Bạn sẽ làm gì nếu bạn được giao một bộ sưu tập văn bản lớn và bạn muốn rút ra một số ý nghĩa từ nó?
Một khởi đầu tốt là chia nhỏ văn bản của bạn thành n-gram .
Đây là mô tả :
Trong các lĩnh vực ngôn ngữ học tính toán và xác suất, n-gram là một chuỗi n mục liền nhau từ một chuỗi văn bản nhất định. - Wikipedia
Ví dụ :
Nếu chúng ta sử dụng cụm từ "Xin chào, bạn có khỏe không?" thì các đơn vị (ngram của một phần tử) sẽ là:"Hello", "there", "how", "are", "you" và bigram (ngram của hai phần tử):["Hello", "there"], ["there", "how"], ["how", "are"], ["are", "you"] .
Nếu bạn học tốt hơn với hình ảnh đây là hình ảnh của điều đó:
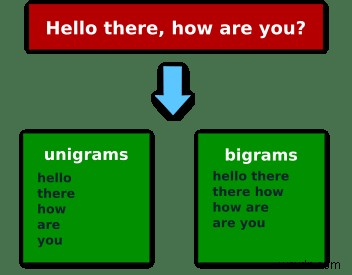
Bây giờ, hãy xem cách bạn có thể triển khai điều này trong Ruby!
Tải xuống dữ liệu mẫu
Trước khi chúng ta có thể làm bẩn tay, chúng ta sẽ cần một số dữ liệu mẫu.
Nếu bạn không có bất kỳ công việc nào để làm việc, bạn có thể tải xuống một số bài viết trên Wikipedia hoặc blog. Trong trường hợp cụ thể này, tôi quyết định tải xuống một số nhật ký IRC từ kênh của #ruby freenode.
Có thể tìm thấy nhật ký tại đây :
irclog.whitequark.org/ruby
Lưu ý về định dạng dữ liệu :
Nếu không có phiên bản văn bản thuần túy của tài nguyên bạn muốn phân tích, thì bạn có thể sử dụng Nokogiri để phân tích cú pháp trang và trích xuất dữ liệu.
Nhật ký irc có sẵn ở dạng văn bản thuần túy bằng cách thêm .txt ở cuối URL, vì vậy chúng tôi sẽ tận dụng lợi thế đó.
Lớp này sẽ tải xuống và lưu dữ liệu cho chúng tôi:
require 'restclient'
class LogParser
LOG_DIR = 'irc_logs'
def initialize(date)
@date = date
@log_name = "#{LOG_DIR}/irc-log-#{@date}.txt"
end
def download_page(url)
return log_contents if File.exist? @log_name
RestClient.get(url).body
end
def save_page(page)
File.open(@log_name, "w+") { |f| f.puts page }
end
def log_contents
File.readlines(@log_name).join
end
def get_messages
page = download_page("https://irclog.whitequark.org/ruby/#{@date}.txt")
save_page(page)
page
end
end
log = LogParser.new("2015-04-15")
msg = log.get_messages
Đây là một lớp khá đơn giản.
Chúng tôi sử dụng RestClient làm ứng dụng khách HTTP của mình và sau đó chúng tôi lưu kết quả vào một tệp để chúng tôi không phải yêu cầu chúng nhiều lần trong khi thực hiện các sửa đổi đối với chương trình của mình.
Phân tích dữ liệu
Bây giờ chúng tôi có dữ liệu của mình, chúng tôi có thể phân tích nó.
Đây là một lớp Ngram đơn giản.
Trong lớp này, chúng tôi sử dụng phương thức Array # each_cons để tạo ra các ngrams.
Bởi vì phương thức này trả về một Enumerator chúng tôi cần gọi to_a trên đó để lấy Array .
class Ngram
def initialize(input)
@input = input
end
def ngrams(n)
@input.split.each_cons(n).to_a
end
end
Sau đó, chúng tôi kết hợp mọi thứ lại với nhau bằng cách sử dụng một vòng lặp, Hash#merge! &Enumerable#sort_by .
Như thế này :
# Filter words that appear less times than this
MIN_REPETITIONS = 20
total = {}
# Get the logs for the first 15 days of the month and return the bigrams
(1..15).each do |n|
day = '%02d' % [n]
total.merge!(get_trigrams_for_date "2015-04-#{day}") { |k, old, new| old + new }
end
# Sort in descending order
total = total.sort_by { |k, v| -v }.reject { |k, v| v < MIN_REPETITIONS }
total.each { |k, v| puts "#{v} => #{k}" }
Lưu ý:
get_trigrams_for_datephương thức không có ở đây cho ngắn gọn, nhưng bạn có thể tìm thấy nó trên github.
Đây là kết quả đầu ra trông như thế nào :
112 => i want to 83 => link for more 82 => is there a 71 => you want to 66 => i don't know 66 => i have a 65 => i need to
Như bạn có thể thấy muốn làm mọi thứ rất phổ biến trong #ruby 🙂
Kết luận
Bây giờ đến lượt bạn!
Crack mở trình chỉnh sửa của bạn và bắt đầu chơi với một số phân tích n-gram. Một cách khác để xem n-gram đang hoạt động là Google Ngram Viewer.
Xử lý ngôn ngữ tự nhiên (NLP) có thể là một chủ đề hấp dẫn, Wikipedia có một cái nhìn tổng quan về chủ đề này.
Bạn có thể tìm thấy mã hoàn chỉnh cho bài đăng này tại đây:https://github.com/matugm/ngram-analysis/blob/master/irc_histogram.rb