng lại với cái được gọi là “chi phí đường ống”. Tổng hợp lại, những phân loại này góp phần vào cái được gọi là "sự không phù hợp trở kháng". Nếu chúng ta có thể đo lường điều đó, chúng ta có thể tính toán độ phức tạp và sử dụng nó để đơn giản hóa hệ thống của mình. Chúng ta sẽ hoàn thành điều đó trong giây lát.
Bây giờ, bạn có thể tranh luận rằng hệ thống của bạn, mặc dù nó có vẻ phức tạp, nhưng thực sự là hệ thống đơn giản nhất cho nhu cầu của bạn. Nhưng làm thế nào bạn có thể chứng minh điều đó?
Nói cách khác, làm cách nào để bạn thực sự đo lường và cho biết lớp dữ liệu của bạn thực sự đơn giản hay phức tạp? Và thứ hai, làm thế nào bạn có thể ước tính liệu hệ thống của bạn sẽ vẫn đơn giản khi bạn thêm nhiều tính năng hơn? Nghĩa là, nếu bạn thêm nhiều tính năng hơn vào lộ trình của mình, bạn có cần thêm nhiều hệ thống hơn không?
Đó là lúc "kiểm tra sự không phù hợp trở kháng" xuất hiện. Nhưng trước tiên hãy xem xét sự không phù hợp trở kháng là gì và sau đó chúng ta sẽ tự đi vào bài kiểm tra.
Không khớp trở kháng là gì?
Thuật ngữ này bắt nguồn từ kỹ thuật điện để giải thích sự không phù hợp trong trở kháng điện, dẫn đến mất năng lượng khi năng lượng được truyền từ điểm A đến điểm B.
Nói một cách đơn giản, điều đó có nghĩa là những gì bạn có không khớp với những gì bạn cần. Để sử dụng nó, bạn lấy những gì bạn hiện có, biến nó thành những gì bạn cần, rồi sử dụng nó. Do đó, có sự không phù hợp và chi phí liên quan đến việc sửa chữa sự không phù hợp.
Trong trường hợp của chúng tôi, bạn có dữ liệu ở dạng hoặc số lượng nào đó và bạn cần phải biến đổi dữ liệu đó trước khi chúng tôi có thể sử dụng. Việc chuyển đổi có thể xảy ra nhiều lần và thậm chí có thể sử dụng nhiều hệ thống ở giữa.
Trong thế giới cơ sở dữ liệu, sự không khớp trở kháng xảy ra vì hai lý do:
- Chi phí chuyển đổi:Cách hệ thống xử lý hoặc lưu trữ dữ liệu khác với dữ liệu thực sự trông như thế nào hoặc cách bạn nghĩ về nó. Ví dụ:Trong máy chủ của bạn, bạn có thể linh hoạt lưu trữ dữ liệu trong nhiều cấu trúc dữ liệu, chẳng hạn như bộ sưu tập, luồng, Danh sách, Bộ, Mảng, v.v. Nó giúp bạn lập mô hình dữ liệu của mình một cách tự nhiên. Tuy nhiên, sau đó bạn cần ánh xạ dữ liệu này thành các bảng trong kho lưu trữ tài liệu RDBMS hoặc JSON, để lưu trữ chúng. Sau đó, làm ngược lại để đọc dữ liệu. Lưu ý rằng sự không khớp cụ thể giữa mô hình ngôn ngữ hướng đối tượng và mô hình bảng quan hệ được gọi là "Sự không khớp trở kháng quan hệ đối tượng".
- Chi phí đường ống:Lượng dữ liệu và loại dữ liệu bạn xử lý trong máy chủ khác với lượng dữ liệu mà cơ sở dữ liệu của bạn có thể xử lý. Ví dụ:nếu bạn đang xử lý hàng triệu sự kiện đến từ thiết bị di động, RDBMS hoặc kho tài liệu điển hình của bạn có thể không lưu trữ được hoặc cung cấp API để dễ dàng tổng hợp hoặc tính toán các sự kiện đó. Vì vậy, bạn cần các hệ thống xử lý luồng đặc biệt, chẳng hạn như Kafka hoặc Redis Streams, để xử lý và có thể cả một kho dữ liệu để lưu trữ.
Kiểm tra sự không phù hợp trở kháng
Mục tiêu của bài kiểm tra là đo lường mức độ phức tạp của nền tảng tổng thể và liệu độ phức tạp tăng lên hay giảm xuống khi bạn thêm nhiều tính năng hơn trong tương lai.
Cách thức hoạt động của thử nghiệm là chỉ cần tính toán “chi phí chuyển đổi” và “chi phí đường ống”, sử dụng “Điểm không phù hợp trở kháng” (IMS). Điều này sẽ cho bạn biết nếu hệ thống của bạn đã phức tạp so với các hệ thống khác và cũng như nếu độ phức tạp đó tăng lên theo thời gian khi bạn thêm nhiều tính năng hơn.
Đây là công thức để tính IMS:

Công thức chỉ cần thêm cả hai loại tổng chi phí và sau đó chia chúng cho số lượng tính năng. Bằng cách này, bạn sẽ nhận được tổng chi phí / tính năng (tức là điểm phức tạp).
Để hiểu rõ hơn điều này, hãy so sánh bốn đường ống dẫn dữ liệu đơn giản khác nhau và tính toán điểm số của chúng. Và thứ hai, hãy cũng tưởng tượng chúng tôi đang xây dựng một ứng dụng đơn giản theo hai giai đoạn, để chúng tôi có thể thấy điểm IMS thay đổi như thế nào khi chúng tôi thêm nhiều tính năng hơn theo thời gian.
Giai đoạn 1:Xây dựng trang tổng quan thời gian thực
Giả sử bạn đang nhận được hàng triệu sự kiện nhấp vào nút từ thiết bị di động và bạn cần cảnh báo nếu có bất kỳ sự sụt giảm hoặc tăng đột biến nào. Ngoài ra, bạn đang coi toàn bộ điều này như một tính năng của ứng dụng lớn hơn của mình.
Trường hợp 1:Giả sử bạn vừa sử dụng một RDBMS để lưu trữ các sự kiện này, mặc dù các bảng có thể không phù hợp.

- Chi phí chuyển đổi =1
- Bạn cần chuyển đổi các luồng sự kiện thành bảng.
- Chi phí đường ống =1
- Bạn có một DB duy nhất trong quy trình của mình.
- Số lượng tính năng =1
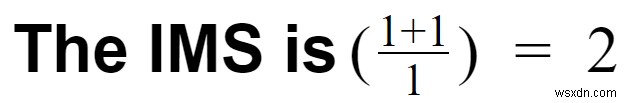
Trường hợp 2:Giả sử bạn đã sử dụng Kafka để xử lý các sự kiện này và sau đó lưu trữ chúng vào RDBMS.
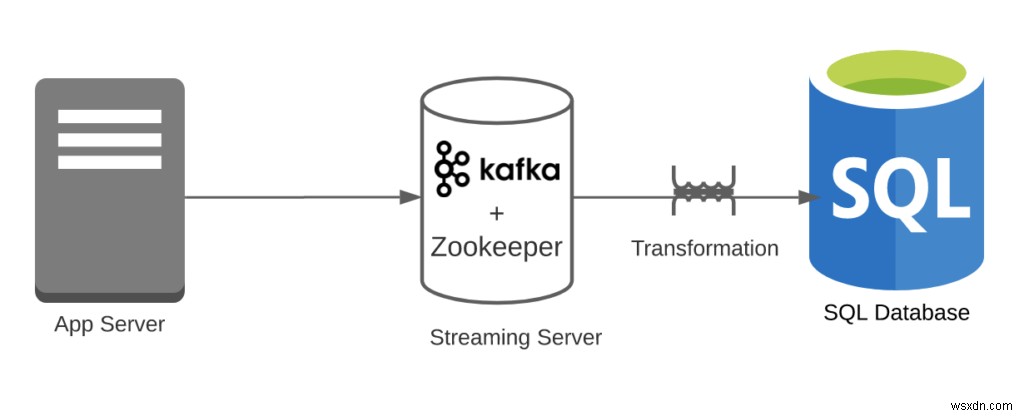
- Chi phí chuyển đổi =1
- Kafka có thể dễ dàng xử lý các luồng nhấp chuột; tuy nhiên, Kafka đến RDBMS là một chi phí.
- Chi phí đường ống =2
- Bạn có hai hệ thống (RDBMS và Kafka). Lưu ý rằng chúng tôi đang bỏ qua Zookeeper.
- Số lượng tính năng =1
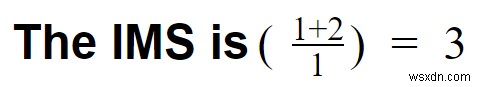
Trường hợp 3:Giả sử bạn đã sử dụng Kafka để xử lý các sự kiện này và sau đó lưu trữ chúng vào KsqlDB.
- Chi phí chuyển đổi =0
- Kafka có thể dễ dàng xử lý các luồng nhấp chuột
- Chi phí đường ống =1
- Bạn chỉ có một hệ thống (Kafka + KSqlDB). Xin lưu ý rằng chúng tôi đang bỏ qua Zookeeper.
- Số lượng tính năng =1
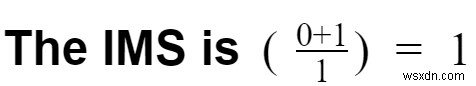
Trường hợp 4:Giả sử bạn đã sử dụng Redis Streams để xử lý các sự kiện này và sau đó lưu trữ chúng vào RedisTimeseries (cả hai đều là một phần của Redis và hoạt động nguyên bản với Redis).

- Chi phí chuyển đổi =0
- Redis Streams có thể dễ dàng xử lý các luồng nhấp chuột
- Chi phí đường ống =1
- Bạn chỉ có một hệ thống (Redis Streams + RedisTimeSeries)
- Số lượng tính năng =1
Kết luận sau Giai đoạn 1:
Chúng tôi đã so sánh bốn hệ thống trong ví dụ này và phát hiện ra rằng “Trường hợp 3” hoặc “Trường hợp 4” là đơn giản nhất với IMS là 1. Tại thời điểm này, cả hai đều giống nhau, nhưng liệu chúng có giống nhau không khi chúng tôi thêm nhiều tính năng hơn ?
Hãy thêm nhiều tính năng hơn vào hệ thống của chúng tôi và xem IMS hoạt động như thế nào.
Giai đoạn 2:Xây dựng Trang tổng quan thời gian thực với danh sách IP cho phép
Giả sử bạn đang xây dựng cùng một ứng dụng nhưng muốn đảm bảo rằng chúng chỉ đến từ các địa chỉ IP được liệt kê trong danh sách trắng. Bây giờ bạn đang thêm một tính năng mới.
Trường hợp 1:Giả sử bạn vừa sử dụng RDBMS để lưu trữ các sự kiện này, mặc dù các bảng có thể không phù hợp và chúng đã sử dụng Redis hoặc MemCached cho IP-whitelist.
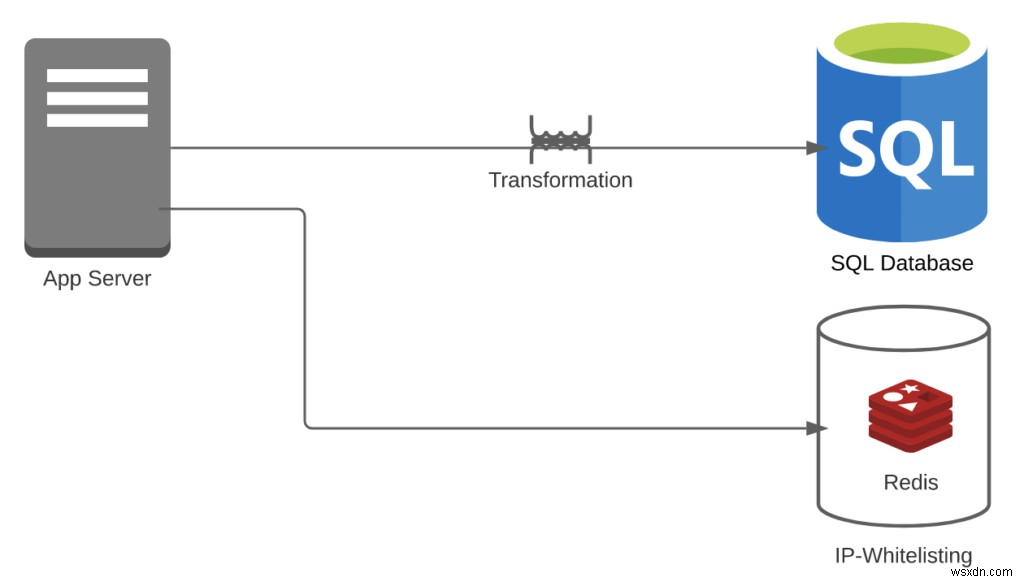
- Chi phí chuyển đổi =1
- Đối với danh sách IP cho phép, bạn không cần bất kỳ chuyển đổi nào. Tuy nhiên, bạn cần chuyển đổi các luồng sự kiện thành bảng
- Chi phí đường ống =2
- Bạn có Redis + RDBMS
- Số lượng tính năng =2

Trường hợp 2:Giả sử bạn đang sử dụng Redis + Kafka + RDBMS.
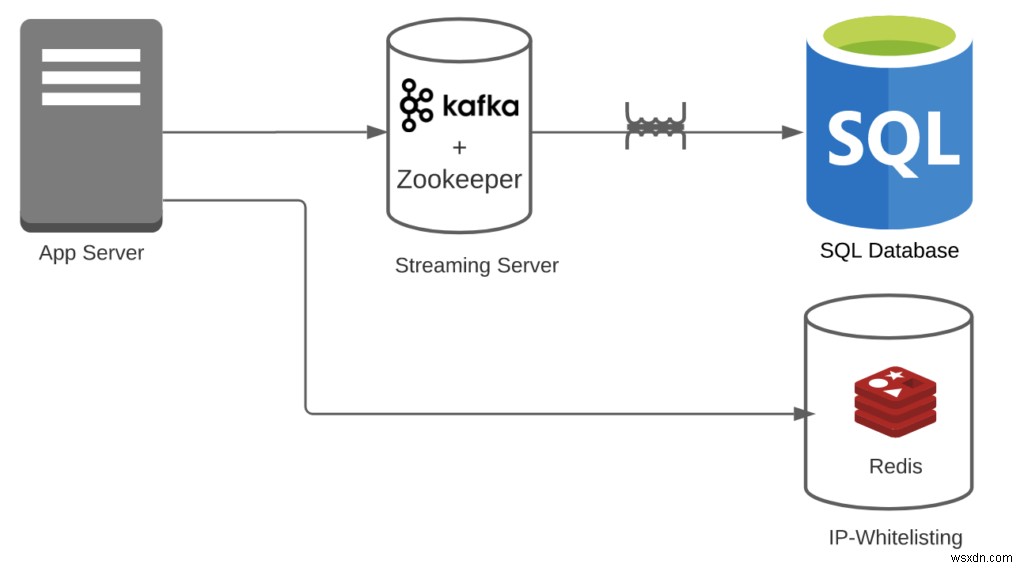
- Chi phí chuyển đổi =1
- Đối với danh sách IP cho phép, bạn không cần bất kỳ chuyển đổi nào. Ngoài ra, Kafka có thể dễ dàng xử lý các luồng.
- Chi phí đường ống =3
- Bạn có Redis + Kafka + RDBMS. Lưu ý:Chúng tôi đang bỏ qua rằng Kafka cũng cần Zookeeper. Nếu bạn thêm điều đó, con số sẽ giảm thêm.
- Số lượng tính năng =2

Trường hợp 3:Giả sử bạn đang sử dụng Redis + Kafka + KsqlDB.
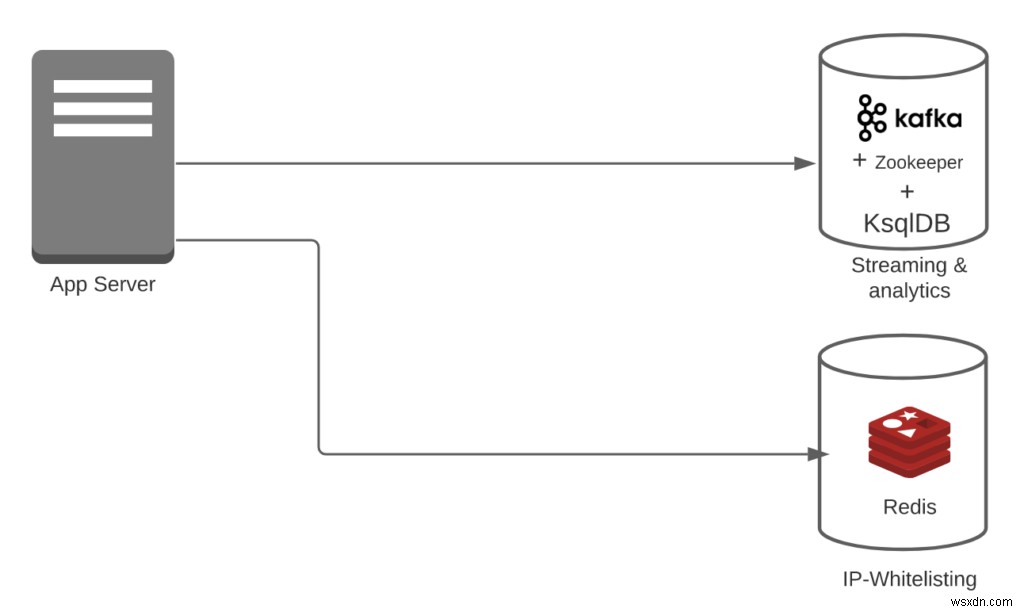
- Chi phí chuyển đổi =0
- Đối với danh sách IP cho phép, bạn không cần bất kỳ chuyển đổi nào. Ngoài ra, Kafka và KsqlDB có thể dễ dàng xử lý các luồng.
- Chi phí đường ống =2
- Bạn có Redis + (Kafka + KsqlDB). Lưu ý:Trong trường hợp này, chúng tôi đang xem xét Kafka + KsqlDB là một phần của cùng một hệ thống.
- Số lượng tính năng =2

Trường hợp 4:Giả sử bạn đang sử dụng Redis + Redis Streams + RedisTimeSeries.

- Chi phí chuyển đổi =0
- Đối với danh sách IP cho phép, bạn không cần bất kỳ chuyển đổi nào. Ngoài ra, Redis Streams và RedisTimeseries có thể dễ dàng xử lý các luồng và cảnh báo.
- Chi phí đường ống =1
- Bạn có Redis + Redis Streams + Redis TimeSeries. Lưu ý:Trong trường hợp này, cả ba đều thuộc cùng một hệ thống.
- Số lượng tính năng =2

Kết luận sau Giai đoạn 2:
Khi chúng tôi thêm một tính năng bổ sung,
- Trường hợp 1 ở mức 2 trong Giai đoạn 1 và giảm xuống 1,5.
- Trường hợp 2 ở mức 3 trong Giai đoạn 1 và giảm xuống còn 2
- Trường hợp 3 là 1 trong Giai đoạn 1 và vẫn ở 1
- Trường hợp 4 ở mức 1 trong Giai đoạn 1 và giảm xuống 0,5 (Tốt nhất)
Vì vậy, trong ví dụ của chúng tôi, Trường hợp 4, có một trong những điểm IMS thấp nhất là 1, thực sự đã trở nên tốt hơn khi chúng tôi thêm tính năng mới và nó kết thúc ở mức 0,5.
Xin lưu ý:Nếu bạn thêm nhiều hơn hoặc các tính năng khác nhau, Trường hợp 4 có thể không còn là đơn giản nhất. Nhưng đó là ý tưởng về điểm IMS. Chỉ cần liệt kê tất cả các tính năng, so sánh các kiến trúc khác nhau và xem cái nào là tốt nhất cho trường hợp sử dụng của bạn.
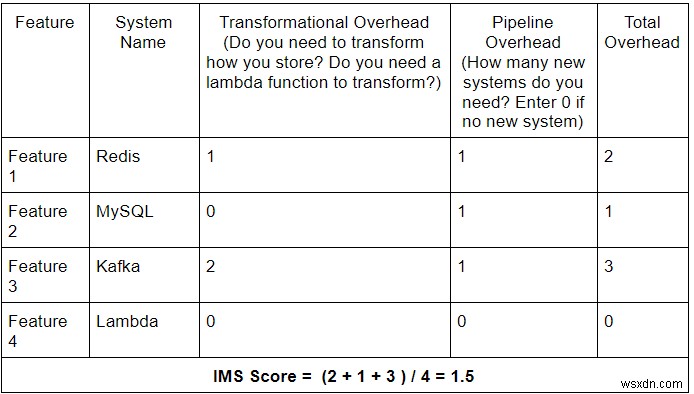
Để làm cho việc sử dụng đơn giản hơn nữa, chúng tôi đang cung cấp cho bạn một máy tính mà bạn có thể triển khai trong một bảng tính đơn giản để tính điểm IMS.
Máy tính IMS
Đây là cách bạn sử dụng nó:
- Đối với mỗi lớp dữ liệu hoặc đường ống dữ liệu, chỉ cần liệt kê ra:
- Các tính năng bạn hiện có.
- Các tính năng nằm trong lộ trình. Điều này rất quan trọng vì bạn muốn đảm bảo rằng lớp dữ liệu của mình có thể tiếp tục hỗ trợ các tính năng sắp tới mà không cần thêm bất kỳ chi phí nào.
- Sau đó, lập bản đồ tổng chi phí Chuyển đổi và chi phí đường ống cho từng đối tượng địa lý.
- Và cuối cùng, chia tổng của tất cả các chi phí chung cho số lượng tính năng.
- Lặp lại các bước 2 và 3 cho các đường ống dẫn với các hệ thống khác nhau để so sánh và đối chiếu chúng.
Đường ống dữ liệu 1
Đường ống dữ liệu 2

Tóm tắt
Rất dễ dàng bị thực hiện và xây dựng một lớp dữ liệu phức tạp mà không nghĩ đến hậu quả. Điểm IMS được tạo ra để giúp bạn tỉnh táo về quyết định của mình.
Bạn có thể sử dụng điểm IMS để dễ dàng so sánh và đối chiếu nhiều hệ thống cho trường hợp sử dụng của mình và xem hệ thống nào thực sự tốt nhất cho bộ tính năng của bạn. Bạn cũng có thể xác nhận xem hệ thống của bạn có thể tiếp tục mở rộng tính năng hay không và tiếp tục duy trì trạng thái đơn giản nhất có thể.
Luôn nhớ:
“Đơn giản là sự tinh tế cuối cùng” - Leonardo da Vinci
“ Hầu hết thông tin đều không liên quan và hầu hết nỗ lực đều bị lãng phí, nhưng chỉ chuyên gia mới biết nên bỏ qua điều gì ”- James Clear, Những thói quen nguyên tử