Nguồn đầy đủ trên Github
Bản triển khai hoàn chỉnh của ngôn ngữ lập trình Stoffle có sẵn tại GitHub. Việc triển khai tài liệu tham khảo này có rất nhiều nhận xét để giúp việc đọc mã dễ dàng hơn. Vui lòng mở vấn đề nếu bạn tìm thấy lỗi hoặc có thắc mắc.
Trong bài đăng trên blog này, chúng ta sẽ triển khai trình phân tích cú pháp cho Stoffle, một ngôn ngữ lập trình đồ chơi được xây dựng hoàn toàn bằng Ruby. Bạn có thể đọc thêm về dự án này trong phần đầu tiên của loạt bài này.
Việc xây dựng một trình phân tích cú pháp từ đầu đã mang lại cho tôi một số hiểu biết và kiến thức bất ngờ. Tôi đoán trải nghiệm này có thể khác nhau ở mỗi cá nhân, nhưng tôi nghĩ có thể an toàn khi cho rằng sau bài viết này, bạn sẽ thu thập hoặc hiểu sâu thêm kiến thức của mình về ít nhất một trong những điều sau:
- Bạn sẽ bắt đầu thấy mã nguồn khác đi và nhận thấy cấu trúc giống cây không thể phủ nhận của nó dễ dàng hơn nhiều;
- Bạn sẽ hiểu sâu hơn về đường cú pháp và sẽ bắt đầu thấy nó ở mọi nơi, có thể là bằng Stoffle, Ruby hoặc thậm chí là các ngôn ngữ lập trình khác.
Tôi cảm thấy rằng một trình phân tích cú pháp là một ví dụ hoàn hảo về nguyên tắc Pareto. Số lượng công việc cần thiết để tạo ra một số tính năng bổ sung, chẳng hạn như thông báo lỗi tuyệt vời, rõ ràng là lớn hơn và không tương xứng với nỗ lực cần thiết để thiết lập và chạy các tính năng cơ bản. Chúng tôi sẽ tập trung vào những yếu tố cần thiết và để những cải tiến như một thách thức đối với bạn, độc giả thân yêu của tôi. Chúng tôi có thể có hoặc không xử lý một số tính năng bổ sung thú vị hơn trong bài viết sau của loạt bài này.
Cú pháp đường
Đường cú pháp là một biểu thức được sử dụng để biểu thị các cấu trúc làm cho một ngôn ngữ dễ sử dụng hơn, nhưng việc loại bỏ chúng sẽ không làm cho ngôn ngữ lập trình mất chức năng. Một ví dụ hay là
elsifcủa Ruby xây dựng. Trong Stoffle, chúng tôi không có cấu trúc như vậy, vì vậy, để diễn đạt tương tự, chúng tôi buộc phải dài dòng hơn:if some_condition # ... else # oops, no elsif available if another_condition # ... end end
Trình phân tích cú pháp là gì?
Chúng tôi bắt đầu với mã nguồn, một chuỗi ký tự thô. Sau đó, như được hiển thị trong phần trước của loạt bài này, lexer nhóm các ký tự này thành các cấu trúc dữ liệu hợp lý được gọi là mã thông báo. Tuy nhiên, chúng ta vẫn còn lại với dữ liệu hoàn toàn phẳng, một cái gì đó vẫn chưa thể hiện một cách thích hợp bản chất lồng nhau của mã nguồn. Do đó, trình phân tích cú pháp có công việc tạo một cây từ chuỗi ký tự này. Khi nó hoàn thành nhiệm vụ của mình, chúng tôi sẽ kết thúc với dữ liệu cuối cùng có thể thể hiện cách mỗi phần trong chương trình của chúng tôi tổ chức và liên quan với nhau.
Cây được tạo bởi trình phân tích cú pháp nói chung được gọi là cây cú pháp trừu tượng (AST). Như tên của nó, chúng ta đang xử lý một cấu trúc dữ liệu dạng cây, với gốc của nó đại diện cho chính chương trình và phần tử con của nút chương trình này là nhiều biểu thức tạo nên chương trình của chúng ta. Từ trừu tượng trong AST đề cập đến khả năng của chúng tôi để trừu tượng hóa đi các phần mà trong các bước trước đó đã hiển thị rõ ràng. Một ví dụ điển hình là trình kết thúc biểu thức (dòng mới trong trường hợp của Stoffle); chúng được xem xét khi xây dựng AST, nhưng chúng tôi không cần một loại nút cụ thể để đại diện cho một đầu cuối. Tuy nhiên, hãy nhớ rằng chúng tôi đã có một mã thông báo rõ ràng đại diện cho một đầu mối.
Sẽ không hữu ích khi có một hình dung về AST mẫu phải không? Mong muốn của bạn là một đơn đặt hàng! Dưới đây là một chương trình Stoffle đơn giản, chúng tôi sẽ phân tích cú pháp từng bước sau trong bài đăng này và cây cú pháp trừu tượng tương ứng của nó:
fn double: num
num * 2
end
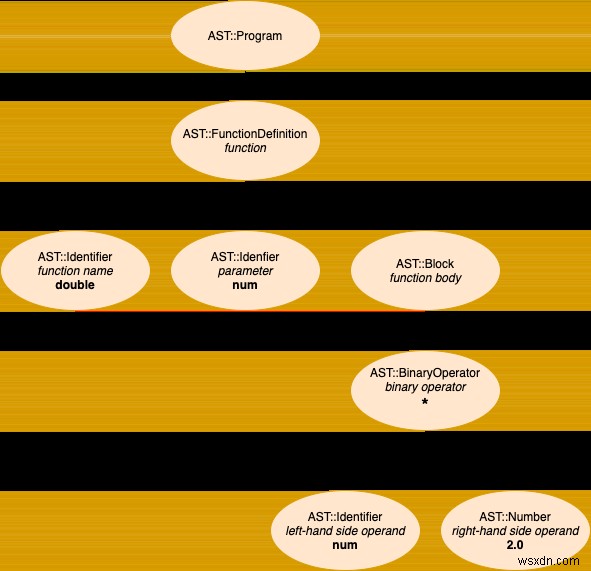
Từ Nguồn đến AST, Ví dụ đầu tiên
Trong phần này của bài đăng, chúng ta sẽ khám phá từng bước cách trình phân tích cú pháp của chúng ta xử lý rất chương trình Stoffle đơn giản, bao gồm một dòng đơn trong đó thể hiện ràng buộc biến (tức là chúng tôi gán giá trị cho một biến). Đây là nguồn, một bản trình bày đơn giản của các mã thông báo được tạo ra bởi lexer (các mã này là đầu vào được cung cấp cho trình phân tích cú pháp của chúng tôi) và cuối cùng, một bản trình bày trực quan về AST mà chúng tôi sẽ sản xuất để đại diện cho chương trình:
Nguồn
my_var = 1
Mã thông báo (Đầu ra của Lexer, Đầu vào cho Trình phân tích cú pháp)
[:identifier, :'=', :number]
Trình bày trực quan đầu ra của trình phân tích cú pháp (cây cú pháp trừu tượng)
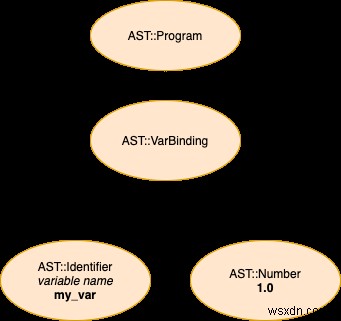
Như bạn có thể tưởng tượng, lõi của trình phân tích cú pháp của chúng tôi rất giống với lõi của lexer của chúng tôi. Trong trường hợp của lexer, chúng tôi có một loạt các ký tự để xử lý. Bây giờ, chúng ta vẫn phải lặp lại một bộ sưu tập, nhưng trong trường hợp của trình phân tích cú pháp, chúng ta sẽ xem qua danh sách các mã thông báo do người bạn lexer của chúng ta tạo ra. Chúng tôi có một con trỏ duy nhất (@next_p ) để theo dõi vị trí của chúng tôi trong việc thu thập mã thông báo. Con trỏ này đánh dấu tiếp theo mã thông báo sẽ được xử lý. Mặc dù chúng ta chỉ có một con trỏ duy nhất này, chúng ta có nhiều con trỏ "ảo" khác mà chúng ta có thể sử dụng khi cần thiết; chúng sẽ xuất hiện khi chúng tôi di chuyển trong quá trình triển khai. Một con trỏ "ảo" như vậy là current (về cơ bản, mã thông báo tại @next_p - 1 ).
#parse là phương thức gọi để chuyển đổi mã thông báo thành AST, sẽ có sẵn tại @ast biến cá thể. Việc triển khai #parse là đơn giản. Chúng tôi tiếp tục phát triển bộ sưu tập bằng cách gọi #consume và di chuyển @next_p cho đến khi không còn mã thông báo nào được xử lý (tức là trong khi next_p < tokens.length ). #parse_expr_recursively có thể trả về một nút AST hoặc không có gì cả; hãy nhớ rằng, chúng ta không cần phải đại diện cho các đầu cuối trong AST, chẳng hạn. Nếu một nút được tạo trong lần lặp hiện tại của vòng lặp, chúng tôi thêm nút đó vào @ast trước khi tiếp tục. Điều quan trọng cần ghi nhớ là #parse_expr_recursively cũng đang di chuyển @next_p vì, khi chúng tôi tìm thấy một mã thông báo đánh dấu sự bắt đầu của một cấu trúc cụ thể, chúng tôi phải tiến lên nhiều lần cho đến khi cuối cùng chúng tôi có thể xây dựng một nút đại diện đầy đủ cho những gì chúng tôi hiện đang phân tích cú pháp. Hãy tưởng tượng chúng ta sẽ phải tiêu thụ bao nhiêu mã thông báo để xây dựng một nút đại diện cho một if .
module Stoffle
class Parser
attr_accessor :tokens, :ast, :errors
# ...
def initialize(tokens)
@tokens = tokens
@ast = AST::Program.new
@next_p = 0
@errors = []
end
def parse
while pending_tokens?
consume
node = parse_expr_recursively
ast << node if node != nil
end
end
# ...
end
end
Trong đoạn mã ở trên, lần đầu tiên, chúng tôi được giới thiệu với một trong nhiều loại nút AST là một phần của việc triển khai trình phân tích cú pháp của chúng tôi. Dưới đây, chúng tôi có mã nguồn đầy đủ cho AST::Program loại nút. Như bạn có thể đoán, đây là gốc của cây của chúng ta, đại diện cho toàn bộ chương trình. Chúng ta hãy xem xét kỹ hơn những điều thú vị nhất của nó:
- Một chương trình Stoffle bao gồm
@expressions; đây là#childrencủa mộtAST::Programnút; - Như bạn sẽ thấy lại, mọi loại nút đều triển khai
#==phương pháp. Kết quả là, thật dễ dàng so sánh hai nút đơn giản, cũng như toàn bộ chương trình với nhau! Khi so sánh hai chương trình (hoặc hai nút phức hợp), sự bình đẳng của chúng sẽ được xác định bởi sự bình đẳng của mọi trẻ em, sự bình đẳng của mọi trẻ em của mọi trẻ em, v.v. Chiến lược đơn giản nhưng mạnh mẽ này được#==sử dụng cực kỳ hữu ích để kiểm tra việc triển khai của chúng tôi.
class Stoffle::AST::Program
attr_accessor :expressions
def initialize
@expressions = []
end
def <<(expr)
expressions << expr
end
def ==(other)
expressions == other&.expressions
end
def children
expressions
end
end
Biểu thức so với Câu lệnh
Trong một số ngôn ngữ, nhiều cấu trúc không tạo ra giá trị; một điều kiện là một ví dụ cổ điển. Đây được gọi là câu lệnh . Tuy nhiên, các cấu trúc khác đánh giá thành một giá trị (ví dụ:một lệnh gọi hàm). Đây được gọi là biểu thức . Tuy nhiên, trong các ngôn ngữ khác, mọi thứ đều là một biểu thức và tạo ra một giá trị. Ruby là một ví dụ về cách tiếp cận này. Ví dụ:hãy thử nhập đoạn mã sau vào IRB để tìm hiểu giá trị mà định nghĩa phương thức đánh giá:
irb(main):001:0> def two; 2; endNếu bạn không muốn kích hoạt IRB, hãy để tôi chia sẻ tin tức cho bạn; trong Ruby, một định nghĩa phương thức biểu thức đánh giá thành một ký hiệu (tên phương thức). Như bạn đã biết, Stoffle được truyền cảm hứng rất nhiều từ Ruby, vì vậy trong ngôn ngữ đồ chơi nhỏ của chúng tôi, mọi thứ cũng là một cách diễn đạt.
Hãy nhớ rằng những định nghĩa này đủ tốt cho các mục đích thực tế, nhưng không thực sự có sự đồng thuận và bạn có thể thấy tuyên bố và cách diễn đạt thuật ngữ được định nghĩa khác nhau ở những nơi khác.
Lặn sâu hơn:Bắt đầu triển khai #parse_expr_recursently
Như chúng ta vừa thấy trong đoạn mã ở trên, #parse_expr_recursively là phương pháp được gọi để có khả năng xây dựng một nút AST mới. #parse_expr_recursively sử dụng rất nhiều phương thức nhỏ hơn khác trong quá trình phân tích cú pháp, nhưng chúng ta có thể yên tâm nói rằng đó là động cơ thực sự của trình phân tích cú pháp của chúng ta. Mặc dù không dài lắm, nhưng phương pháp này khó tiêu hóa hơn. Do đó, chúng tôi sẽ cắt nó thành hai phần. Trong phần này của bài đăng, hãy bắt đầu với phân đoạn ban đầu của nó, phân đoạn này đã đủ mạnh để phân tích một số phần đơn giản hơn của ngôn ngữ lập trình Stoffle. Nhắc lại, hãy nhớ rằng chúng ta đang thực hiện các bước cần thiết để phân tích cú pháp một chương trình đơn giản bao gồm một biểu thức ràng buộc biến duy nhất:
Nguồn
my_var = 1
Mã thông báo (Đầu ra của Lexer, Đầu vào cho Trình phân tích cú pháp)
[:identifier, :'=', :number]
Sau khi xem xét các mã thông báo mà chúng ta phải xử lý và tưởng tượng đầu ra lexer sẽ là gì cho các biểu thức đơn giản tương tự khác, có vẻ như một ý tưởng hay là cố gắng kết hợp các loại mã thông báo với các phương pháp phân tích cú pháp cụ thể:
def parse_expr_recursively
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
send(parsing_function)
end
Trong lần triển khai đầu tiên này của #parse_expr_recursively , đó chính xác là những gì chúng tôi làm. Vì sẽ có khá nhiều của các loại mã thông báo khác nhau mà chúng tôi sẽ phải xử lý, tốt hơn nên trích xuất quy trình ra quyết định này sang một phương pháp riêng - #determine_parsing_function , mà chúng ta sẽ thấy trong giây lát.
Khi chúng tôi hoàn thành, sẽ không có bất kỳ mã thông báo nào mà chúng tôi không nhận ra, nhưng như một biện pháp bảo vệ, chúng tôi sẽ kiểm tra xem chức năng phân tích cú pháp có được liên kết với mã thông báo hiện tại hay không. Nếu không, chúng tôi sẽ thêm lỗi vào biến cá thể của chúng tôi @errors , chứa tất cả các vấn đề đã xảy ra trong quá trình phân tích cú pháp. Chúng tôi sẽ không trình bày chi tiết ở đây, nhưng bạn có thể kiểm tra việc triển khai đầy đủ trình phân tích cú pháp tại GitHub nếu bạn tò mò.
#determine_parsing_function trả về một ký hiệu đại diện cho tên của phương thức phân tích cú pháp sẽ được gọi. Chúng tôi sẽ sử dụng send của Ruby để gọi phương thức thích hợp một cách nhanh chóng.
Xác định phương pháp phân tích cú pháp và phân tích cú pháp một biến
Tiếp theo, hãy xem qua #determine_parsing_function để hiểu cơ chế ban đầu này để gọi các phương thức cụ thể để phân tích cú pháp các cấu trúc khác nhau của Stoffle. #determine_parsing_function sẽ được sử dụng cho mọi thứ (ví dụ:từ khóa và toán tử một ngôi) ngoại trừ toán tử nhị phân. Sau đó chúng ta sẽ tìm hiểu kỹ thuật được sử dụng trong trường hợp toán tử nhị phân. Bây giờ, hãy xem #determine_parsing_function :
def determine_parsing_function
if [:return, :identifier, :number, :string, :true, :false, :nil, :fn,
:if, :while].include?(current.type)
"parse_#{current.type}".to_sym
elsif current.type == :'('
:parse_grouped_expr
elsif [:"\n", :eof].include?(current.type)
:parse_terminator
elsif UNARY_OPERATORS.include?(current.type)
:parse_unary_operator
end
end
Như đã giải thích trước đây, #current là một ảo con trỏ đến mã thông báo đang được xử lý tại thời điểm này. Việc triển khai #determine_parsing_function rất thẳng thắn; chúng tôi xem xét mã thông báo hiện tại (cụ thể là loại của nó ) và trả về một ký hiệu đại diện cho phương thức thích hợp được gọi.
Hãy nhớ rằng chúng ta đang thực hiện các bước cần thiết để phân tích cú pháp một liên kết biến (my_var = 1 ), vì vậy các loại mã thông báo mà chúng tôi đang xử lý là [:identifier, :'=', :number] . Loại mã thông báo hiện tại là :identifier , vì vậy #determine_parsing_function sẽ trả về :parse_identifier , như bạn có thể đoán. Hãy xem bước tiếp theo của chúng ta, #parse_identifier phương pháp:
def parse_identifier
lookahead.type == :'=' ? parse_var_binding : AST::Identifier.new(current.lexeme)
end
Ở đây, chúng ta có một biểu hiện rất đơn giản, về cơ bản, tất cả các phương thức phân tích cú pháp khác làm. Trong #parse_identifier - và trong các phương pháp phân tích cú pháp khác - chúng tôi kiểm tra các mã thông báo để xác định xem cấu trúc chúng tôi đang mong đợi có thực sự hiện diện hay không. Chúng tôi biết chúng tôi có một số nhận dạng, nhưng chúng tôi phải xem mã thông báo tiếp theo để xác định xem chúng tôi có đang xử lý một ràng buộc biến hay không, điều này sẽ xảy ra nếu loại mã thông báo tiếp theo là :'=' hoặc nếu chúng ta chỉ có một số nhận dạng của chính nó hoặc tham gia vào một biểu thức phức tạp hơn. Ví dụ, hãy tưởng tượng một biểu thức số học trong đó chúng ta đang thao tác các giá trị được lưu trữ trong các biến.
Vì chúng ta có :'=' sắp tới, #parse_var_binding sẽ được gọi là:
def parse_var_binding
identifier = AST::Identifier.new(current.lexeme)
consume(2)
AST::VarBinding.new(identifier, parse_expr_recursively)
end
Ở đây, chúng tôi bắt đầu bằng cách tạo một nút AST mới để đại diện cho số nhận dạng mà chúng tôi hiện đang xử lý. Hàm tạo cho AST::Identifier yêu cầu lexeme của mã thông báo nhận dạng (tức là chuỗi ký tự, chuỗi "my_var" trong trường hợp của chúng tôi), vì vậy đó là những gì chúng tôi cung cấp cho nó. Sau đó, chúng tôi nâng cao hai vị trí trong dòng mã thông báo đang được xử lý, tạo mã thông báo có loại :number cái tiếp theo sẽ được phân tích. Hãy nhớ lại rằng chúng ta đang xử lý [:identifier, :'=', :number] .
Cuối cùng, chúng tôi xây dựng và trả về một nút AST đại diện cho ràng buộc biến. Hàm tạo cho AST::VarBinding mong đợi hai tham số:nút AST định danh (bên trái của biểu thức liên kết) và bất kỳ biểu thức hợp lệ nào (bên phải). Có một điều quan trọng cần lưu ý ở đây; để tạo ra phía bên phải của biểu thức ràng buộc biến, chúng tôi gọi #parse_expr_recursively một lần nữa . Điều này có thể hơi kỳ lạ lúc đầu, nhưng hãy nhớ rằng một biến có thể được liên kết với một biểu thức rất phức tạp, không chỉ với một số đơn thuần, như trường hợp trong ví dụ của chúng tôi. Nếu chúng ta xác định chiến lược phân tích cú pháp của mình trong một từ, nó sẽ là đệ quy . Bây giờ, tôi đoán bạn đang bắt đầu hiểu tại sao #parse_expr_recursively có tên mà nó có.
Trước khi kết thúc phần này, chúng ta nên nhanh chóng khám phá cả AST::Identifier và AST::VarBinding . Đầu tiên, AST::Identifier :
class Stoffle::AST::Identifier < Stoffle::AST::Expression
attr_accessor :name
def initialize(name)
@name = name
end
def ==(other)
name == other&.name
end
def children
[]
end
end
Không có gì lạ mắt ở đây. Điều đáng nói là nút lưu trữ tên của biến và không có con.
Bây giờ, AST::VarBinding :
class Stoffle::AST::VarBinding < Stoffle::AST::Expression
attr_accessor :left, :right
def initialize(left, right)
@left = left
@right = right
end
def ==(other)
children == other&.children
end
def children
[left, right]
end
end
Phía bên trái là AST::Identifier nút. Phía bên tay phải là hầu hết mọi loại nút có thể có - từ một số đơn giản, như trong ví dụ của chúng tôi, đến một số phức tạp hơn - đại diện cho biểu thức mà mã định danh bị ràng buộc. #children của một liên kết biến là các nút AST mà nó giữ trong @left và @right .
Từ Nguồn đến AST, Ví dụ thứ hai
Hiện tại của #parse_expr_recursively đã có thể phân tích cú pháp một số biểu thức đơn giản, như chúng ta đã thấy trong phần trước. Trong phần này, chúng ta sẽ hoàn thành việc triển khai nó để nó cũng có thể phân tích cú pháp các thực thể phức tạp hơn, chẳng hạn như toán tử nhị phân và logic. Ở đây, chúng ta sẽ khám phá từng bước cách trình phân tích cú pháp của chúng ta xử lý một chương trình xác định một hàm. Đây là nguồn, một bản trình bày đơn giản của các mã thông báo được tạo ra bởi lexer và, như chúng ta đã có trong phần đầu tiên, một bản trình bày trực quan về AST mà chúng tôi sẽ tạo ra để đại diện cho chương trình:
Nguồn
fn double: num
num * 2
end
Mã thông báo (Đầu ra của Lexer, Đầu vào cho Trình phân tích cú pháp)
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
Biểu diễn trực quan của đầu ra trình phân tích cú pháp (cây cú pháp trừu tượng)
Trước khi tiếp tục, chúng ta hãy lùi lại một bước và nói về các quy tắc ưu tiên toán tử. Chúng dựa trên các quy ước toán học; trong toán học, chúng chỉ là các quy ước, và thực sự, không có gì cơ bản dẫn đến việc ưu tiên toán tử mà chúng ta quen dùng. Những quy tắc này cũng cho phép chúng tôi xác định thứ tự chính xác để đánh giá một biểu thức và, trong trường hợp của chúng tôi, để phân tích cú pháp nó trước tiên. Để xác định mức độ ưu tiên của mỗi toán tử, chúng ta chỉ cần có một bản đồ (tức là Hash ) của các loại mã thông báo và số nguyên. Các số cao hơn có nghĩa là một toán tử phải được xử lý trước tiên :
# We define these precedence rules at the top of Stoffle::Parser.
module Stoffle
class Parser
# ...
UNARY_OPERATORS = [:'!', :'-'].freeze
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
LOWEST_PRECEDENCE = 0
PREFIX_PRECEDENCE = 7
OPERATOR_PRECEDENCE = {
or: 1,
and: 2,
'==': 3,
'!=': 3,
'>': 4,
'<': 4,
'>=': 4,
'<=': 4,
'+': 5,
'-': 5,
'*': 6,
'/': 6,
'(': 8
}.freeze
# ...
end
end
Kỹ thuật được sử dụng trong #parse_expr_recursively dựa trên thuật toán phân tích cú pháp nổi tiếng được trình bày bởi nhà khoa học máy tính Vaughan Pratt trong bài báo năm 1973 của ông, "Top Down Operator Precedence". Như bạn sẽ thấy, thuật toán rất đơn giản, nhưng hơi khó để nắm bắt đầy đủ. Người ta có thể nói rằng nó cảm thấy một chút kỳ diệu. Những gì chúng tôi sẽ làm trong bài đăng này để cố gắng hiểu trực quan về hoạt động của kỹ thuật này là đi từng bước một thông qua những gì sẽ xảy ra khi chúng tôi phân tích cú pháp đoạn mã Stoffle được đề cập ở trên. Vì vậy, không cần phải quảng cáo thêm, đây là phiên bản hoàn chỉnh của #parse_expr_recursively :
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that, here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
#parse_expr_recursively bây giờ chấp nhận một tham số, precedence . Nó đại diện cho "mức" ưu tiên được xem xét trong một lệnh gọi phương thức nhất định. Ngoài ra, phần đầu tiên của phương pháp này khá giống nhau. Sau đó - nếu chúng ta có thể xây dựng một biểu thức trong phần đầu tiên này - sẽ đến phần mới của phương pháp. Mặc dù mã thông báo tiếp theo không phải là dấu chấm hết (tức là ngắt dòng hoặc cuối tệp) và mức độ ưu tiên (precedence param) thấp hơn mức ưu tiên của mã thông báo tiếp theo, chúng tôi có khả năng tiếp tục sử dụng luồng mã thông báo.
Trước khi nhìn vào bên trong while , chúng ta hãy suy nghĩ một chút về ý nghĩa của điều kiện thứ hai của nó (precedence < nxt_precedence ). Nếu mức độ ưu tiên của mã thông báo tiếp theo cao hơn, biểu thức chúng tôi vừa tạo (expr biến cục bộ) có thể là con của một nút chưa được xây dựng (hãy nhớ rằng chúng tôi đang xây dựng AST, một cú pháp trừu tượng cây ). Trước khi đi qua phân tích cú pháp của đoạn mã Stoffle của chúng tôi, hãy suy nghĩ về việc phân tích cú pháp của một biểu thức số học đơn giản:2 + 2 . Khi phân tích cú pháp biểu thức này, phần đầu tiên của phương pháp của chúng tôi sẽ xây dựng một AST::Number nút đại diện cho 2 đầu tiên và lưu trữ nó trong expr . Sau đó, chúng ta sẽ bước vào while vì mức độ ưu tiên của mã thông báo tiếp theo (:'+' ) sẽ cao hơn mức ưu tiên mặc định. Sau đó, chúng tôi sẽ có phương thức phân tích cú pháp để xử lý một tổng được gọi, chuyển nó là AST::Number và nhận lại một nút đại diện cho toán tử nhị phân (AST::BinaryOperator ). Cuối cùng, chúng tôi sẽ ghi đè giá trị được lưu trữ trong expr , nút đại diện cho 2 đầu tiên trong 2 + 2 , với nút mới này đại diện cho toán tử cộng. Lưu ý rằng cuối cùng, thuật toán này đã cho phép chúng tôi sắp xếp lại các nút ; chúng tôi bắt đầu xây dựng AST::Number và kết thúc với việc nó là một nút sâu hơn trong cây của chúng ta, là một trong những nút con của AST::BinaryOperator nút.
Phân tích cú pháp Định nghĩa hàm theo từng bước
Bây giờ chúng ta đã xem qua phần giải thích tổng thể về #parse_expr_recursively , hãy quay lại định nghĩa hàm đơn giản của chúng ta:
fn double: num
num * 2
end
Ngay cả ý tưởng xem một mô tả đơn giản về quá trình thực thi trình phân tích cú pháp khi chúng tôi phân tích cú pháp đoạn mã này có thể cảm thấy mệt mỏi (và thực sự là có thể như vậy!), Nhưng tôi nghĩ nó rất có giá trị để hiểu rõ hơn về cả hai #parse_expr_recursively và phân tích cú pháp của các bit cụ thể (định nghĩa hàm và toán tử sản phẩm). Đầu tiên, đây là các loại mã thông báo mà chúng tôi sẽ xử lý (bên dưới là đầu ra cho @tokens.map(&:type) , bên trong trình phân tích cú pháp sau khi lexer hoàn tất mã hóa đoạn mã mà chúng ta vừa thấy):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
Bảng dưới đây cho thấy thứ tự mà các phương thức quan trọng nhất được gọi khi chúng tôi phân tích cú pháp các mã thông báo ở trên. Hãy nhớ rằng đây là một sự đơn giản hóa và nếu bạn muốn thực sự hiểu tất cả các bước chính xác của quá trình thực thi trình phân tích cú pháp, tôi khuyên bạn nên sử dụng trình gỡ lỗi Ruby, chẳng hạn như Byebug và nâng cao từng dòng khi chương trình thực thi.
Trình phân tích cú pháp của chúng tôi Dưới kính hiển vi
Có một bài kiểm tra sử dụng đoạn mã chính xác này mà chúng tôi đang khám phá, đoạn mã này có sẵn trong nguồn của Stoffle. Bạn có thể tìm thấy nó bên trong spec / lib / stffle / parser_spec.rb; đó là bài kiểm tra sử dụng đoạn mã có tên
complex_program_ok_2.sfe.Để khám phá từng bước thực thi trình phân tích cú pháp, bạn có thể chỉnh sửa nguồn và thêm lệnh gọi vào
byebugở đầuParser#parse, chỉ chạy thử nghiệm nói trên với RSpec, sau đó sử dụngstepcủa Byebug lệnh để nâng cấp chương trình từng dòng một.Xem thêm thông tin về cách hoạt động của Byebug và tất cả các lệnh có sẵn bằng cách truy cập tệp README của dự án tại GitHub.
| Phương thức được gọi là | Mã thông báo hiện tại | Mã thông báo tiếp theo | Các biến / kết quả cuộc gọi đáng chú ý | Ám ảnh |
|---|---|---|---|---|
| phân tích cú pháp | nil | :fn | ||
| parse_expr_recursently | :fn | :mã định danh | ưu tiên =0, phân tích cú pháp =:parse_fn | |
| parse_ functions_definition | :fn | :mã định danh | parse_fn là bí danh của parse_ functions_definition | |
| parse_ functions_params | :mã định danh | :":" | ||
| parse_block | :"\ n" | :mã định danh | ||
| parse_expr_recursently | :mã định danh | :* | ưu tiên =0, parsing_ Chức năng =:parse_identifier, nxt_precedence () trả về 6, infix_parsing_ Chức năng =:parse_binary_operator | |
| parse_identifier | :mã định danh | :* | ||
| parse_binary_operator | :* | :số | op_precedence =6 | |
| parse_expr_recursently | :số | :"\ n" | ưu tiên =6, parsing_ Chức năng =:parse_number, nxt_precedence () trả về 0 | |
| parse_number | :số | :"\ n" |
Bây giờ chúng ta đã có khái niệm chung về các phương thức nào được gọi, cũng như trình tự, hãy nghiên cứu một số phương pháp phân tích cú pháp mà chúng ta chưa thấy chi tiết hơn.
Phương pháp #parse_ function_definition
Phương thức #parse_function_definition được gọi khi mã thông báo hiện tại là :fn và cái tiếp theo là :identifier :
def parse_function_definition
return unless consume_if_nxt_is(build_token(:identifier))
fn = AST::FunctionDefinition.new(AST::Identifier.new(current.lexeme))
if nxt.type != :"\n" && nxt.type != :':'
unexpected_token_error
return
end
fn.params = parse_function_params if nxt.type == :':'
return unless consume_if_nxt_is(build_token(:"\n", "\n"))
fn.body = parse_block
fn
end
#consume_if_nxt_is - như bạn có thể đoán - nâng cao con trỏ của chúng tôi nếu mã thông báo tiếp theo thuộc loại nhất định. Nếu không, nó sẽ thêm lỗi vào @errors . #consume_if_nxt_is rất hữu ích - và được sử dụng trong nhiều phương pháp phân tích cú pháp - khi chúng ta muốn kiểm tra cấu trúc của mã thông báo để xác định xem chúng ta có cú pháp hợp lệ hay không. Sau khi làm điều đó, mã thông báo hiện tại thuộc loại :identifier (chúng tôi đang xử lý 'double' , tên của hàm) và chúng tôi xây dựng một AST::Identifier và chuyển nó cho hàm tạo để tạo nút đại diện cho định nghĩa hàm (AST::FunctionDefinition ). Chúng tôi sẽ không xem nó chi tiết ở đây, nhưng về cơ bản, một AST::FunctionDefinition nút mong đợi tên hàm, có thể là một mảng tham số và thân hàm.
Bước tiếp theo trong #parse_function_definition là xác minh xem mã thông báo tiếp theo sau mã định danh là dấu chấm dứt biểu thức (tức là hàm không có tham số) hay dấu hai chấm (tức là hàm có một hoặc nhiều tham số). Nếu chúng ta có các tham số, như trường hợp của double chức năng chúng tôi đang xác định, chúng tôi gọi là #parse_function_params để phân tích cú pháp chúng. Chúng tôi sẽ kiểm tra phương pháp này trong giây lát, nhưng trước tiên hãy tiếp tục và kết thúc quá trình khám phá #parse_function_definition .
Bước cuối cùng là thực hiện một kiểm tra cú pháp khác để xác minh rằng có một dấu chấm cuối sau tên hàm + tham số và sau đó, tiến hành phân tích cú pháp nội dung hàm bằng cách gọi #parse_block . Cuối cùng, chúng tôi trả về fn , chứa AST::FunctionDefinition được xây dựng đầy đủ của chúng tôi ví dụ, hoàn chỉnh với tên hàm, tham số và nội dung.
Nuts và Bolts of Function Parameters Parsing
Trong phần trước, chúng ta đã thấy rằng #parse_function_params được gọi bên trong #parse_function_definition . Nếu chúng ta quay lại bảng tóm tắt luồng thực thi và trạng thái của trình phân tích cú pháp, chúng ta có thể thấy rằng khi #parse_function_params bắt đầu chạy, mã thông báo hiện tại thuộc loại :identifier và tiếp theo là :":" (tức là chúng ta vừa hoàn thành phân tích cú pháp tên hàm). Với tất cả những điều này, hãy xem thêm một số mã:
def parse_function_params
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers = []
identifiers << AST::Identifier.new(current.lexeme)
while nxt.type == :','
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers << AST::Identifier.new(current.lexeme)
end
identifiers
end
Trước khi tôi giải thích từng phần của phương pháp này, hãy tóm tắt lại các mã thông báo mà chúng tôi phải xử lý và vị trí của chúng tôi trong công việc này:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# here ▲
Phần đầu tiên của #parse_function_params là đơn giản. Nếu chúng ta có cú pháp hợp lệ (ít nhất một mã định danh sau : ), chúng tôi kết thúc việc di chuyển con trỏ của mình theo hai vị trí:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
Bây giờ, chúng ta đang ngồi ở tham số đầu tiên được phân tích cú pháp (mã thông báo thuộc loại :identifier ). Như mong đợi, chúng tôi tạo một AST::Identifier và đẩy nó vào một mảng, có khả năng, nhiều tham số khác chưa được phân tích cú pháp. Trong phần tiếp theo của #parse_function_params , chúng tôi tiếp tục phân tích cú pháp các tham số miễn là có các dấu phân tách tham số (tức là các mã thông báo loại :',' ). Chúng tôi kết thúc phương pháp bằng cách trả về các số nhận dạng var identifiers , một mảng có khả năng có nhiều AST::Identifier các nút, mỗi nút đại diện cho một tham số. Tuy nhiên, trong trường hợp của chúng ta, mảng này chỉ có một phần tử.
Còn về Nội dung Hàm thì sao?
Bây giờ chúng ta hãy đi sâu vào phần cuối cùng của việc phân tích một định nghĩa hàm:xử lý phần thân của nó. Khi #parse_block được gọi, chúng ta đang ngồi ở dấu chấm cuối đánh dấu phần cuối của danh sách các tham số hàm:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, here's the implementation of #parse_block :
def parse_block
consume
block = AST::Block.new
while current.type != :end && current.type != :eof && nxt.type != :else
expr = parse_expr_recursively
block << expr unless expr.nil?
consume
end
unexpected_token_error(build_token(:eof)) if current.type == :eof
block
end
AST::Block is the AST node for representing, well, a block of code. In other words, AST::Block just holds a list of expressions, in a very similar fashion as the root node of our program, an AST::Program node (as we saw at the beginning of this post). To parse the block (i.e., the function body), we continue advancing through unprocessed tokens until we encounter a token that marks the end of the block.
To parse the expressions that compose the block, we use our already-known #parse_expr_recursively . We will step into this method call in just a moment; this is the point in which we will start parsing the product operation happening inside our double hàm số. Following this closely will allow us to understand the use of precedence values inside #parse_expr_recursively and how an infix operator (the * in our case) gets dealt with. Before we do that, however, let's finish our exploration of #parse_block .
Before returning an AST node representing our block, we check whether the current token is of type :eof . If this is the case, we have a syntax error since Stoffle requires a block to end with the end keyword. To wrap up the explanation of #parse_block , I should mention something you have probably noticed; one of the conditions of our loop verifies whether the next token is of type :else . This happens because #parse_block is shared by other parsing methods, including the methods responsible for parsing conditionals and loops. Pretty neat, huh?!
Parsing Infix Operators
The name may sound a bit fancy, but infix operators are, basically, those we are very used to seeing in arithmetic, plus some others that we may be more familiar with by being software developers:
module Stoffle
class Parser
# ...
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
# ...
end
end
They are expected to be used infixed when the infix notation is used, as is the case with Stoffle, which means they should appear in the middle of their two operands (e.g., as * appears in num * 2 in our double function). Something worth mentioning is that although the infix notation is pretty popular, there are other ways of positioning operators in relation to their operands. If you are curious, research a little bit about "Polish notation" and "reverse Polish notation" methods.
To finish parsing our double function, we have to deal with the * operator:
fn double: num
num * 2
end
In the previous section, we mentioned that parsing the expression that composes the body of double starts when #parse_expr_recursively is called within #parse_block . When that happens, here's our position in @tokens :
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, to refresh our memory, here's the code for #parse_expr_recursively again:
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
In the first part of the method, we will use the same #parse_identifier method we used to parse the num variable. Then, for the first time, the conditions of the while loop will evaluate to true; the next token is not a terminator, and the precedence of the next token is greater than the precedence of this current execution of parse_expr_recursively (precedence is the default, 0, while nxt_precedence returns 6 since the next token is of type :'*' ). This indicates that the node we already built (an AST::Identifier representing num ) will probably be deeper in our AST (i.e., it will be the child of a node yet to be built). We enter the loop and call #determine_infix_function , passing to it the next token (the * ):
def determine_infix_function(token = current)
if (BINARY_OPERATORS + LOGICAL_OPERATORS).include?(token.type)
:parse_binary_operator
elsif token.type == :'('
:parse_function_call
end
end
Since * is a binary operator, running #determine_infix_function will result in :parse_binary_operator . Back in #parse_expr_recursively , we will advance our tokens pointer by one position and then call #parse_binary_operator , passing along the value of expr (the AST::Identifier representing num ):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
#▲
def parse_binary_operator(left)
op = AST::BinaryOperator.new(current.type, left)
op_precedence = current_precedence
consume
op.right = parse_expr_recursively(op_precedence)
op
end
class Stoffle::AST::BinaryOperator < Stoffle::AST::Expression
attr_accessor :operator, :left, :right
def initialize(operator, left = nil, right = nil)
@operator = operator
@left = left
@right = right
end
def ==(other)
operator == other&.operator && children == other&.children
end
def children
[left, right]
end
end
At #parse_binary_operator , we create an AST::BinaryOperator (its implementation is shown above if you are curious) to represent * , setting its left operand to the identifier (num ) we received from #parse_expr_recursively . Then, we save the precedence value of * at the local var op_precedence and advance our token pointer. To finish building our node representing * , we call #parse_expr_recursively again! We need to proceed in this fashion because the right-hand side of our operator will not always be a single number or identifier; it can be a more complex expression, such as something like num * (2 + 2) .
One thing of utmost importance that happens here at #parse_binary_operator is the way in which we call #parse_expr_recursively back again. We call it passing 6 as a precedence value (the precedence of * , stored at op_precedence ). Here we observe an important aspect of our parsing algorithm, which was mentioned previously. By passing a relatively high precedence value, it seems like * is pulling the next token as its operand. Imagine we were parsing an expression like num * 2 + 1; in this case, the precedence value of * passed in to this next call to #parse_expr_recursively would guarantee that the 2 would end up being the right-hand side of * and not an operand of + , which has a lower precedence value of 5 .
After #parse_expr_recursively returns an AST::Number node, we set it as the right-hand size of * and, finally, return our complete AST::BinaryOperator node. At this point, we have, basically, finished parsing our Stoffle program. We still have to parse some terminator tokens, but this is straightforward and not very interesting. At the end, we will have an AST::Program instance at @ast with expressions that could be visually represented as the tree we saw at the beginning of this post and in the introduction to the second section of the post:
Kết thúc
In this post, we covered the principal aspects of Stoffle's parser. If you understand the bits we explored here, you shouldn't have much trouble understanding other parser methods we were not able to cover, such as parsing conditionals and loops. I encourage you to explore the source code of the parser by yourself and tweak the implementation if you are feeling more adventurous! The implementation is accompanied by a comprehensive test suite, so don't be afraid to try things out and mess up with the parser.
In subsequent posts in this series, we will finally breathe life into our little monster by implementing the last bit we are missing:the tree-walk interpreter. I can't wait to be there with you as we run our first Stoffle program!