Để sử dụng Matplotlib để vẽ biểu đồ PySpark SQL kết quả , chúng ta có thể thực hiện các bước sau đây−
- Đặt kích thước hình và điều chỉnh phần đệm giữa và xung quanh các ô phụ.
- Lấy ví dụ là Điểm truy cập chính cho chức năng Spark.
- Lấy ví dụ về một biến thể của Spark SQL tích hợp với dữ liệu được lưu trữ trong Hive.
- Tạo danh sách các bản ghi dưới dạng một bộ.
- Phân phối một bộ sưu tập Python cục bộ để tạo thành một RDD.
- Ánh xạ bản ghi danh sách dưới dạng lược đồ DB.
- Nhận phiên bản giản đồ để tạo mục nhập vào "my_table".
- Chèn bản ghi vào bảng.
- Đọc truy vấn SQL, truy xuất bản ghi.
- Chuyển đổi bản ghi đã tìm nạp thành khung dữ liệu.
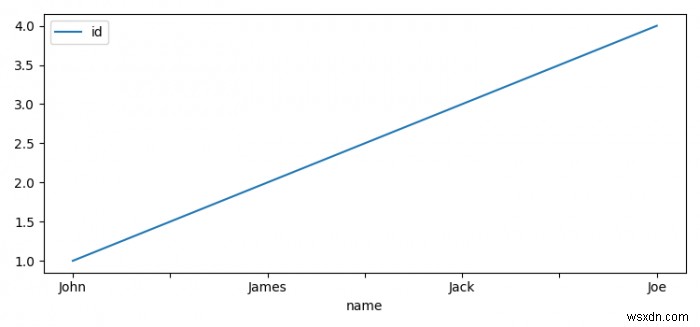
- Đặt chỉ mục bằng tên thuộc tính và vẽ biểu đồ của chúng.
- Để hiển thị hình này, hãy sử dụng show () phương pháp.
Ví dụ
from pyspark.sql import Row
from pyspark.sql import HiveContext
import pyspark
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [7.50, 3.50]
plt.rcParams["figure.autolayout"] = True
sc = pyspark.SparkContext()
sqlContext = HiveContext(sc)
test_list = [(1, 'John'), (2, 'James'), (3, 'Jack'), (4, 'Joe')]
rdd = sc.parallelize(test_list)
people = rdd.map(lambda x: Row(id=int(x[0]), name=x[1]))
schemaPeople = sqlContext.createDataFrame(people)
sqlContext.registerDataFrameAsTable(schemaPeople, "my_table")
df = sqlContext.sql("Select * from my_table")
df = df.toPandas()
df.set_index('name').plot()
plt.show() Đầu ra