Việc tìm kiếm trên web không chỉ kích thích những người đam mê khoa học dữ liệu mà còn cho sinh viên hoặc người học, những người muốn tìm hiểu sâu hơn về các trang web. Python cung cấp nhiều thư viện webscraping bao gồm,
-
Trị liệu
-
Urllib
-
BeautifulSoup
-
Selen
-
Yêu cầu Python
-
LXML
Chúng ta sẽ thảo luận về thư viện lxml của python để quét dữ liệu từ một trang web, được xây dựng trên đầu thư viện phân tích cú pháp XML libxml2 được viết bằng C, giúp làm cho nó nhanh hơn Beautiful Soup nhưng cũng khó cài đặt hơn trên một số máy tính, đặc biệt là Windows .
Cài đặt và nhập lxml
lxml có thể được cài đặt từ dòng lệnh bằng pip,
pip install lxml
hoặc
conda install -c anaconda lxml
Sau khi cài đặt xong lxml, hãy nhập mô-đun html, mô-đun này sẽ phân tích cú pháp HTML từ lxml.
>>> from lxml import html
Truy xuất mã nguồn của trang mà bạn muốn cạo - chúng ta có hai lựa chọn có thể sử dụng thư viện yêu cầu python hoặc urllib và sử dụng nó để tạo đối tượng phần tử HTML lxml chứa toàn bộ HTML của trang. Chúng tôi sẽ sử dụng thư viện yêu cầu để tải xuống nội dung HTML của trang.
Để cài đặt các yêu cầu python, chỉ cần chạy lệnh đơn giản này trong thiết bị đầu cuối bạn chọn -
$ pipenv install requests
Thu thập dữ liệu từ tài chính yahoo
Giả sử chúng ta muốn lấy dữ liệu cổ phiếu / vốn chủ sở hữu từ google.finance hoặc yahoo.finance. Dưới đây là ảnh chụp màn hình của các tập đoàn Microsoft từ yahoo Finance,
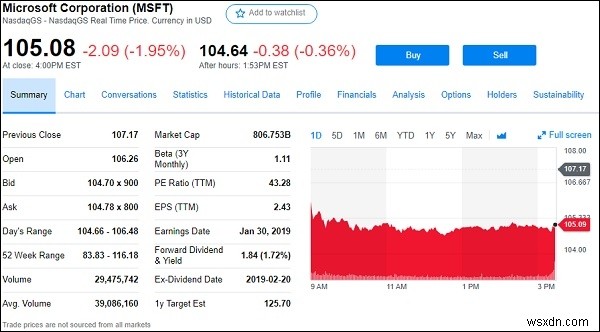
Vì vậy, từ phía trên ( https://finance.yahoo.com/quote/msft ), chúng tôi sẽ trích xuất tất cả các trường của kho hiển thị ở trên như,
-
Trước đó Đóng, Mở, Giá thầu, Hỏi, Phạm vi trong ngày, phạm vi 52 tuần, khối lượng, v.v.
Dưới đây là mã để thực hiện điều này bằng cách sử dụng mô-đun lxml của python -
lxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4) để chạy mã bên trên, hãy nhập đơn giản bên dưới vào dòng lệnh của bạn -
c:\Python\Python361>python lxml_scrape3.py MSFT
Khi chạy lxml_scrap3.py, bạn sẽ thấy, một tệp .json được tạo trong thư mục làm việc hiện tại của bạn có tên giống như "stockName-Summary.json" vì tôi đang cố gắng trích xuất các trường msft (microsoft) từ yahoo Finance, vì vậy một tệp là được tạo bằng tên - "msft-Summary.json".
Dưới đây là ảnh chụp màn hình của kết quả được tạo -
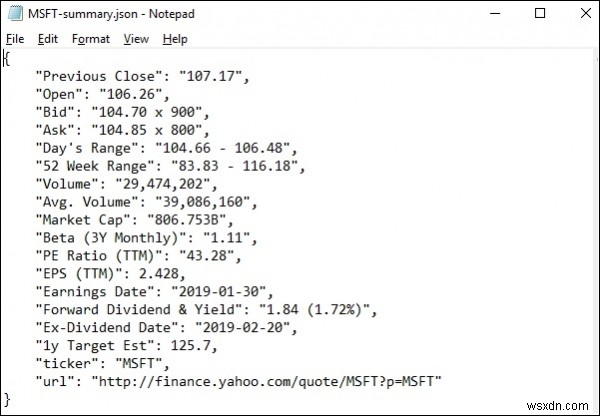
Vì vậy, chúng tôi đã trích xuất thành công tất cả dữ liệu cần thiết từ yahoo.finance của microsoft bằng cách sử dụng lxml và các yêu cầu, sau đó lưu dữ liệu vào một tệp mà sau này có thể được sử dụng để chia sẻ hoặc phân tích biến động giá của cổ phiếu microsoft.