Chào mừng bạn quay trở lại loạt bài này về cách xây dựng trình duyệt web. Trong hướng dẫn này, tôi sẽ xem qua một ví dụ về việc thu thập dữ liệu từ trang podcast của riêng tôi. Tôi sẽ trình bày chi tiết cách tôi trích xuất dữ liệu, cách người trợ giúp và các phương thức tiện ích hoàn thành công việc của họ và cách tất cả các mảnh ghép kết hợp với nhau.
Chủ đề
- Ghi lại Podcast của tôi
- Pry
- Scraper
- Phương pháp của người trợ giúp
- Viết bài
Ghi lại Podcast của tôi
Hãy đưa những gì chúng ta đã học được cho đến nay vào thực tế. Vì nhiều lý do khác nhau, một bản thiết kế lại cho podcast của tôi Giữa | Màn hình đã quá hạn từ lâu. Có những vấn đề khiến tôi hét lên khi thức dậy vào buổi sáng. Vì vậy, tôi quyết định thiết lập một trang web tĩnh hoàn toàn mới, được xây dựng bằng Middleman và được lưu trữ bằng GitHub Pages.
Tôi đã đầu tư rất nhiều thời gian vào thiết kế mới sau khi tôi chỉnh sửa một blog Middleman theo nhu cầu của mình. Tất cả những gì còn lại phải làm là nhập nội dung từ ứng dụng Sinatra được hỗ trợ cơ sở dữ liệu của tôi, vì vậy tôi cần phải loại bỏ nội dung hiện có và chuyển nó vào trang web tĩnh mới của mình.
Làm điều này bằng tay theo phong cách schmuck không phải bàn - thậm chí không phải là một câu hỏi - vì tôi có thể dựa vào bạn bè Nokogiri và Mechanize để thực hiện công việc cho tôi. Những gì trước mắt bạn là một công việc cạo nhỏ hợp lý, không quá phức tạp nhưng cung cấp một số điều thú vị nên có tính giáo dục cho những người mới tìm kiếm web ngoài kia.
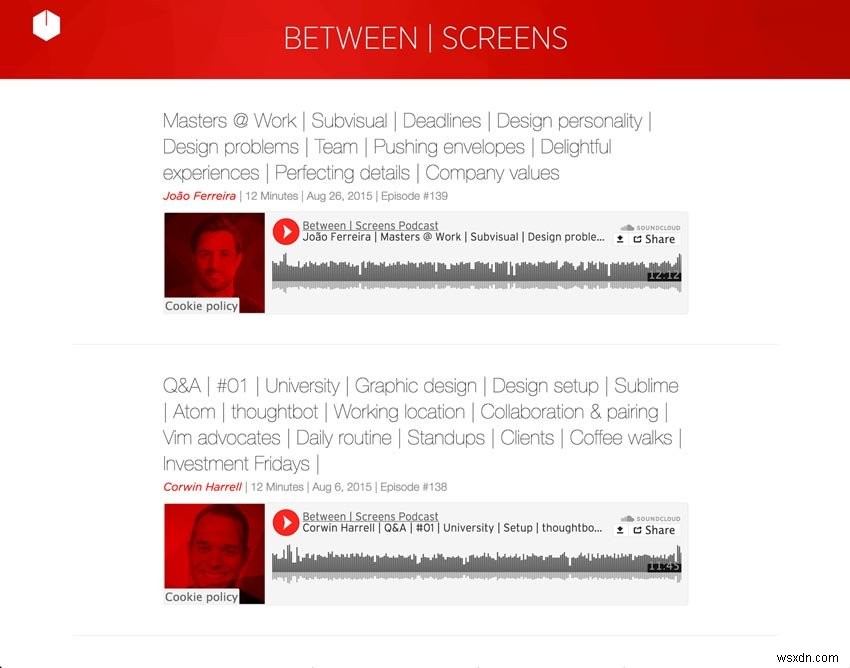
Dưới đây là hai ảnh chụp màn hình từ podcast của tôi.
Ảnh chụp màn hình Podcast Cũ
Ảnh chụp màn hình Podcast mới
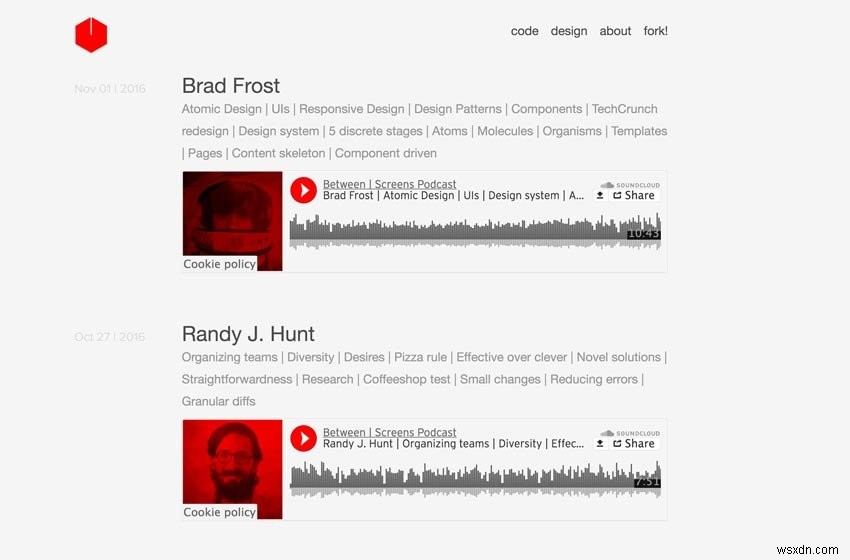
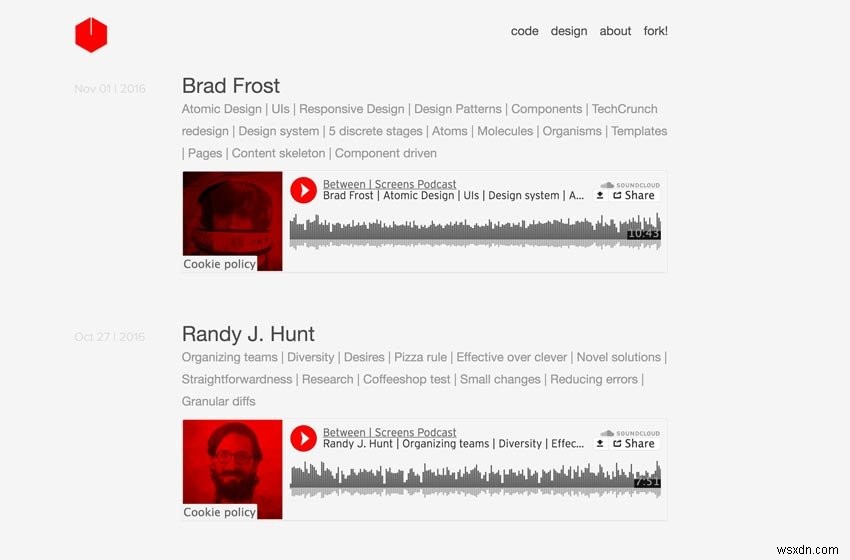
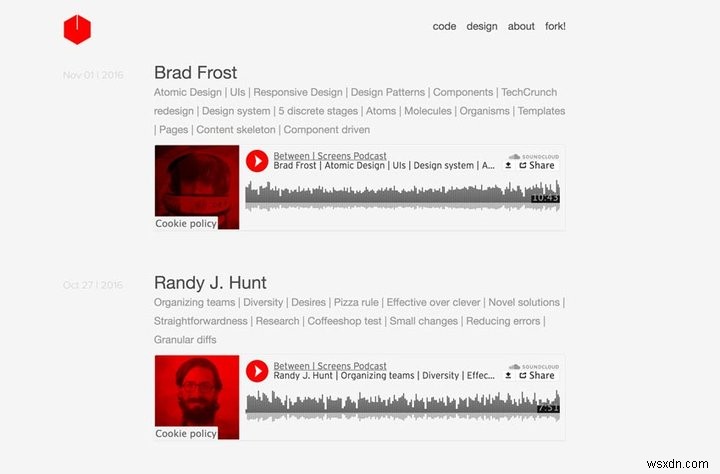
Hãy chia nhỏ những gì chúng ta muốn đạt được. Chúng tôi muốn trích xuất dữ liệu sau từ 139 tập phim được trải rộng trên 21 trang web chỉ mục được phân trang:
- tiêu đề
- người được phỏng vấn
- tiêu đề phụ với danh sách chủ đề
- số bản nhạc SoundCloud cho mỗi tập
- ngày
- số tập
- văn bản từ ghi chú chương trình
- các liên kết từ ghi chú chương trình
Chúng tôi lặp đi lặp lại việc phân trang và cho phép Mechanize nhấp vào mọi liên kết cho một tập. Trên trang chi tiết sau đây, chúng tôi sẽ tìm thấy tất cả thông tin từ phía trên mà chúng tôi cần. Bằng cách sử dụng dữ liệu cóp nhặt đó, chúng tôi muốn điền vấn đề chính và "nội dung" của các tệp đánh dấu cho mỗi tập.
Dưới đây, bạn có thể xem bản xem trước về cách chúng tôi sẽ soạn các tệp đánh dấu mới với nội dung mà chúng tôi đã trích xuất. Tôi nghĩ điều này sẽ cung cấp cho bạn một ý tưởng tốt về phạm vi phía trước của chúng tôi. Điều này đại diện cho bước cuối cùng trong kịch bản nhỏ của chúng tôi. Đừng lo lắng, chúng tôi sẽ xem xét chi tiết hơn.
def compos_markdown
def compile_markdown (options ={}) <<- HEREDOC --- title:# {options [:interviewee]} người được phỏng vấn:# {options [:interviewee]} topic_list:# {options [:title]} các thẻ:# {options [:tags]} soundcloud_id:# {options [:sc_id]} date:# {options [:date]} episode_number:# {options [:episode_number]} --- # {options [:text]} HEREDOCend
Tôi cũng muốn thêm một vài thủ thuật mà trang web cũ không chơi được. Có một hệ thống gắn thẻ toàn diện, tùy chỉnh tại chỗ là rất quan trọng đối với tôi. Tôi muốn người nghe có một công cụ khám phá sâu sắc. Do đó, tôi cần các thẻ cho mọi người được phỏng vấn và chia tiêu đề phụ thành các thẻ. Vì tôi đã sản xuất 139 tập chỉ trong mùa đầu tiên, nên tôi đã phải chuẩn bị trang web trong một khoảng thời gian khi lượng nội dung trở nên khó xem hơn. Một hệ thống gắn thẻ sâu với các đề xuất được đặt thông minh là cách để đi. Điều này cho phép tôi giữ cho trang web nhẹ và nhanh chóng.
Hãy xem mã hoàn chỉnh để tìm nội dung trang web của tôi. Nhìn xung quanh và cố gắng tìm ra bức tranh toàn cảnh về những gì đang diễn ra. Vì tôi kỳ vọng bạn ở khía cạnh mới bắt đầu của mọi thứ, tôi đã tránh xa việc trừu tượng hóa quá nhiều và sai lầm ở khía cạnh rõ ràng. Tôi đã thực hiện một vài lần tái cấu trúc nhằm mục đích hỗ trợ sự rõ ràng của mã, nhưng tôi cũng để lại một chút thịt trong xương cho bạn chơi khi bạn kết thúc bài viết này. Rốt cuộc, việc học có chất lượng xảy ra khi bạn vượt ra ngoài việc đọc và đùa giỡn với một số mã của riêng mình.
Trong quá trình này, tôi thực sự khuyến khích bạn bắt đầu suy nghĩ về cách bạn có thể cải thiện mã trước mặt bạn. Đây sẽ là nhiệm vụ cuối cùng của bạn ở cuối bài viết này. Một gợi ý nhỏ từ tôi:chia nhỏ các phương pháp lớn thành các phương pháp nhỏ hơn luôn là một điểm khởi đầu tốt. Một khi bạn hiểu cách hoạt động của mã, bạn sẽ có một khoảng thời gian vui vẻ để trau dồi về việc tái cấu trúc đó.
Tôi đã bắt đầu bằng cách trích xuất một loạt các phương pháp thành các trình trợ giúp tập trung, nhỏ. Bạn có thể dễ dàng áp dụng những gì bạn đã học được từ các bài viết trước của tôi về mùi mã và cách tái cấu trúc của chúng. Nếu điều này vẫn còn xảy ra trong đầu bạn ngay bây giờ, đừng lo lắng — tất cả chúng tôi đã ở đó. Chỉ cần giữ ở mức đó, và đến một lúc nào đó, mọi thứ sẽ bắt đầu nhấp nhanh hơn.
Mã đầy đủ
Require 'Mechanize'dquire' Pry'require 'date' # Trợ giúp Phương pháp # (Phương pháp trích xuất) def extract_interviewee (detail_page) phỏng vấn =".ep Chap_title" detail_page.search (title_selector) .text.gsub (/ [? #] /, '') enddef extract_soundcloud_id (detail_page) sc =detail_page.iframes_with (href:/soundcloud.com/).to_s sc.scan (/\d{3,}/).firstenddef extract_shownotes_text (detail_page) shownote_selector ="#shownote_container> p" detail_page.search (shownote_selector) enddef extract_subtitle (detail_page) subheader_selector =".ep Chap_sub_tind_duct_counter (episode_subtitle) number =/[#]\d*/.match(ep Chap_subtitle) clean_ep Chap_number (number) end # (Phương thức tiện ích) def clean_date (episode_subtitle) string_date =/ [^ |] * ([,]) (... ..) /. match (episode_subtitle) .to_s Date.parse (string_date) endde f build_tags (tiêu đề, người được phỏng vấn) extract_tags =dải_pipes (tiêu đề) "# {người phỏng vấn}" + ", # {extract_tags}" enddef dải_pipes (văn bản) tags =text.tr ('|', ',') tags =các thẻ. gsub (/ [@? # &] /, '') tags.gsub (/ [w \ /] {2} /, 'with') enddef clean_ep Chap_number (number) number.to_s.tr ('#', '' ) enddef dasherize (text) text.lstrip.rstrip.tr ('', '-') enddef extract_data (detail_page) phỏng vấnee =extract_interviewee (detail_page) title =extract_title (detail_page) sc_id =extract_soundcloud_id (detail_page) text =extract_shownotes_text (detail_page) Episode_subtitle =extract_subtitle (detail_page) episode_number =extract_ep Chap_number (Episode_subtitle) date =clean_date (episode_subtitle) tags =build_tags (title, người được phỏng vấn) options ={interviewee:người được phỏng vấn, title:title, sc_id:sc_id, text:text, tags:tags, date :date, episode_number:episode_number} enddef compo_markdown (options ={}) <<- HEREDOC --- title:# {option s [:interviewee]} người được phỏng vấn:# {options [:interviewee]} topic_list:# thẻ {options [:title]}:# {options [:tags]} soundcloud_id:# {options [:sc_id]} ngày:# { options [:date]} episode_number:# {options [:episode_number]} --- # {options [:text]} HEREDOCenddef write_page (link) detail_page =link.click extract_data =extract_data (detail_page) markdown_text =compo_markdown (extract_data) ngày =extract_data [:date] interviewee =extract_data [:interviewee] episode_number =extract_data [:episode_number] File.open ("# {date} - # {dasherize (phỏng vấn)} - # {episode_number} .html.erb.md", 'w') {| tệp | file.write (markdown_text)} enddef scrape link_range =1 agent || =Mechanize.new cho đến khi link_range ==21 page =agent.get ("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range + =1 page.links [2..8] .map do | link | write_page (liên kết) end endendscrape
Tại sao chúng tôi không require "Nokogiri" ? Cơ khí hóa cung cấp cho chúng tôi tất cả các nhu cầu cạo của chúng tôi. Như chúng ta đã thảo luận trong bài viết trước, Mechanize xây dựng trên Nokogiri và cho phép chúng tôi trích xuất nội dung. Tuy nhiên, điều quan trọng là phải đề cập đến viên ngọc đó trong bài viết đầu tiên vì chúng tôi cần xây dựng trên đó.
Pry
Những điều đầu tiên trước tiên. Trước khi chúng ta tìm hiểu mã của mình ở đây, tôi nghĩ cần phải chỉ cho bạn cách bạn có thể kiểm tra một cách hiệu quả xem mã của bạn có hoạt động như mong đợi ở mọi bước hay không. Như bạn chắc chắn đã nhận thấy, tôi đã thêm một công cụ khác vào hỗn hợp. Trong số những thứ khác, Pry thực sự tiện dụng để gỡ lỗi.
Nếu bạn đặt Pry.start(binding) ở bất kỳ vị trí nào trong mã của bạn, bạn có thể kiểm tra ứng dụng của mình chính xác tại thời điểm đó. Bạn có thể tìm hiểu các đối tượng tại các điểm cụ thể trong ứng dụng. Điều này thực sự hữu ích để thực hiện từng bước ứng dụng của bạn mà không vấp phải đôi chân của chính bạn. Ví dụ:hãy đặt nó ngay sau write_page của chúng tôi chức năng và kiểm tra xem link là những gì chúng tôi mong đợi.
Pry
... def scrape link_range =1 agent || =Mechanize.new cho đến khi link_range ==21 page =agent.get ("https://between-screens.herokuapp.com/?page=#{link_range}" ) link_range + =1 page.links [2..8] .map do | link | write_page (liên kết) Pry.start (ràng buộc) end endend ...
Nếu bạn chạy script, chúng ta sẽ nhận được một cái gì đó như thế này.
Đầu ra
»$ ruby noko_scraper.rb 321:def scrape 322:link_range =1 323:agent || =Mechanize.new 324:326:cho đến khi link_range ==21 327:page =agent.get (" https:// between -screens.herokuapp.com/?page=#{link_range} ") 328:link_range + =1 329:330:page.links [2..8] .map do | link | 331:write_page (liên kết) => 332:Pry.start (ràng buộc) 333:end 334:end 335:end [1] pry (main)>
Sau đó, khi chúng tôi yêu cầu liên kết link đối tượng, chúng tôi có thể kiểm tra xem chúng tôi có đang đi đúng hướng hay không trước khi chuyển sang các chi tiết triển khai khác.
Nhà ga
[2] pry (main)> link => #
Có vẻ như những gì chúng tôi cần. Tuyệt vời, chúng ta có thể tiếp tục. Thực hiện từng bước này qua toàn bộ ứng dụng là một thực hành quan trọng để đảm bảo rằng bạn không bị lạc và bạn thực sự hiểu cách hoạt động của nó. Tôi sẽ không trình bày chi tiết hơn về Pry ở đây vì tôi sẽ mất ít nhất một bài báo đầy đủ khác để làm như vậy. Tôi chỉ có thể khuyên bạn nên sử dụng nó như một giải pháp thay thế cho IRB shell tiêu chuẩn. Quay lại nhiệm vụ chính của chúng ta.
Scraper
Bây giờ bạn đã có cơ hội làm quen với các mảnh ghép tại chỗ, tôi khuyên bạn nên xem qua từng mảnh một và làm rõ một vài điểm thú vị ở đây và ở đó. Hãy bắt đầu với các phần trung tâm.
podcast_scraper.rb
... def write_page (link) detail_page =link.click extract_data =extract_data (detail_page) markdown_text =compo_markdown (extract_data) date =extract_data [:date] interviewee =extract_data [:interviewee] episode_number =extract_data [:episode_number] file_name ="# {date} - # {dasherize (người được phỏng vấn)} - # {episode_number} .html.erb.md" File.open (file_name, 'w') {| file | file.write (markdown_text)} enddef scrape link_range =1 agent || =Mechanize.new cho đến khi link_range ==21 page =agent.get ("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range + =1 page.links [2..8] .map do | link | write_page (liên kết) end endend ...
Điều gì xảy ra trong scrape phương pháp? Trước hết, tôi lặp lại mọi trang chỉ mục trong podcast cũ. Tôi đang sử dụng URL cũ từ ứng dụng Heroku vì trang web mới đã trực tuyến tại betweenscreens.fm. Tôi có 20 trang tập mà tôi cần lặp lại.
Tôi đã phân tách vòng lặp qua link_range biến mà tôi đã cập nhật với mỗi vòng lặp. Thực hiện phân trang đơn giản bằng cách sử dụng biến này trong URL của mỗi trang. Đơn giản và hiệu quả.
def scrape
page =agent.get ("https://between-screens.herokuapp.com/?page=#{link_range}")
Sau đó, bất cứ khi nào tôi có một trang mới với tám tập khác để sửa, tôi sử dụng page.links để xác định các liên kết mà chúng tôi muốn nhấp và theo dõi đến trang chi tiết cho từng tập. Tôi quyết định sử dụng một loạt các liên kết (links[2..8] ) vì nó nhất quán trên mọi trang. Đó cũng là cách dễ nhất để nhắm mục tiêu các liên kết tôi cần từ mỗi trang chỉ mục. Không cần phải mò mẫm với các bộ chọn CSS ở đây.
Sau đó, chúng tôi cung cấp liên kết đó cho trang chi tiết đến write_page phương pháp. Đây là nơi phần lớn công việc được thực hiện. Chúng tôi lấy liên kết đó, nhấp vào nó và theo nó đến trang chi tiết nơi chúng tôi có thể bắt đầu trích xuất dữ liệu của nó. Trên trang đó, chúng tôi tìm thấy tất cả thông tin mà tôi cần để soạn các tập đánh dấu mới cho trang web mới.
def write_page
extract_data =extract_data (detail_page)
def extract_data
def extract_data (detail_page) interviewee =extract_interviewee (detail_page) title =extract_title (detail_page) sc_id =extract_soundcloud_id (detail_page) text =extract_shownotes_text (detail_page) episode_subtitle =extract_subtitle (detail_page) episode_ntle =extract_ep Chap 1 tags =build_tags (tiêu đề, người được phỏng vấn) options ={người được phỏng vấn:người được phỏng vấn, title:title, sc_id:sc_id, text:text, tags:tags, date:date, episode_number:episode_number} end
Như bạn có thể thấy ở trên, chúng tôi lấy detail_page đó và áp dụng một loạt các phương pháp chiết xuất trên đó. Chúng tôi trích xuất interviewee , title , sc_id , text , episode_title và episode_number . Tôi đã cấu trúc lại một loạt các phương pháp trợ giúp tập trung phụ trách các trách nhiệm trích xuất này. Hãy xem nhanh chúng:
Phương thức của người trợ giúp
Phương pháp chiết xuất
Tôi đã trích xuất các trình trợ giúp này vì nó cho phép tôi có các phương pháp nhỏ hơn về tổng thể. Đóng gói hành vi của họ cũng rất quan trọng. Mã đọc tốt hơn. Hầu hết trong số họ lấy detail_page như một đối số và trích xuất một số dữ liệu cụ thể mà chúng tôi cần cho các bài đăng của Middleman.
def extract_interviewee (detail_page) interviewee_selector ='.ep Chap_sub_title span' detail_page.search (interviewee_selector) .text.stripend
Chúng tôi tìm kiếm trên trang để tìm một bộ chọn cụ thể và lấy văn bản không có khoảng trắng không cần thiết.
def extract_title (detail_page) title_selector =".ep Chap_title" detail_page.search (title_selector) .text.gsub (/ [? #] /, '') end
Chúng tôi lấy tiêu đề và xóa ? và # vì những thứ này không phù hợp với vấn đề chính trong các bài đăng cho các tập của chúng ta. Thông tin thêm về vấn đề phía trước bên dưới.
def extract_soundcloud_id (detail_page) sc =detail_page.iframes_with (href:/soundcloud.com/).to_s sc.scan (/ \ d {3,} /). firstend
Ở đây, chúng tôi cần phải làm việc chăm chỉ hơn một chút để trích xuất id SoundCloud cho các bản nhạc được lưu trữ của chúng tôi. Đầu tiên, chúng ta cần Cơ chế iframe với href của soundcloud.com và biến nó thành một chuỗi để quét ...
"[#\ n]"
Sau đó, đối sánh một biểu thức chính quy cho các chữ số của id bản nhạc — soundcloud_id của chúng tôi "221003494" .
def extract_shownotes_text (detail_page) shownote_selector ="#shownote_container> p" detail_page.search (shownote_selector) end
Việc trích xuất các ghi chú chương trình một lần nữa khá đơn giản. Chúng tôi chỉ cần tìm các đoạn của ghi chú chương trình trong trang chi tiết. Không có gì ngạc nhiên ở đây.
def extract_subtitle (detail_page) subheader_selector =".ep Chap_sub_title" detail_page.search (subheader_selector) .textend
Tương tự với phụ đề, ngoại trừ việc nó chỉ là một bước chuẩn bị để trích xuất rõ ràng số tập từ đó.
def extract_ep Chap_number (episode_subtitle) number =/[#]\d*/.match(ep Chap_subtitle) clean_ep Chap_number (number) end
Ở đây chúng ta cần một vòng biểu thức chính quy khác. Hãy xem trước và sau khi chúng tôi áp dụng regex.
episode_subtitle
"João Ferreira | 12 phút | 26 tháng 8 năm 2015 | Episode # 139"
số
"# 139"
Một bước nữa cho đến khi chúng ta có một số sạch.
def clean_ep Chap_number (number) number.to_s.tr ('#', '') end
Chúng tôi lấy số đó với một băm # và loại bỏ nó. Voilà, chúng ta có số tập đầu tiên 139 được trích xuất. Tôi đề nghị chúng ta cũng nên xem xét các phương pháp tiện ích khác trước khi chúng ta kết hợp tất cả lại với nhau.
Phương thức Tiện ích
Sau tất cả công việc khai thác đó, chúng tôi có một số công việc dọn dẹp. Chúng tôi đã có thể bắt đầu chuẩn bị dữ liệu để soạn đánh dấu. Ví dụ:tôi cắt episode_subtitle một số khác để có được một ngày rõ ràng và xây dựng các thẻ link với build_tags phương pháp.
def clean_date
def clean_date (episode_subtitle) string_date =/[^|]*([,])(.....)/.match(ep Chap_subtitle).to_s Date.parse (string_date) end
Chúng tôi chạy một regex khác tìm kiếm những ngày như sau:" Aug 26, 2015" . Như bạn có thể thấy, điều này vẫn chưa hữu ích lắm. Từ string_date chúng tôi nhận được từ phụ đề, chúng tôi cần tạo một Date thực sự vật. Nếu không, nó sẽ vô ích cho việc tạo các bài đăng của Middleman.
string_date
"Ngày 26 tháng 8 năm 2015"
Do đó, chúng tôi lấy chuỗi đó và thực hiện Date.parse . Kết quả có vẻ hứa hẹn hơn rất nhiều.
Ngày
2015-08-26
def build_tags
def build_tags (tiêu đề, người được phỏng vấn) extract_tags =strip_pipes (tiêu đề) "# {interviewee}" + ", # {extract_tags}" end
Điều này lấy title và interviewee chúng tôi đã xây dựng bên trong extract_data và loại bỏ tất cả các ký tự ống dẫn và rác. Chúng tôi thay thế các ký tự ống dẫn bằng dấu phẩy, @ , ? , # và & với một chuỗi trống và cuối cùng quan tâm đến các chữ viết tắt của with .
def dải_pipes
def dải_pipes (văn bản) tags =text.tr ('|', ',') tags =tags.gsub (/ [@? # &] /, '') tags.gsub (/ [w \ /] {2} /, 'with') end
Cuối cùng, chúng tôi cũng đưa tên người được phỏng vấn vào danh sách thẻ và phân tách từng thẻ bằng dấu phẩy.
Trước
"Masters @ Work | Subvisual | Thời hạn | Tính cách thiết kế | Vấn đề thiết kế | Đội ngũ | Đẩy phong bì | Trải nghiệm thú vị | Hoàn thiện chi tiết | Giá trị công ty"
Sau
"João Ferreira, Công việc bậc thầy, Trực quan, Thời hạn, Tính cách thiết kế, Vấn đề thiết kế, Đội ngũ, Đẩy phong bì, Trải nghiệm thú vị, Hoàn thiện chi tiết, Giá trị công ty"
Mỗi thẻ này sẽ trở thành một liên kết đến một bộ sưu tập các bài đăng cho chủ đề đó. Tất cả điều này xảy ra bên trong extract_data phương pháp. Chúng ta hãy có một cái nhìn khác về vị trí của chúng tôi:
def extract_data
def extract_data (detail_page) interviewee =extract_interviewee (detail_page) title =extract_title (detail_page) sc_id =extract_soundcloud_id (detail_page) text =extract_shownotes_text (detail_page) episode_subtitle =extract_subtitle (detail_page) episode_ntle =extract_ep Chap 1 tags =build_tags (tiêu đề, người được phỏng vấn) options ={người được phỏng vấn:người được phỏng vấn, title:title, sc_id:sc_id, text:text, tags:tags, date:date, episode_number:episode_number} end
Tất cả những gì còn lại cần làm ở đây là trả về một băm tùy chọn với dữ liệu mà chúng tôi trích xuất. Chúng tôi có thể cung cấp hàm băm này vào compose_markdown phương pháp này giúp dữ liệu của chúng tôi sẵn sàng để được ghi ra dưới dạng tệp mà tôi cần cho trang web mới của mình.
Viết bài
def compos_markdown
def compile_markdown (options ={}) <<- HEREDOC --- title:# {options [:interviewee]} người được phỏng vấn:# {options [:interviewee]} topic_list:# {options [:title]} các thẻ:# {options [:tags]} soundcloud_id:# {options [:sc_id]} date:# {options [:date]} episode_number:# {options [:episode_number]} --- # {options [:text]} HEREDOCend
Để xuất bản các tập podcast trên trang Middleman của tôi, tôi đã chọn sử dụng lại hệ thống viết blog của nó. Thay vì tạo các bài đăng blog “thuần túy”, tôi tạo ghi chú chương trình cho các tập của mình để hiển thị các tập được lưu trữ trên SoundCloud thông qua iframe. Trên các trang chỉ mục, tôi chỉ hiển thị khung nội tuyến đó cùng với tiêu đề và nội dung.
Định dạng tôi cần để điều này hoạt động được bao gồm một thứ gọi là vật chất phía trước. Về cơ bản, đây là một kho lưu trữ khóa / giá trị cho các trang web tĩnh của tôi. Nó đang thay thế nhu cầu cơ sở dữ liệu của tôi từ trang Sinatra cũ của tôi.
Dữ liệu như tên người được phỏng vấn, ngày tháng, id bản nhạc SoundCloud, số tập, v.v. nằm giữa ba dấu gạch ngang (--- ) trên đầu các tệp tập của chúng tôi. Dưới đây là nội dung cho từng tập — những thứ như câu hỏi, liên kết, nội dung nhà tài trợ, v.v.
Vấn đề phía trước
--- key:valuekey:valuekey:valuekey:value --- Nội dung tập ở đây.
Trong compose_markdown , tôi sử dụng HEREDOC để soạn tệp đó với nội dung chính của nó cho mỗi tập mà chúng tôi lặp lại. Từ hàm băm tùy chọn mà chúng tôi cung cấp cho phương pháp này, chúng tôi trích xuất tất cả dữ liệu mà chúng tôi đã thu thập trong extract_data phương pháp trợ giúp.
def compos_markdown
... <<- HEREDOC --- title:# {options [:interviewee]} người được phỏng vấn:# {options [:interviewee]} topic_list:# {options [:title]} các thẻ:# {options [:tags]} soundcloud_id:# {options [:sc_id]} date:# {options [:date]} episode_number:# {options [:episode_number]} --- # {options [:text]} HEREDOC ...
Đây là bản thiết kế cho một tập podcast mới ngay tại đó. Đây là những gì chúng tôi đến để làm. Có lẽ bạn đang thắc mắc về cú pháp cụ thể này:#{options[:interviewee]} . Tôi nội suy như bình thường với các chuỗi, nhưng vì tôi đã ở trong một <<-HEREDOC , Tôi có thể bỏ dấu ngoặc kép đi.
Chỉ để tự định hướng, chúng tôi vẫn đang ở trong vòng lặp, bên trong write_page chức năng cho mỗi liên kết được nhấp đến một trang chi tiết với ghi chú chương trình của một tập số ít. Điều gì xảy ra tiếp theo là chuẩn bị ghi bản thiết kế này vào hệ thống tệp. Nói cách khác, chúng tôi tạo tập thực tế bằng cách cung cấp tên tệp và markdown_text đã soạn .
Đối với bước cuối cùng đó, chúng ta chỉ cần chuẩn bị những nguyên liệu sau:ngày tháng, tên người được phỏng vấn và số tập. Cộng với markdown_text tất nhiên, cái mà chúng tôi vừa nhận được từ compose_markdown .
def write_page
... markdown_text =compo_markdown (extract_data) date =extract_data [:date] interviewee =extract_data [:interviewee] episode_number =extract_data [:episode_number] file_name ="# {date} - # {dasherize (người được phỏng vấn)} - # {episode_number} .html.erb.md "...
Sau đó, chúng ta chỉ cần lấy file_name và markdown_text và ghi tệp.
def write_page
... File.open (tên_tệp, 'w') {| tệp | file.write (markdown_text)} ...
Chúng ta cũng hãy chia nhỏ điều này. Đối với mỗi bài đăng, tôi cần một định dạng cụ thể:chẳng hạn như 2016-10-25-Avdi-Grimm-120 . Tôi muốn viết ra các tệp bắt đầu bằng ngày tháng và bao gồm tên người được phỏng vấn và số tập.
Để phù hợp với định dạng mà Middleman mong đợi cho các bài đăng mới, tôi cần lấy tên người được phỏng vấn và đặt tên đó thông qua phương thức trợ giúp của tôi để dasherize tên cho tôi, từ Avdi Grimm thành Avdi-Grimm . Không có gì kỳ diệu, nhưng đáng xem:
def dasherize
def dasherize (text) text.lstrip.rstrip.tr ('', '-') end
Nó loại bỏ khoảng trắng khỏi văn bản mà chúng tôi đã cạo cho tên người được phỏng vấn và thay thế khoảng trắng giữa Avdi và Grimm bằng một dấu gạch ngang. Phần còn lại của tên tệp được gạch ngang với nhau trong chính chuỗi:"date-interviewee-name-episodenumber" .
def write_page
... "# {date} - # {dasherize (người được phỏng vấn)} - # {episode_number} .html.erb.md" ...
Vì nội dung được trích xuất đến trực tiếp từ một trang web HTML, tôi không thể chỉ sử dụng .md hoặc .markdown dưới dạng phần mở rộng tên tệp. Tôi quyết định sử dụng .html.erb.md . Đối với các tập trong tương lai mà tôi soạn mà không cần cắt, tôi có thể bỏ đi .html.erb một phần và chỉ cần .md .
Sau bước này, vòng lặp trong scrape hàm kết thúc và chúng ta sẽ có một tập duy nhất giống như sau:
2014-12-01-Avdi-Grimm-1.html.erb.md
--- title:Avdi Grimmi Người xem:Avdi Grimmtopic_list:Rake là gì | Nguồn gốc | Jim Weirich | Các trường hợp sử dụng phổ biến | Ưu điểm của Raketags:Avdi Grimm, Rake là gì, Nguồn gốc, Jim Weirich, Các trường hợp sử dụng phổ biến, Ưu điểm của Rakesoundcloud_id:179619755date:2014-12-01ep Chap_number:1 --- Câu hỏi:- Rake là gì? - Bạn có thể cho chúng tôi biết về điều gì nguồn gốc của Rake? - Bạn có thể cho chúng tôi biết gì về Jim Weihrich? - Các trường hợp sử dụng phổ biến nhất của Rake là gì? - Ưu điểm đáng chú ý nhất của Rake là gì? Liên kết:Trong "> http://www.youtube.com / watch? v =2ZHJSrF52bc "> Tưởng nhớ Jim WeirichRake vĩ đại"> https://github.com/jimweirich/rake "> Cào trên GitHubJim"> https://github.com/jimweirich "> Jim Weirich trên GitHubBasic "> http://www.youtube.com/watch?v=AFPWDzHWjEY"> Bài nói chuyện về Cào cào cơ bản của Jim WeirichPower "> http://www.youtube.com/watch?v=KaEqZtulOus"> Bài nói chuyện về Cỗ điện của Jim WeirichLearn "> http://devblog.avdi.org/2014/04/30/learn-advanced-rake-in-7-episodes/"> Học Rake nâng cao trong 7 tập - từ Avdi Grimm (miễn phí) Avdi "> http://about.avdi.org/">Avdi GrimmAvdi Grimm's screencasts:Ruby "> http://www.rubytapas.com/"> Ruby TapasRuby "> htt p://devchat.tv/ruby-rogues/ "> Ruby Rogues podcast với Avdi GrimmGreat ebook:Rake"> http://www.amazon.com/Rake-Management-Essentials-Andrey-Koleshko/dp/1783280778 "> Rake Task Management Essentials fromhttps://twitter.com/ka8725 "> Andrey Koleshko
Tất nhiên, trình quét này sẽ bắt đầu ở tập cuối cùng và lặp lại cho đến tập đầu tiên. Đối với mục đích trình diễn, tập 01 cũng tốt như bất kỳ. Bạn có thể thấy vấn đề hàng đầu với dữ liệu chúng tôi trích xuất.
Tất cả những thứ đó trước đây đã bị khóa trong cơ sở dữ liệu của ứng dụng Sinatra của tôi — số tập, ngày tháng, tên người được phỏng vấn, v.v. Bây giờ chúng tôi đã chuẩn bị cho nó trở thành một phần của trang Middleman tĩnh mới của tôi. Mọi thứ bên dưới hai dấu gạch ngang ba (--- ) là văn bản từ ghi chú chương trình:chủ yếu là câu hỏi và liên kết.
Lời kết
Và chúng tôi đã hoàn thành. Podcast mới của tôi đã hoạt động. Tôi thực sự vui mừng vì đã dành thời gian để thiết kế lại mọi thứ từ đầu. Giờ đây, việc xuất bản các tập mới sẽ thú vị hơn rất nhiều. Khám phá nội dung mới cũng sẽ mượt mà hơn cho người dùng.
Như tôi đã đề cập trước đó, đây là lúc bạn nên vào trình soạn thảo mã của mình để giải trí. Lấy mã này và vật lộn với nó một chút. Cố gắng tìm cách làm cho nó đơn giản hơn. Có một vài cơ hội để cấu trúc lại mã.
Nhìn chung, tôi hy vọng ví dụ nhỏ này đã cung cấp cho bạn một ý tưởng tốt về những gì bạn có thể làm với các bộ sưu tập web mới của mình. Tất nhiên, bạn có thể đạt được những thách thức phức tạp hơn nhiều — tôi chắc chắn rằng thậm chí có rất nhiều cơ hội kinh doanh nhỏ được thực hiện với những kỹ năng này.
Nhưng như mọi khi, hãy thực hiện từng bước một và đừng quá thất vọng nếu mọi thứ không nhấp chuột ngay lập tức. Điều này không chỉ bình thường đối với hầu hết mọi người mà còn được mong đợi. Đó là một phần của cuộc hành trình. Chúc bạn cạo râu vui vẻ!