Phát triển phần mềm có thể là một thách thức, nhưng duy trì nó còn khó hơn nhiều. Bảo trì bao gồm các bản vá lỗi phần mềm và bảo trì máy chủ. Trong bài đăng này, chúng tôi sẽ tập trung vào quản lý và bảo trì máy chủ.
Theo truyền thống, các máy chủ là tại chỗ, có nghĩa là mua và bảo trì phần cứng vật lý. Với điện toán đám mây, các máy chủ này không còn cần phải thuộc sở hữu vật lý nữa. Năm 2006, khi Amazon bắt đầu sử dụng AWS và giới thiệu dịch vụ EC2 của mình, kỷ nguyên của điện toán đám mây hiện đại bắt đầu. Với loại dịch vụ này, chúng tôi không cần duy trì máy chủ vật lý hoặc nâng cấp phần cứng vật lý nữa. Điều này đã giải quyết được rất nhiều vấn đề, nhưng việc bảo trì máy chủ và quản lý tài nguyên vẫn phụ thuộc vào chúng tôi. Đưa những phát triển này lên cấp độ tiếp theo, giờ đây chúng tôi có công nghệ không máy chủ.
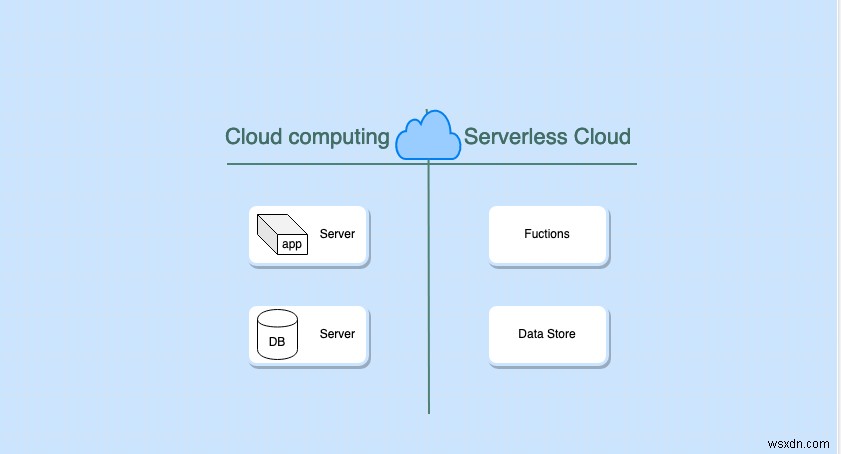
Công nghệ không máy chủ là gì?
Công nghệ không máy chủ giúp giảm tải công việc quản lý và cung cấp máy chủ cho nhà cung cấp đám mây. Trong bài đăng này, chúng ta sẽ thảo luận về AWS.
Thuật ngữ serverless không có nghĩa là không có máy chủ nào cả. Có một máy chủ, nhưng nó được quản lý hoàn toàn bởi nhà cung cấp đám mây. Theo một nghĩa nào đó, đối với những người sử dụng công nghệ không máy chủ, không có máy chủ hiển thị. Các máy chủ không hiển thị trực tiếp với chúng tôi và công việc quản lý chúng được tự động hóa bởi nhà cung cấp dịch vụ đám mây. Dưới đây là một số đặc điểm khiến nó không có máy chủ:
- Không cần quản lý vận hành - Không cần vá các máy chủ hoặc quản lý chúng để có tính khả dụng cao;
- Mở rộng quy mô khi cần - Từ chỉ phục vụ một vài người dùng đến phục vụ hàng triệu người dùng;
- Thanh toán khi bạn di chuyển - Chi phí được quản lý dựa trên mức sử dụng.
Công nghệ không máy chủ có thể được phân loại như sau:
- Tính toán (ví dụ:Lambda và Fargate)
- Bộ nhớ (ví dụ:S3)
- Lưu trữ Dữ liệu (ví dụ:DynamoDB và Aurora)
- Tích hợp (ví dụ:API Gateway, SNS và SQS)
- Phân tích (ví dụ:Kinesis và Athena)
Tại sao sử dụng Công nghệ Serverless?
Chi phí
Thanh toán khi bạn đi là một trong những lợi thế chính của việc sử dụng công nghệ không máy chủ. Khi có sự thay đổi không thể đoán trước về lưu lượng truy cập, bạn cần phải mở rộng máy chủ lên hoặc xuống dựa trên các kiểu sử dụng, nhưng việc mở rộng quy mô bằng tính năng tự động định tỷ lệ tự quản lý có thể khó khăn và không hiệu quả. Máy tính không máy chủ, chẳng hạn như AWS Lambda, có thể dễ dàng giúp tiết kiệm chi phí vì không cần thanh toán trong thời gian nhàn rỗi.
Năng suất của Nhà phát triển
Vì điện toán không máy chủ đề cập đến các dịch vụ được quản lý hoàn toàn do nhà cung cấp đám mây cung cấp, nên các nhà phát triển không cần cung cấp máy chủ hoặc phát triển các ứng dụng máy chủ. Các nhà phát triển có thể bắt đầu viết mã ngay lập tức mà không cần quản lý máy chủ. Cách tiếp cận này cũng loại bỏ nhu cầu vá lỗi máy chủ hoặc quản lý tự động thay đổi tỷ lệ. Tiết kiệm toàn bộ thời gian này sẽ giúp tăng năng suất của nhà phát triển.
Độ co giãn
Máy tính không máy chủ có tính đàn hồi cao và có thể tăng hoặc giảm quy mô dựa trên việc sử dụng. Có thể dễ dàng xử lý lượng người dùng tăng đột biến. Đây có thể là một lợi thế lớn và giúp tiết kiệm rất nhiều thời gian cho các nhà phát triển.
Tính sẵn sàng cao
Khi máy tính không có máy chủ và được quản lý bởi một nhà cung cấp đám mây và các máy chủ có thời gian hoạt động cao, các chuyển đổi dự phòng được xử lý tự động. Quản lý những loại vấn đề này đòi hỏi các kỹ năng chuyên biệt. Với cách tiếp cận không máy chủ, công việc của các tổ chức và nhà phát triển có thể được thực hiện bởi một người duy nhất.
Cách triển khai chức năng không cần máy chủ trong Ruby
Theo AWS, Ruby là một trong những ngôn ngữ được sử dụng rộng rãi nhất trong AWS. Lambda bắt đầu hỗ trợ Ruby vào tháng 11 năm 2018. Chúng tôi sẽ xây dựng một API web bằng Ruby chỉ sử dụng các công nghệ không máy chủ do AWS cung cấp.
Để tạo cơ sở hạ tầng không máy chủ trong AWS, chúng tôi chỉ cần đăng nhập vào bảng điều khiển AWS và bắt đầu tạo chúng. Tuy nhiên, chúng tôi muốn phát triển một thứ gì đó có thể dễ dàng kiểm tra được và tạo điều kiện thuận lợi cho việc khắc phục hậu quả sau thảm họa. Chúng tôi sẽ viết tính năng không có máy chủ dưới dạng mã. Để làm như vậy, AWS cung cấp mô hình ứng dụng không máy chủ (SAM). SAM là một khuôn khổ được sử dụng để xây dựng các ứng dụng không máy chủ trong AWS. Nó cung cấp cú pháp dựa trên YAML để thiết kế Lambda, cơ sở dữ liệu và API. Các ứng dụng AWS SAM có thể được tạo bằng AWS SAM-CLI, bạn có thể tải xuống ứng dụng này qua liên kết này.
AWS SAM CLI được xây dựng dựa trên AWS Cloudformation. Nếu bạn đã quen với việc viết IaC với CoudFormation, điều này sẽ rất đơn giản. Ngoài ra, bạn cũng có thể sử dụng khung công tác không máy chủ. Trong bài đăng này, tôi sẽ sử dụng AWS SAM.
Trước khi sử dụng SAM CLI, hãy đảm bảo bạn có những điều sau:
- Thiết lập cấu hình AWS
- Docker đã được cài đặt
- SAM CLI đã được cài đặt
Chúng tôi sẽ phát triển một ứng dụng không máy chủ. Chúng tôi sẽ bắt đầu bằng cách tạo một vài cơ sở hạ tầng không máy chủ, chẳng hạn như DynamoDB và Lambda, trong ứng dụng của chúng tôi. Hãy để chúng tôi bắt đầu với cơ sở dữ liệu:
DynamoDB
DynamoDB là một dịch vụ cơ sở dữ liệu không máy chủ do AWS quản lý. Vì nó không có máy chủ nên nó rất nhanh chóng và dễ dàng thiết lập. Để tạo DynamoDB, chúng tôi xác định mẫu SAM như sau:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
Với SAM CLI và mẫu trên, chúng ta có thể tạo một bảng DynamoDB cơ bản. Đầu tiên, chúng ta cần xây dựng một gói cho ứng dụng không máy chủ của mình. Đối với điều này, chúng tôi chạy lệnh sau. Điều này sẽ xây dựng gói và đẩy nó lên s3. Đảm bảo rằng bạn đã tạo nhóm s3 với tên serverless-users-bucket trước khi chạy lệnh:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
Hiện tại, s3 trở thành nguồn cho mẫu và mã cho ứng dụng không máy chủ của chúng tôi, chúng ta sẽ nói về điều này khi chúng ta tạo một hàm Lambda cho nó.
Bây giờ chúng tôi có thể triển khai mẫu này để tạo DynamoDB:
$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
Với điều này, chúng tôi đã thiết lập DynamoDB tại chỗ. Tiếp theo, chúng ta sẽ tạo một Lambda, nơi bảng này sẽ được sử dụng.
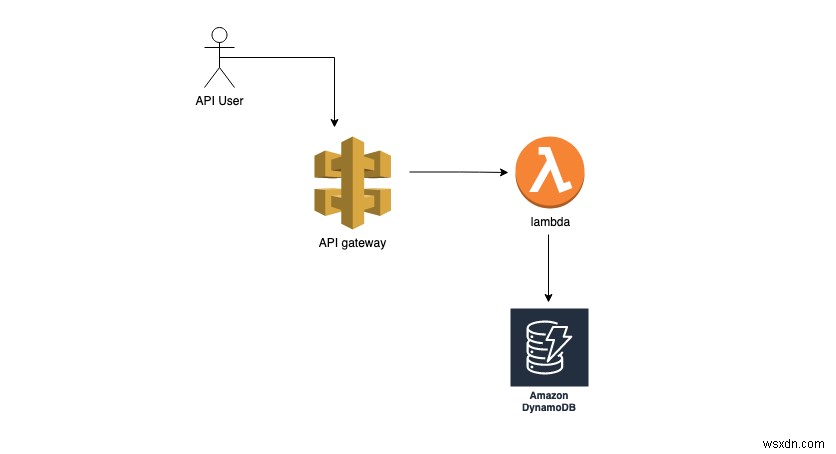
Lambda
Lambda là một dịch vụ điện toán không máy chủ do AWS cung cấp. Nó có thể được sử dụng để thực thi mã khi cần thiết mà không yêu cầu quản lý máy chủ thực tế, nơi mã được thực thi. Lambda có thể được sử dụng để chạy các quy trình Async, REST API hoặc bất kỳ công việc đã lên lịch nào. Tất cả những gì chúng ta cần làm là viết một hàm xử lý và đẩy chức năng lên AWS Lambda. Lambda sẽ thực hiện công việc thực thi tác vụ dựa trên sự kiện . Một sự kiện có thể được kích hoạt bởi nhiều nguồn khác nhau, chẳng hạn như cổng API, SQS hoặc S3; nó cũng có thể được kích hoạt bởi một codebase khác. Khi được kích hoạt, hàm Lambda này nhận các sự kiện và tham số ngữ cảnh. Các giá trị trong các thông số này khác nhau dựa trên nguồn của trình kích hoạt. Chúng ta cũng có thể kích hoạt hàm Lambda theo cách thủ công hoặc theo chương trình bằng cách chuyển các sự kiện này đến trình xử lý. Một trình xử lý nhận hai đối số:
Sự kiện - Sự kiện thường là một mã băm khóa-giá trị được truyền từ nguồn của trình kích hoạt. Các giá trị này được tự động chuyển khi chúng được kích hoạt bởi nhiều nguồn khác nhau, chẳng hạn như SQS, Kinesis hoặc cổng API. Khi kích hoạt theo cách thủ công, chúng tôi có thể vượt qua các sự kiện tại đây. Sự kiện chứa dữ liệu đầu vào cho trình xử lý hàm Lambda. Ví dụ:trong một cổng API, nội dung yêu cầu được chứa bên trong sự kiện này.
Bối cảnh - Context là đối số thứ hai trong hàm xử lý. Điều này chứa các chi tiết cụ thể, bao gồm nguồn của trình kích hoạt, tên hàm Lambda, phiên bản, id yêu cầu và hơn thế nữa.
Đầu ra của trình xử lý được chuyển trở lại dịch vụ đã kích hoạt hàm Lambda. Đầu ra của một hàm Lambda là giá trị trả về của hàm xử lý.
AWS Lambda hỗ trợ bảy ngôn ngữ khác nhau mà bạn có thể viết mã, bao gồm cả Ruby. Ở đây, chúng tôi sẽ sử dụng AWS Ruby-sdk để kết nối với DynamoDB.
Trước khi viết mã, chúng ta hãy tạo cơ sở hạ tầng cho Lambda bằng cách sử dụng mẫu SAM:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
Trong trình xử lý, chúng tôi viết tham chiếu đến hàm sẽ được thực thi dưới dạng Handler: <filename>.<method_name> .
Tham khảo mẫu chính sách không máy chủ để biết chính sách mà bạn có thể đính kèm vào Lambda dựa trên tài nguyên mà nó sử dụng. Vì hàm Lambda của chúng tôi ghi vào DynamoDB, chúng tôi đã sử dụng DynamoDBWritePolicy trong phần chính sách.
Chúng tôi cũng đang cung cấp biến env USERS_TABLE cho hàm Lambda để nó có thể gửi yêu cầu đến cơ sở dữ liệu được chỉ định.
Vì vậy, đó là những gì chúng ta cần cho cơ sở hạ tầng Lambda. Bây giờ, chúng ta hãy viết mã để tạo một người dùng trong DynamoDB, mà hàm Lambda sẽ thực thi.
Thêm bản ghi AWS vào Gemfile:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
Thêm mã để ghi đầu vào DynamoDB:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
Nó rất nhanh chóng và dễ dàng. AWS cung cấp aws-record gem để truy cập DynamoDB, rất giống với activerecord của Rails .
Tiếp theo, chạy các lệnh sau để cài đặt các phần phụ thuộc.
Lưu ý:Đảm bảo rằng bạn có cùng một phiên bản Ruby như được định nghĩa trong Lambda. Ví dụ ở đây, bạn cần cài đặt Ruby2.7 trên máy của mình.
# install dependencies
$ bundle install
$ bundle install --deployment
Đóng gói các thay đổi:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
Triển khai:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
Với mã này, bây giờ chúng ta có Lambda đang chạy, có thể ghi đầu vào vào cơ sở dữ liệu. Chúng tôi có thể thêm một cổng API phía trước Lambda để chúng tôi có thể truy cập nó thông qua các cuộc gọi HTTP. Cổng API cung cấp rất nhiều chức năng quản lý API, chẳng hạn như giới hạn tốc độ và xác thực. Tuy nhiên, nó có thể trở nên đắt tiền dựa trên cách sử dụng. Có một lựa chọn rẻ hơn là chỉ sử dụng API HTTP mà không cần quản lý API. Dựa trên trường hợp sử dụng, bạn có thể chọn một cách thích hợp nhất.
AWS Lambda có một vài giới hạn. Một số trong số chúng có thể được sửa đổi, nhưng một số khác đã được sửa:
- Bộ nhớ - Theo mặc định, Lambda có bộ nhớ 128 MB trong thời gian thực thi của nó. Điều này có thể được tăng lên đến 3.008 MB với gia số là 64 MB.
- Hết giờ - Hàm Lambda có giới hạn thời gian thực thi mã. Giới hạn mặc định là 3 giây. Thời gian này có thể tăng lên đến 900 giây.
- Bộ nhớ - Lambda cung cấp một
/tmpthư mục để lưu trữ. Giới hạn của bộ nhớ này là 512 MB. - Kích thước yêu cầu và phản hồi - Tối đa 6 MB cho trình kích hoạt đồng bộ và 256 MB cho trình kích hoạt không đồng bộ.
- Biến môi trường - Lên đến 4KB
Vì Lambda có một số giới hạn này, nên tốt hơn là viết mã phù hợp với những giới hạn này. Trong trường hợp không có, chúng tôi có thể tách mã để một Lambda kích hoạt một Lambda khác. Ngoài ra còn có một hàm bước do AWS cung cấp, có thể được sử dụng để trình tự nhiều hàm Lambda.
Làm cách nào chúng tôi có thể kiểm tra cục bộ các ứng dụng không máy chủ?
Đối với các ứng dụng không máy chủ, chúng ta cần có nhà cung cấp cung cấp dịch vụ không máy chủ được quản lý. Chúng tôi phụ thuộc vào AWS để kiểm tra ứng dụng của mình. Để kiểm tra ứng dụng, có một vài tùy chọn cục bộ do AWS cung cấp. Một số công cụ nguồn mở tương thích với công nghệ không máy chủ AWS cũng có thể được sử dụng để kiểm tra ứng dụng cục bộ.
Hãy để chúng tôi kiểm tra hàm Lambda và DynamoDB. Để làm như vậy, chúng tôi cần chạy các tệp này cục bộ.
Đầu tiên, tạo một mạng docker. Mạng sẽ giúp giao tiếp giữa hàm Lambda và DynamoDB.
$ docker network create lambda-local --docker-network lambda-local
DynamoDB cục bộ là phiên bản cục bộ của DynamoDB do AWS cung cấp, chúng tôi có thể sử dụng để kiểm tra cục bộ. Chạy DynamoDB cục bộ bằng cách chạy hình ảnh docker sau:
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
Thêm dòng sau vào user.rb tập tin. Điều này sẽ kết nối Lambda với DynamoDB cục bộ:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
Thêm input.json tệp, chứa đầu vào cho Lambda:
{
"name": "Milap Neupane",
"location": "Global"
}
Trước khi thực thi Lambda, chúng ta cần thêm bảng vào DynamoDB cục bộ. Để làm như vậy, chúng tôi sẽ sử dụng chức năng di chuyển do aws-migrate cung cấp. Hãy để chúng tôi tạo một tệp migrate.rb và thêm quá trình di chuyển sau:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
Cuối cùng, thực thi Lambda cục bộ bằng lệnh sau:
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
Thao tác này sẽ tạo dữ liệu của người dùng trong bảng DynamoDB.
Có các tùy chọn, chẳng hạn như localstack, để chạy các ngăn xếp AWS cục bộ.
Khi nào nên sử dụng máy tính không máy chủ
Khi quyết định có sử dụng máy tính không máy chủ hay không, chúng ta cần nhận thức được cả lợi ích và thiếu sót của nó. Dựa trên các đặc điểm sau, chúng tôi có thể quyết định thời điểm sử dụng phương pháp không máy chủ:
Chi phí
- Khi ứng dụng có thời gian nhàn rỗi và lưu lượng truy cập không nhất quán, Lambdas rất phù hợp vì chúng giúp giảm chi phí.
- Khi ứng dụng có lưu lượng truy cập nhất quán, việc sử dụng AWS Lambda có thể tốn kém.
Hiệu suất
- Nếu ứng dụng không nhạy cảm về hiệu suất, sử dụng AWS Lambda là một lựa chọn tốt.
- Lambdas có thời gian khởi động lạnh, điều này có thể gây ra thời gian phản hồi chậm trong quá trình khởi động nguội.
Xử lý nền
- Lambda là một lựa chọn tốt để sử dụng cho quá trình xử lý nền. Một số công cụ mã nguồn mở, chẳng hạn như Sidekiq, có chi phí bảo trì và mở rộng máy chủ. Chúng tôi có thể kết hợp hàng đợi AWS Lambda và AWS SQS để xử lý các công việc nền mà không gặp rắc rối trong việc bảo trì máy chủ.
Xử lý đồng thời
- Như chúng ta đã biết, đồng thời trong Ruby không phải là điều chúng ta có thể làm dễ dàng. Với Lambda, chúng ta có thể đạt được sự đồng thời mà không cần đến sự hỗ trợ của ngôn ngữ lập trình. Lambda có thể được thực thi đồng thời và giúp cải thiện hiệu suất.
Chạy tập lệnh định kỳ hoặc một lần
- Chúng tôi sử dụng công việc cron để thực thi mã Ruby, nhưng việc bảo trì máy chủ cho công việc cron có thể khó khăn đối với các ứng dụng quy mô lớn. Sử dụng Lambdas dựa trên sự kiện sẽ giúp mở rộng các ứng dụng.
Đây là một số trường hợp sử dụng cho các hàm Lambda trong các ứng dụng không có máy chủ. Chúng tôi không cần phải xây dựng mọi thứ không có máy chủ; chúng ta có thể xây dựng một mô hình kết hợp cho các trường hợp sử dụng được chỉ định ở trên. Điều này giúp mở rộng ứng dụng và tăng năng suất của nhà phát triển. Công nghệ không máy chủ đang phát triển và ngày càng tốt hơn. Có các công nghệ không máy chủ khác, chẳng hạn như AWS Fatgate và Google CloudRun, không có các hạn chế của AWS Lambda.