Nhện trị liệu
Nhện trị liệu là một lớp cung cấp cơ sở để đi theo các liên kết của một trang web và trích xuất thông tin từ các trang web.
Đây là lớp chính mà các nhện khác phải kế thừa.
Scrapinghub
Scrapinghub là một ứng dụng mã nguồn mở để chạy các con nhện Scrapy. Scrapinghub biến nội dung web thành một số dữ liệu hoặc thông tin hữu ích. Nó cho phép chúng tôi trích xuất dữ liệu từ các trang web, ngay cả đối với các trang web phức tạp.
Chúng tôi sẽ sử dụng scrapinghub để triển khai các trình thu thập dữ liệu trên đám mây và thực thi nó.
Các bước để triển khai các trình thu thập thông tin trên scrapinghub -
Bước 1 -
Tạo một dự án trị liệu -
Sau khi cài đặt scrapy, chỉ cần chạy lệnh sau trong thiết bị đầu cuối của bạn -
$scrapy startproject <project_name>
Thay đổi thư mục của bạn thành dự án mới (project_name).
Bước 2 -
Viết một con nhện trị liệu cho trang web mục tiêu của bạn, hãy sử dụng một trang web thông thường "quote.toscrape.com".
Dưới đây là con nhện trị liệu rất đơn giản của tôi -
Mã -
#import scrapy library
import scrapy
class AllSpider(scrapy.Spider):
crawled = set()
#Spider name
name = 'all'
#starting url
start_urls = ['http://www.tutorialspoint.com/']
def __init__(self):
self.links = []
def parse(self, response):
self.links.append(response.url)
for href in response.css('a::attr(href)'):
yield response.follow(href, self.parse) Bước 3 -
Chạy trình thu thập dữ liệu của bạn và lưu đầu ra vào tệp links.json của bạn -
Sau khi thực thi đoạn mã trên, bạn sẽ có thể quét tất cả các liên kết và lưu nó vào bên trong tệp links.json. Đây có thể không phải là một quá trình dài nhưng để chạy nó liên tục suốt ngày đêm (24/7), chúng tôi cần triển khai con nhện này trên Scrapinghub.
Bước 4 -
Tạo tài khoản trên Scrapinghub
Đối với điều đó, bạn chỉ cần đăng nhập vào trang đăng nhập ScrapingHub bằng tài khoản Gmail hoặc Github. Nó sẽ chuyển hướng đến trang tổng quan.
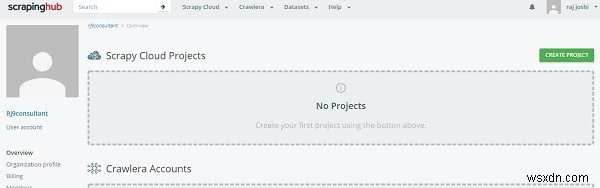
Bây giờ hãy nhấp vào Tạo dự án và đề cập đến tên của dự án. Bây giờ chúng ta có thể thêm dự án của mình vào đám mây bằng cách sử dụng dòng lệnh (CLI) hoặc thông qua github. Tiếp theo, chúng ta sẽ triển khai mã của mình thông qua shub CLI, trước tiên hãy cài đặt shub
$pip install shub
Sau khi cài đặt shub, hãy đăng nhập vào tài khoản shub bằng cách sử dụng khóa api được tạo khi tạo tài khoản (Nhập khóa API của bạn từ https://app.scrapinghub.com/account/apikey).
$shub login
Nếu khóa API của bạn OK, bạn đã đăng nhập ngay bây giờ. Bây giờ chúng ta cần triển khai nó bằng cách sử dụng Id triển khai mà bạn thấy trên phần dòng lệnh của phần "triển khai mã của bạn" (số gồm 6 chữ số).
$ shub deploy deploy_id
Đó là nó từ dòng lệnh, bây giờ quay trở lại trên phần bảng điều khiển Spiders, người dùng có thể thấy con nhện đã sẵn sàng. Chỉ cần nhấp vào tên nhện và vào nút Chạy.
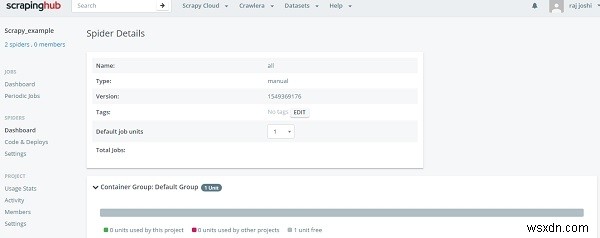
Nó sẽ cho chúng tôi thấy tiến trình chạy thông qua một cú nhấp chuột và bạn không cần phải chạy máy cục bộ của mình 24/7.