Một trong những khuôn khổ tốt nhất để phát triển trình thu thập thông tin là liệu pháp. Scrapy là một khung thu thập dữ liệu và thu thập dữ liệu web phổ biến sử dụng chức năng cấp cao để làm cho việc tìm kiếm các trang web dễ dàng hơn.
Cài đặt
Cài đặt scrapy trong windows rất dễ dàng:chúng ta có thể sử dụng pip hoặc conda (nếu bạn có anaconda). Scrapy chạy trên cả phiên bản python 2 và 3.
pip cài đặt Scrapy
Hoặc
conda install –c conda-forge scrapy
Nếu Scrapy được cài đặt đúng cách, một lệnh Scrapy bây giờ sẽ có sẵn trong thiết bị đầu cuối -
C:\ Users \ rajesh> scrapyScrapy 1.6.0 - không có dự án nào đang hoạt độngUsage:scrapy[options] [args] Các lệnh có sẵn:bench Chạy nhanh benchmark testfetch Tìm nạp URL bằng cách sử dụng Scrapy downloadergenspider Tạo nhện mới bằng pre- đã định nghĩa templaterunspider Chạy cài đặt một trình thu thập dữ liệu độc lập (không tạo dự án) Nhận cài đặt valuesshell Consolestartproject cạo tương tác Tạo dự án mới Print Scrapy versionview Mở URL trong trình duyệt, như được thấy bởi Scrapy [chi tiết] Có thêm lệnh khi chạy từ thư mục dự án Sử dụng "scrapy -h "để xem thêm thông tin về một lệnh.
Bắt đầu một dự án
Bây giờ Scrapy đã được cài đặt, chúng tôi có thể chạy startproject lệnh để tạo cấu trúc mặc định cho dự án Scrapy đầu tiên của chúng tôi.
Để thực hiện việc này, hãy mở terminal và điều hướng đến thư mục mà bạn muốn lưu trữ dự án Scrapy của mình, sau đó chạy scrapy startproject
C:\ Users \ rajesh> scrapy startproject scrapy_example Dự án Scrapy mới 'scrapy_example', sử dụng thư mục mẫu 'c:\ python \ python361 \ lib \ site-package \ scrapy \ templates \ project', được tạo trong:C:\ Users \ rajesh \ scrapy_exampleBạn có thể bắt đầu con nhện đầu tiên của mình bằng:cd scrapy_examplescrapy genspider example example.comC:\ Users \ rajesh> cd scrapy_exampleC:\ Users \ rajesh \ scrapy_example> tree / FFolder PATH list Số sê-ri là 8CD6-8D39C:.│ scrapy. cfg│└───scrapy_example │ items.py │ middlewares.py │ pipelines.py │ settings.py │ __init__.py │ ├───spiders │ │ __init__.py │ │ │ └───__pycache__ └─── __pycache__
Một cách khác là chúng tôi chạy shell scrapy và thực hiện quét web, như bên dưới -
Trong [18]:fetch ("https://www.wsj.com/india")019-02-04 22:38:53 [scrapy.core.engine] DEBUG:Crawled (200) "rel =" nofollow noopener noreferrer "target =" _blank "> https://www.wsj.com/india> (giới thiệu:Không có) Trình thu thập dữ liệu sẽ trả về một đối tượng "phản hồi" có chứa thông tin đã tải xuống. Hãy kiểm tra xem trình thu thập thông tin ở trên của chúng tôi chứa những gì -
Trong [19]:xem (phản hồi) Hết [19]:Đúng
Và trong trình duyệt mặc định của bạn, liên kết web sẽ mở ra và bạn sẽ thấy một cái gì đó giống như -

Tuyệt vời, trang này trông hơi giống với trang web của chúng tôi, vì vậy trình thu thập thông tin đã tải xuống thành công toàn bộ trang web.
Bây giờ, hãy xem trình thu thập thông tin của chúng ta chứa những gì -
Trong [22]:print (response.text)The Wall Street Journal &Breaking News, Business, Financial and Economic News, World News and Video … và nhiều hơn thế nữa:Hãy cố gắng trích xuất một vài thông tin quan trọng từ trang web này -
Trích xuất tiêu đề của trang web -
Scrapy cung cấp các cách để trích xuất thông tin từ HTML dựa trên các bộ chọn css như lớp, id, v.v. Để tìm bộ chọn css cho tiêu đề của bất kỳ tiêu đề trang web nào, chỉ cần nhấp chuột phải và nhấp vào kiểm tra, như dưới đây:
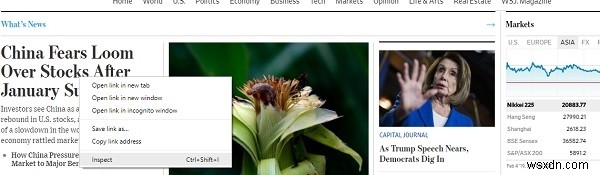
Thao tác này sẽ mở các công cụ dành cho nhà phát triển trong cửa sổ trình duyệt của bạn -
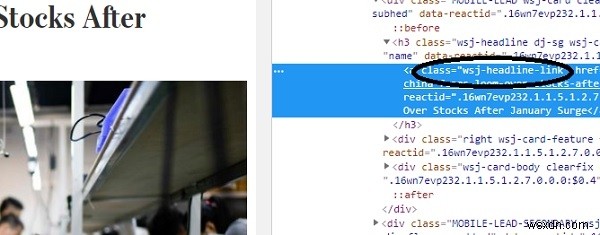
Như có thể thấy, lớp css "wsj-headline-link" được áp dụng cho tất cả các thẻ neo () có tiêu đề. Với thông tin này, chúng tôi sẽ cố gắng tìm tất cả các tiêu đề từ phần còn lại của nội dung trong đối tượng phản hồi -
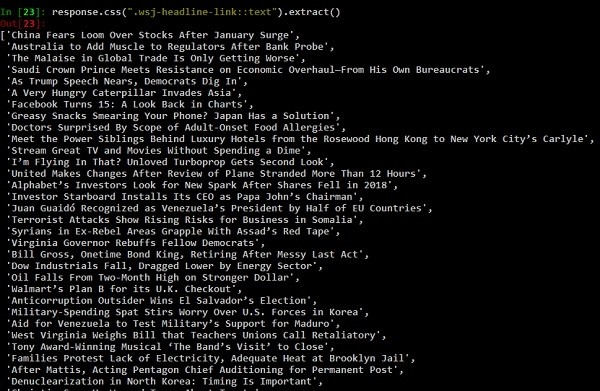
Response.css () là hàm sẽ trích xuất nội dung dựa trên bộ chọn css được chuyển cho nó (giống như thẻ neo ở trên). Hãy xem thêm một số ví dụ về hàm response.css của chúng tôi.
Trong [24]:response.css (". wsj-headline-link ::text"). extract_first () Out [24]:'Trung Quốc lo sợ về hàng tồn kho sau đợt tăng đột biến tháng 1'và
Trong [25]:response.css (". wsj-headline-link"). extract_first () Out [25]:' China Fears Loom Over Stocks sau đợt tăng tháng 1 'Để nhận tất cả các liên kết từ trang web -
links =response.css ('a ::attr (href)'). extract ()Đầu ra
['https://www.google.com/intl/en_us/chrome/browser/desktop/index.html','https://support.apple.com/downloads/','https:// www.mozilla.org/en-US/firefox/new/','https://windows.microsoft.com/en-us/internet-explorer/download-ie','https://www.barrons.com ',' http://bigcharts.marketwatch.com','https://www.wsj.com/public/page/wsj-x-marketing.html','https://www.dowjones.com/ ' , 'https://global.factiva.com/factivalogin/login.asp? productname =global', 'https://www.fnlondon.com/','https://www.mansionglobal.com/', ' https://www.marketwatch.com','https://newsplus.wsj.com','https://privatemarkets.dowjones.com','https://djlogin.dowjones.com/login.asp? productname =rnc ',' https://www.wsj.com/conferences','https://www.wsj.com/pro/centralbanking','https://www.wsj.com/video/ ', 'https://www.wsj.com','http://www.bigdecisions.com/','https://www.businessspectator.com.au/','https://www.checkout51.com /?utm_source=wsj&utm_medium=digitalhousead&utm_campaign=wsjspotlight','https://www.harpercollins.com/','https://housing. com / ',' https://www.makaan.com/','https://nypost.com/','https://www.newsamerica.com/','https://www.proptiger. com ',' https://www.rea-group.com/',…………Để nhận số lượng nhận xét từ trang web wsj (tạp chí đường phố trên tường) -
Trong [38]:response.css (". wsj-comment-count ::text"). extract () Out [38]:['71', '59']Trên đây chỉ là phần giới thiệu về cách nạo web thông qua phương pháp trị liệu, chúng ta có thể làm được nhiều điều hơn nữa với phương pháp trị liệu.