Các tác vụ nền là một trong những trụ cột cốt lõi khi xem xét quy mô ứng dụng web. Ý tưởng cơ bản rất đơn giản:Một khách hàng đưa ra yêu cầu tới ứng dụng web của bạn và khi xử lý yêu cầu đó, ứng dụng của bạn sẽ thực hiện một số nhiệm vụ tốn nhiều thời gian. Để cho phép ứng dụng phản hồi máy khách nhanh hơn, ứng dụng sẽ xếp một công việc nền vào hệ thống xử lý nền. Sau đó, quá trình xử lý nền sẽ được giao nhiệm vụ thực hiện tất cả các công việc nặng nhọc, như tính toán hoặc thao tác I/O. Dựa vào các tác vụ nền một cách hiệu quả là một trong những nền tảng quan trọng nhất khi mở rộng ứng dụng web của bạn.
Là nhà phát triển Rails, chúng tôi may mắn có được một số thư viện tuyệt vời để lựa chọn, tất cả đều có những ưu điểm, nhược điểm khác nhau và thậm chí cả cơ sở dữ liệu phụ trợ. Những thư viện này giúp bạn dễ dàng giảm tải mọi công việc nặng nhọc, cho phép ứng dụng của chúng tôi phản hồi nhanh hơn và phục vụ nhiều người dùng hơn với ít tài nguyên hơn.
Cho đến gần đây, chúng tôi đã sử dụng Sidekiq để thực hiện phần lớn công việc xử lý nền của Honeybadger. Nó là công cụ giúp chúng tôi duy trì trải nghiệm người dùng cực nhanh và một quy trình mạnh mẽ để xử lý lượng dữ liệu khổng lồ mà chúng tôi thu thập.
Sidekiq kém chúng ta ở điểm nào?
Mặc dù có độ tin cậy cao nhưng Redis vẫn có một số hạn chế. Cho đến gần đây, chúng tôi đã sử dụng Sidekiq để xử lý tất cả công việc của mình, bao gồm cả việc xử lý quá trình nhập cho các điểm cuối theo dõi lỗi của chúng tôi. Lưu lượng lỗi rất khác nhau. Chúng tôi thường tăng gấp 10 hoặc 20 lần số lượng công việc trong hàng đợi của mình—dẫn đến lượng công việc tồn đọng lớn cho đến khi quy mô tự động của chúng tôi có thể tuyển đủ nhân công để bắt kịp. Nhưng vấn đề lớn hơn là tình trạng cạn kiệt bộ nhớ trong cụm ElastiCache của chúng tôi.
Chúng tôi đã có đủ lưu lượng công việc đi qua cụm ElastiCache của mình nên bất kỳ sự chậm trễ đáng kể nào trong quá trình xử lý tiếp theo sẽ có nguy cơ khiến cụm hết bộ nhớ. Mặc dù chúng tôi sử dụng một cụm riêng để lưu trữ dữ liệu không phải hàng đợi, nhưng theo thời gian, chúng tôi cũng có một số dữ liệu không phải hàng đợi hiển thị trong cụm chính, sau đó có thể bị loại bỏ trong trường hợp lỗi hết bộ nhớ. Tuy nhiên, vấn đề quan trọng hơn là không thể nhận công việc mới khi cụm hết bộ nhớ.
Vấn đề phụ là Redis/ElastiCache sử dụng volatile-lru chính sách trục xuất theo mặc định. Hậu quả của việc này là vào những thời điểm sử dụng bộ nhớ cao, Redis sẽ xóa dữ liệu ít được sử dụng gần đây nhất bằng bộ TTL. Tại một thời điểm, Honeybadger đã gặp sự cố trong đó mức sử dụng bộ nhớ của chúng tôi đủ cao đến mức Redis bắt đầu xóa bộ nhớ đệm khi chúng tôi không có ý định làm vậy. May mắn thay, dữ liệu bị loại bỏ có thể tái tạo được (do đó có TTL), vì vậy chúng tôi không mất bất kỳ dữ liệu vĩnh viễn nào.
Tuy nhiên, điều này để lại cho chúng tôi một câu hỏi cần được giải quyết - Điều gì sẽ xảy ra nếu một sự kiện tương tự xảy ra và chúng tôi bắt đầu mất dữ liệu mà chúng tôi không thể xây dựng lại? Làm thế nào chúng tôi có thể đảm bảo rằng chúng tôi không bao giờ mất dữ liệu khách hàng? Xử lý dữ liệu lỗi của khách hàng là cốt lõi trong hoạt động kinh doanh của chúng tôi, vì vậy chúng tôi cần một hệ thống có khả năng chống mất dữ liệu.
Sử dụng Kafka để nhập dữ liệu
Kafka là một hệ thống sự kiện phân tán cung cấp cả khả năng mở rộng và khả năng phục hồi. Với việc ra mắt Thông tin chi tiết gần đây, chúng tôi đã thu được nhiều kinh nghiệm trong việc xây dựng Kafka làm cơ sở hạ tầng để xử lý dữ liệu sự kiện của mình. Sau đó, chúng tôi muốn sử dụng cùng một nền tảng công nghệ để xử lý dữ liệu lỗi nhập. Chúng tôi mong muốn đạt được dung lượng lưu trữ dự phòng với khả năng mở rộng tốt hơn và chi phí phải chăng hơn bằng cách sử dụng Kafka.
Vì chúng tôi đang chạy cụm AWS MSK của riêng mình cho Thông tin chi tiết nên chúng tôi đã có cơ sở hạ tầng và thiết lập tự động điều chỉnh quy mô. Điều này có nghĩa là chúng tôi "chỉ" phải thiết lập một số chủ đề và tạo một số ứng dụng tiêu dùng chạy cùng mã với nhân viên Sidekiq của chúng tôi đã làm. Khái niệm này khá đơn giản, cho phép chúng tôi tập trung hơn vào việc điều chỉnh người tiêu dùng Kafka của mình.
Di chuyển từ Sidekiq sang Karafka
Honeybadger được thiết kế như một khối đá nguyên khối hùng vĩ và Karafka giúp chúng ta giữ nguyên kiến trúc đó. Chúng tôi đã sử dụng Karafka để xử lý một số dữ liệu Thông tin chi tiết của mình nên việc thêm một số người tiêu dùng mới là một nhiệm vụ đơn giản.
Một trong những khác biệt chính giữa Karafka và Sidekiq là cách truy xuất công việc. Với Karafka, các công việc được phân nhóm và xử lý cùng nhau trong một hoạt động tiêu dùng duy nhất. Trong ứng dụng tiêu dùng, chúng ta có thể lặp lại mảng thông báo và chạy nội tuyến của Sidekiq worker:
class NoticeConsumer < ApplicationConsumer
def consume
messages.each do |message|
NoticeWorker.new.perform(message.payload)
end
end
end
Một điểm khác biệt khác mà chúng tôi phải xem xét là cách xử lý lỗi hoạt động. Với Sidekiq, vì mỗi công việc đều mang tính nguyên tử nên một nhân viên sẽ tự xử lý lỗi của mình thông qua các lần thử lại và gọi lại khi thất bại. Với hành vi phân khối của Kafka, có nhiều lựa chọn hơn để xử lý lỗi. Đáng chú ý nhất, Karafka cung cấp một cơ chế gọi là Hàng đợi thư chết. Điều này cho phép bạn chỉ định việc xử lý lỗi trên cơ sở hàng loạt hoặc riêng lẻ.
dead_letter_queue(
topic: "ingestion.errors.dead",
max_retries: 5,
independent: true
)
Bất cứ khi nào người tiêu dùng Karafka gặp phải lỗi xử lý bất kỳ tin nhắn riêng lẻ nào, nó sẽ cố gắng xử lý lại 5 lần. Nếu lần thử thứ 5 không thành công, tin nhắn sẽ được gửi đến chủ đề được chỉ định. independent: true tùy chọn cho người tiêu dùng biết rằng chỉ cần gửi tin nhắn bị lỗi đến DLQ chứ không phải toàn bộ lô.
Giám sát và nhân rộng Karafka
Hóa ra, việc giám sát và mở rộng quy mô người tiêu dùng Karafka khá phức tạp. Có nhiều thứ bạn có thể theo dõi từ cả AWS/MSK và Karafka, cũng như nhiều nút bạn có thể xoay để điều chỉnh hệ thống của mình. Nó đòi hỏi sự chú ý cẩn thận đến mã của bạn đang làm gì, hành vi của luồng dữ liệu.
Với AWS CloudWatch, chúng tôi giám sát nhiều thứ nhưng dưới đây là một số chỉ số dành riêng cho Kafka mà chúng tôi xem xét:
- SumOffsetLag — Đối với một chủ đề và nhóm người tiêu dùng cụ thể, đây là tổng của tất cả độ trễ bù trừ trên tất cả các phân vùng.
- EstimatedMaxTimeLag — Đối với một chủ đề và nhóm người tiêu dùng cụ thể, đây là ước tính sẽ mất khoảng thời gian để bắt kịp tất cả các phân vùng cho phần bù hiện tại.
Karafka cũng cung cấp một số công cụ đo lường tuyệt vời, nhưng bạn sẽ cần xuất bản dữ liệu này và tự lưu trữ dữ liệu đó:
- xử lý_lag * — Giá trị này có sẵn cho mỗi lô tin nhắn được sử dụng. Nó cho bạn biết thời gian Karafka nhận được tin nhắn từ Kafka và bắt đầu xử lý nó.
- tiêu thụ_lag * — Giá trị này tương tự như processing_lag ngoại trừ đó là thời điểm kể từ khi tin nhắn cuối cùng của lô được đưa vào hệ thống Kafka cho đến khi người tiêu dùng của bạn bắt đầu xử lý nó.
- thời lượng * — Đây là thời gian để người tiêu dùng xử lý toàn bộ loạt tin nhắn.
Hóa ra, việc mở rộng quy mô của Sidekiq rất khác so với việc mở rộng quy trình của người tiêu dùng Karafka. Khi tăng khả năng song song hóa của Sidekiq, bạn có thể thêm nhiều quy trình hơn vào bất kỳ phiên bản Redis nào của bạn có thể xử lý. Với Kafka, bạn nhất định có tối đa 1 quy trình cho mỗi phân vùng trong chủ đề của mình. Theo nguyên tắc chung, bạn sẽ muốn có nhiều phân vùng hơn dự định vì người tiêu dùng Kafka có thể được chỉ định cho nhiều hơn 1 phân vùng.
Một điều khác cần nhớ là việc mở rộng quy mô và thu nhỏ quy mô người tiêu dùng Kafka có thể là một hoạt động rất dài. Việc thêm và loại bỏ người tiêu dùng khỏi nhóm người tiêu dùng đòi hỏi nhóm phải tự cân bằng lại. Điều này có nghĩa là chỉ định lại các phân vùng nếu cần thiết. Trong quá trình chỉ định lại, người tiêu dùng ngừng xử lý tin nhắn. Mặc dù bạn có thể giảm thiểu phần nào vấn đề này bằng sticky-cooperative được giao, bạn thường muốn tránh việc tái cân bằng nếu có thể bằng cách cung cấp quá nhiều tài nguyên.
Chúng tôi hiện đang theo dõi SumOffsetLag là một trong những số liệu mở rộng của chúng tôi. Điều quan trọng cần lưu ý là trong quá trình tái cân bằng, số liệu này không được báo cáo. Vì vậy, như bạn có thể tưởng tượng, trong giai đoạn tái cân bằng, số liệu này sẽ tăng mạnh cho đến khi quá trình tái cân bằng kết thúc. Đây là một lý do khác khiến điều quan trọng là phải tiếp tục mở rộng quy mô ở mức tối thiểu.
Điều gì tiếp theo dành cho Karafka tại Honeybadger?
Chúng tôi đã triển khai Kafka/Kaafka ở mức 100% trong hơn một tháng nay và có thể nói rằng chúng tôi khá hài lòng. Tuy nhiên, thật tuyệt khi biết rằng chúng ta luôn có thể quay lại Sidekiq chỉ bằng một nút nhấn nếu cần. Điều này mang lại cho chúng tôi khả năng phục hồi tốt hơn nữa khi bất kỳ hệ thống nào trong số này cần thực hiện công việc bảo trì.
Trong quá trình di chuyển từ Sidekiq sang Karafka, chúng tôi cũng học được nhiều điều hơn khi làm việc với Kafka và Karafka. Nếu bạn chưa cập nhật lên phiên bản mới nhất của đá quý Honeybadger, bạn nên kiểm tra nó! Tôi đã thêm một số tính năng mới vào plugin kaafka. Khi bạn bật Thông tin chi tiết, viên ngọc của chúng tôi sẽ bắt đầu theo dõi một số số liệu thống kê quan trọng để cung cấp cho bạn cái nhìn rõ hơn về tình trạng chung của hệ thống Kafka của bạn.
Ngoài ra, hiện tại chúng tôi có Bảng điều khiển Karakfa thông tin chi tiết để giúp bạn trực quan hóa dữ liệu này và giúp bạn hiểu rõ hơn về cách người tiêu dùng Kafka của bạn đang hành xử. Bảng điều khiển Karafka yêu cầu bật số liệu cho plugin. Để làm điều đó, hãy thêm cấu hình sau vào honeybadger.yml của bạn :
karafka:
insights:
metrics: true
Đây là mẫu trang tổng quan trông như thế nào:
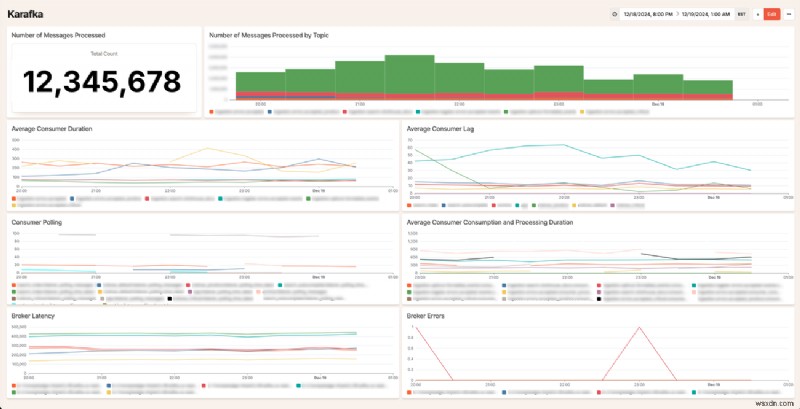
Chúng tôi rất vui khi thấy khách hàng của mình sử dụng dữ liệu này như thế nào để cải thiện hệ thống Kafka của riêng họ. Nếu bạn có bất kỳ câu hỏi nào về cách chúng tôi di chuyển từ Sidekiq sang Karafka hoặc cách chúng tôi sử dụng Kafka nói chung, vui lòng liên hệ!