Trong phần này, chúng tôi sẽ sử dụng PyTorch để đào tạo CNN nhận dạng bộ phân loại chữ số viết tay bằng cách sử dụng tập dữ liệu MNIST.
MNIST là bộ dữ liệu được sử dụng rộng rãi cho nhiệm vụ phân loại viết tay bao gồm hơn 70k hình ảnh thang độ xám 28 * 28 pixel được gắn nhãn của các chữ số viết tay. Tập dữ liệu chứa gần 60 nghìn hình ảnh đào tạo và 10 nghìn hình ảnh thử nghiệm. Công việc của chúng tôi là đào tạo một mô hình bằng cách sử dụng 60k hình ảnh huấn luyện và sau đó kiểm tra độ chính xác phân loại của nó trên 10k hình ảnh thử nghiệm.
Cài đặt
Trước tiên, chúng tôi cần phiên bản mới nhất của MXNet, chỉ cần chạy phần sau trên thiết bị đầu cuối của bạn:
$ pip cài đặt mxnet
Và bạn sẽ như thế nào,
Đang thu thập mxnetTải xuống https://files.pythonhosted.org/packages/60/6f/071f9ef51467f9f6cd35d1ad87156a29314033bbf78ad862a338b9eaf2e6/mxnet-1.2.0-py2.py3-none-win████ (12,8MB) 100% | ██████████████████████████████ | 12,8MB 131kB / s Yêu cầu đã được đáp ứng:numpy trong c:\ python \ python361 \ lib \ site-pack (từ mxnet) (1.16.0) Đang thu thập graphviz (từ mxnet) Đang tải xuống https://files.pythonhosted.org/packages/ 1f / e2 / ef2581b5b86625657afd32030f90cf2717456c1d2b711ba074bf007c0f1a / graphviz-0.10.1-py2.py3-none-any.whl….… .Cài đặt các gói đã thu thập:graphviz, mxnet Đã cài đặt thành công graphviz-0.10.1.Thứ hai, chúng tôi cần thư viện torch &torchvision- nếu đó không phải là nơi bạn có thể cài đặt nó bằng pip.
Nhập Thư viện
nhập torchvision torchimportTải tập dữ liệu MNIST
Trước khi bắt đầu làm việc với chương trình của mình, chúng ta cần tập dữ liệu MNIST. Vì vậy, hãy tải hình ảnh và nhãn vào bộ nhớ và xác định các siêu tham số mà chúng tôi sẽ sử dụng cho thử nghiệm này.
#n_epochs là số lần, chúng tôi sẽ lặp lại toàn bộ dữ liệu đào tạon_epochs =3batch_size_train =64batch_size_test =1000 # Learning_rate và động lượng dành cho opimizerlearning_rate =0.01momentum =0.5log_interval =10random_seed =1torch.backendsena =Falsetorch.manual_seed (random_seed)Bây giờ chúng ta sẽ tải tập dữ liệu MNIST bằng TorchVision. Chúng tôi đang sử dụng batch_size 64 để đào tạo và size 1000 để thử nghiệm trên tập dữ liệu này. Để chuẩn hóa, chúng tôi sẽ sử dụng giá trị trung bình là 0,1307 và độ lệch chuẩn là 0,3081 của tập dữ liệu MNIST.
train_loader =torch.utils.data.DataLoader (torchvision.datasets.MNIST ('/ files /', train =True, download =True, convert =torchvision.transforms.Compose ([torchvision.transforms.ToTensor (), torchvision.transforms.Normalize ((0.1307,), (0.3081,))])), batch_size =batch_size_train, shuffle =True) test_loader =torch.utils.data.DataLoader (torchvision.datasets.MNIST ('/ files /', train =False, tải xuống =True, biến đổi =torchvision.transforms.Compose ([torchvision.transforms.ToTensor (), torchvision.transforms.Normalize ((0,1307,), (0,3081,))])), batch_size =batch_size_test, shuffle =Đúng)Đầu ra
Tải xuống http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gzTải xuống http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gzDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gzTải xuống http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gzProcessing...Done !Sử dụng test_loader để tải dữ liệu thử nghiệm
amples =enumerate (test_loader) batch_idx, (example_data, example_targets) =next (ví dụ) example_data.shapeĐầu ra
torch.Size ([1000, 1, 28, 28])Vì vậy, từ đầu ra, chúng ta có thể thấy chúng ta có một lô dữ liệu thử nghiệm là một tensor hình dạng:[1000, 1, 28, 28] có nghĩa là- 1000 ví dụ về 28 * 28 pixel trong thang độ xám.
Hãy vẽ một số tập dữ liệu bằng cách sử dụng matplotlib.
nhập matplotlib.pyplot dưới dạng pltfig =plt.figure () cho tôi trong phạm vi (5):plt.subplot (2,3, i + 1) plt.tight_layout () plt.imshow (example_data [i] [0 ], cmap ='gray', interpolation ='none') plt.title ("Sự thật cơ bản:{}". format (example_targets [i])) plt.xticks ([]) plt.yticks ([]) print ( hình)Đầu ra

Xây dựng mạng
Bây giờ chúng ta sẽ xây dựng mạng của mình bằng cách sử dụng các lớp tích chập 2-D, tiếp theo là hai lớp được kết nối đầy đủ. Chúng tôi sẽ tạo một lớp mới cho mạng mà chúng tôi muốn xây dựng nhưng trước đó, hãy nhập một số mô-đun.
nhập torch.nn dưới dạng nnimport torch.nn.có chức năng như Fimport torch.optim dưới dạng lớp tối ưu Net (nn.Module):def __init __ (self):super (Net, self) .__ init __ () self.conv1 =nn. Conv2d (1, 10, kernel_size =5) self.conv2 =nn.Conv2d (10, 20, kernel_size =5) self.conv2_drop =nn.Dropout2d () self.fc1 =nn.Linear (320, 50) self.fc2 =nn.Linear (50, 10) định nghĩa về phía trước (self, x):x =F.relu (F.max_pool2d (self.conv1 (x), 2)) x =F.relu (F.max_pool2d (self.conv2_drop (self.conv2 (x)), 2)) x =x.view (-1, 320) x =F.relu (self.fc1 (x)) x =F.dropout (x, training =self.training) x =self.fc2 (x) trả về F.log_softmax (x)Khởi tạo mạng và trình tối ưu hóa:
network =Net () Optimizer =Optim.SGD (network.parameters (), lr =learning_rate, Moment =Momentum)Đào tạo người mẫu
Hãy xây dựng mô hình đào tạo của chúng tôi. Vì vậy, trước tiên hãy kiểm tra mạng của chúng tôi đang ở chế độ mạng và sau đó tương tác dữ liệu đào tạo tổng thể một lần cho mỗi kỷ nguyên. Dataloader sẽ tải các lô riêng lẻ. Chúng tôi đặt các gradient thành 0 bằng cách sử dụng Optimizer.zero_grad ()
train_losses =[] train_counter =[] test_losses =[] test_counter =[i * len (train_loader.dataset) cho tôi trong phạm vi (n_epochs + 1)]Để tạo ra một đường cong đào tạo đẹp, chúng tôi tạo hai danh sách để tiết kiệm tổn thất đào tạo và kiểm tra. Trên trục x, chúng tôi muốn hiển thị số lượng ví dụ đào tạo.
Lệnh gọi back () giờ đây chúng tôi thu thập một tập hợp các gradient mới mà chúng tôi truyền ngược lại vào từng thông số của mạng bằng cách sử dụng Optimizer.step ().
def train (epoch):network.train () cho batch_idx, (data, target) in enumerate (train_loader):Optimizer.zero_grad () output =network (data) loss =F.nll_loss (output, target) loss .backward () Optimizer.step () if batch_idx% log_interval ==0:print ('Train Epoch:{} [{} / {} ({:.0f}%)] \ tLoss:{:.6f}'. format (epoch, batch_idx * len (data), len (train_loader.dataset), 100. * batch_idx / len (train_loader), loss.item ())) train_losses.append (loss.item ()) train_counter.append (( batch_idx * 64) + ((epoch-1) * len (train_loader.dataset))) torch.save (network.state_dict (), '/results/model.pth') torch.save (Optimizer.state_dict (), ' /results/optimizer.pth ')Các mô-đun mạng trung lập, cũng như các trình tối ưu hóa, có khả năng lưu và tải trạng thái bên trong của chúng bằng cách sử dụng .state_dict ().
Bây giờ đối với vòng lặp kiểm tra của chúng tôi, chúng tôi tổng hợp tổn thất kiểm tra và theo dõi các chữ số được phân loại chính xác để tính độ chính xác của mạng.
def test ():network.eval () test_loss =0 correct =0 with torch.no_grad ():cho dữ liệu, target trong test_loader:output =network (data) test_loss + =F.nll_loss (output, target, size_average =False) .item () pred =output.data.max (1, keepdim =True) [1] true + =pred.eq (target.data.view_as (pred)). sum () test_loss / =len ( test_loader.dataset) test_losses.append (test_loss) print ('\ nTập hợp thử nghiệm:Mất trung bình:{:.4f}, Độ chính xác:{} / {} ({:.0f}%) \ n'.format (test_loss, đúng, len (test_loader.dataset), 100. * đúng / len (test_loader.dataset)))Để chạy chương trình đào tạo, chúng tôi thêm một lệnh gọi test () trước khi lặp qua n_epochs để đánh giá mô hình của chúng tôi với các tham số được khởi tạo ngẫu nhiên.
test () for epoch in range (1, n_epochs + 1):train (epoch) test ()Đầu ra
Bộ thử nghiệm:Trung bình mất:2.3048, Độ chính xác:1063/10000 (10%) Kỷ nguyên tàu:1 [0/60000 (0%)] Mất:2.294911 Kỷ nguyên tàu:1 [640/60000 (1%)] Mất:2.314225 Kỷ nguyên tàu:1 [ 1280/60000 (2%)] Mất:2.290719 Kỷ nguyên truyền:1 [1920/60000 (3%)] Mất:2.294191 Kỷ nguyên truyền:1 [2560/60000 (4%)] Mất:2.246799 Kỷ nguyên truyền:1 [3200 / 60000 (5%)] Mất:2,292224 Kỷ nguyên truyền:1 [3840/60000 (6%)] Mất:2.216632 Kỷ nguyên truyền:1 [4480/60000 (7%)] Mất:2.259646 Kỷ nguyên truyền:1 [5120/60000 ( 9%)] Tổn thất:2,244781 Kỷ nguyên tốc độ:1 [5760/60000 (10%)] Tổn thất:2.245569 Kỷ nguyên tốc độ:1 [6400/60000 (11%)] Tổn thất:2.203358 Kỷ nguyên tốc độ:1 [7040/60000 (12%) )] Tổn thất:2.192290 Kỷ nguyên tốc độ:1 [7680/60000 (13%)] Tổn thất:2.040502 Kỷ nguyên tốc độ:1 [8320/60000 (14%)] Tổn thất:2.102528 Kỷ nguyên tốc độ:1 [8960/60000 (15%)] Loss:1.944297Train Epoch:1 [9600/60000 (16%)] Loss:1.886444Train Epoch:1 [10240/60000 (17%)] Loss:1.801920Train Epoch:1 [10880/60000 (18%)] Loss:1.421267Train Epoch:1 [11520/60000 (19%)] Loss:1.491448Train Epoch:1 [12160/60000 (20%)] Loss:1.600088Train Epoch:1 [12800/60000 ( 21%)] Hao hụt:1.218677Train Epoch:1 [13440/60000 (22%)] Loss:1.060651Train Epoch:1 [14080/60000 (23%)] Loss:1.161512Train Epoch:1 [14720/60000 (25%) )] Hao hụt:1.351181Train Epoch:1 [15360/60000 (26%)] Loss:1.012257Train Epoch:1 [16000/60000 (27%)] Loss:1.018847Train Epoch:1 [16640/60000 (28%)] Tổn thất:0,944324 Kỷ nguyên tốc độ:1 [17280/60000 (29%)] Tổn thất:0,929246 Kỷ nguyên tốc độ:1 [17920/60000 (30%)] Tổn thất:0,903336 Kỷ nguyên tốc độ:1 [18560/60000 (31%)] Tổn thất:1.243159Train Epoch:1 [19200/60000 (32%)] Loss:0,696106Train Epoch:1 [19840/60000 (33%)] Loss:0,902251Train Epoch:1 [20480/60000 (34%)] Loss:0,986816Train Epoch:1 [21120/60000 (35%)] Loss:1.203934Train Epoch:1 [21760/60000 (36%)] Loss:0,682855Train Epoch:1 [22400/60000 (37%)] Loss:0,653592Train Epoch:1 [23040/60000 (38%)] Hao hụt:0.932158Train Epoch:1 [23680/60000 (39%)] Loss:1.110188Train Epoch:1 [24320/60000 (41%)] Loss:0.817414Train Epoch:1 [ 24960/60000 (42%)] Mất:0,584215 Kỷ nguyên kéo:1 [25600/60000 (43%)] Mất:0,724121 Kỷ nguyên truyền:1 [26240 / 60000 (44%)] Mất:0,707071 Kỷ nguyên truyền:1 [26880/60000 (45%)] Mất:0,574117 Kỷ nguyên truyền:1 [27520/60000 (46%)] Mất:0,652862 Kỷ nguyên truyền:1 [28160/60000 (47%)] Mất:0,654354 Kỷ nguyên truyền:1 [28800/60000 (48%)] Mất:0,811647 Kỷ nguyên truyền:1 [29440/60000 (49%)] Mất:0,536885 Kỷ nguyên truyền:1 [30080/60000 (50 %)] Mất:0,849961 Kỷ nguyên tốc độ:1 [30720/60000 (51%)] Tổn thất:0,844555 Kỷ nguyên tốc độ:1 [31360/60000 (52%)] Tổn thất:0,687859 Kỷ nguyên tốc độ:1 [32000/60000 (53%) ] Mất:0,766818 Kỷ nguyên tốc độ:1 [32640/60000 (54%)] Tổn thất:0,597061 Kỷ nguyên tốc độ:1 [33280/60000 (55%)] Tổn thất:0,691049 Kỷ nguyên tốc độ:1 [33920/60000 (57%)] Tổn thất :0.573049Train Epoch:1 [34560/60000 (58%)] Loss:0.405698Train Epoch:1 [35200/60000 (59%)] Loss:0.480660Train Epoch:1 [35840/60000 (60%)] Loss:0.582871 Kỷ nguyên tàu:1 [36480/60000 (61%)] Tổn thất:0.496494 ………………. Kỷ nguyên tàu:3 [49920/60000 (83%)] Tổn thất:0,253500 Kỷ nguyên tàu:3 [50560/60000 (84%) )] Mất:0,364354 Kỷ nguyên tốc độ:3 [51200/60000 (85%)] Tổn thất:0,333843 Kỷ nguyên tốc độ:3 [51840/60000 (86%)] Tổn thất:0,096922Train Epoch:3 [52480/60000 (87%)] Loss:0,282102Train Epoch:3 [53120/60000 (88%)] Loss:0,236428Train Epoch:3 [53760/60000 (90%)] Loss:0.610584Train Epoch:3 [54400/60000 (91%)] Mất:0,198840 Kỷ nguyên truyền:3 [55040/60000 (92%)] Mất:0,344225 Kỷ nguyên truyền:3 [55680/60000 (93%)] Mất:0,158644 Kỷ nguyên truyền:3 [ 56320/60000 (94%)] Mất:0,216912 Kỷ nguyên truyền:3 [56960/60000 (95%)] Mất:0,309554 Kỷ nguyên truyền:3 [57600/60000 (96%)] Mất:0,243239 Kỷ nguyên truyền:3 [58240 / 60000 (97%)] Hao hụt:0.176541Train Epoch:3 [58880/60000 (98%)] Loss:0.456749Train Epoch:3 [59520/60000 (99%)] Loss:0.318569Bộ thử nghiệm:Trung bình. mất mát:0,0912, Độ chính xác:9716/10000 (97%)Đánh giá Hiệu suất của Mô hình
Vì vậy, chỉ với 3 kỷ nguyên đào tạo, chúng tôi đã đạt được độ chính xác 97% trong bài kiểm tra. Với các tham số được khởi tạo ngẫu nhiên, chúng tôi bắt đầu với độ chính xác 10% trên bộ thử nghiệm ban đầu, trước khi bắt đầu đào tạo.
Hãy vẽ đường cong đào tạo của chúng tôi:
fig =plt.figure () plt.plot (train_counter, train_losses, color ='blue') plt.scatter (test_counter, test_losses, color ='red') plt.legend (['Train Loss', 'Test Loss '], loc =' upper right ') plt.xlabel (' số lượng ví dụ đào tạo đã thấy ') plt.ylabel (' khả năng mất bản ghi âm ') FigĐầu ra
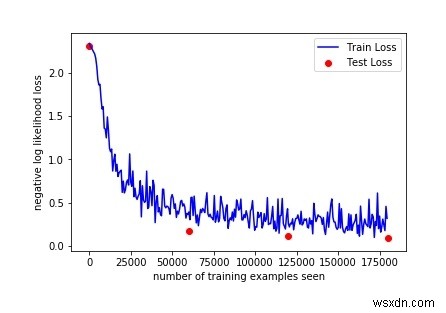
Bằng cách kiểm tra đầu ra ở trên, chúng tôi có thể tăng số lượng kỷ nguyên để xem thêm một số kết quả, Vì độ chính xác được tăng lên bằng cách kiểm tra 3 thời kỳ.
Nhưng trước đó, hãy chạy thêm một số ví dụ và so sánh đầu ra của mô hình:
với torch.no_grad ():output =network (example_data) fig =plt.figure () cho tôi trong phạm vi (6):plt.subplot (2,3, i + 1) plt.tight_layout () plt. imshow (example_data [i] [0], cmap ='gray', interpolation ='none') plt.title ("Dự đoán:{}". format (output.data.max (1, keepdim =True) [1] [i] .item ())) plt.xticks ([]) plt.yticks ([]) Fig

Như chúng ta có thể thấy các dự đoán về mô hình của mình, có vẻ giống với những ví dụ đó.