Trong blog về Dữ liệu lớn, chúng tôi đã thảo luận về Các lớp chức năng của Dữ liệu lớn và trong blog cuối cùng của tôi, tôi đã liệt kê 11 Công cụ lưu trữ dữ liệu đám mây hàng đầu. Bước tiếp theo sau khi lưu trữ là Quy trình làm sạch dữ liệu.
Khi chúng ta nói về Dữ liệu lớn, rõ ràng là dữ liệu đang gia tăng với tốc độ đáng báo động, cho dù đó là dữ liệu kinh doanh hay dữ liệu cá nhân. Nếu chúng ta đi theo sự thật thì mỗi ngày có 2,5 triệu tỷ byte dữ liệu được tạo ra trên thế giới. Dữ liệu này cũng có các bản ghi lặp lại và sai sót mà chúng tôi cần xóa trước khi khai thác để hiểu rõ hơn về nó. Dữ liệu không chính xác dẫn đến các giả định và phân tích sai, cuối cùng dẫn đến thất bại của dự án.
Xóa dữ liệu là tên của quá trình sửa chữa và loại bỏ (nếu cần) các bản ghi không chính xác khỏi một cơ sở dữ liệu cụ thể. Mục đích của việc làm sạch dữ liệu là phát hiện cái gọi là Dữ liệu bẩn để sửa đổi hoặc xóa nó nhằm đảm bảo rằng một tập hợp dữ liệu nhất định là chính xác và nhất quán với các tập hợp khác trong hệ thống.
Có nhiều công cụ làm sạch dữ liệu. Một công cụ làm sạch dữ liệu tốt giúp làm sạch cơ sở dữ liệu của bạn khỏi dữ liệu trùng lặp, mục nhập xấu và thông tin không chính xác. Các công cụ này có thể được chia thành các danh mục dưới đây tùy thuộc vào môi trường mà chúng được sử dụng:
- Công cụ làm sạch dữ liệu ngoại tuyến
- Công cụ làm sạch dữ liệu dựa trên đám mây
- Công cụ làm sạch dữ liệu cho Dữ liệu Salesforce.
Blog này sẽ giúp bạn làm quen với một số Công cụ làm sạch dữ liệu ngoại tuyến tốt.
1. con vịt
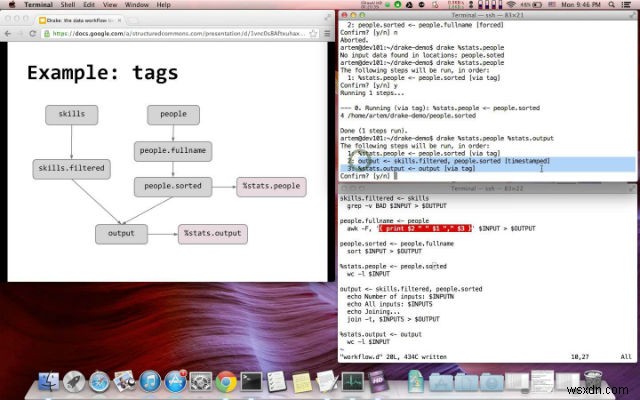
Drake là công cụ xử lý dữ liệu dựa trên văn bản, dễ sử dụng, có thể mở rộng, giúp tổ chức thực thi lệnh xung quanh dữ liệu và các thành phần phụ thuộc của nó. Các bước xử lý dữ liệu được xác định cùng với đầu vào và đầu ra của chúng. Nó tự động giải quyết các phụ thuộc và cung cấp một tập hợp các tùy chọn phong phú để kiểm soát quy trình làm việc. Nó hỗ trợ nhiều đầu vào và đầu ra, đồng thời có hỗ trợ HDFS tích hợp sẵn.
2. OpenRefine
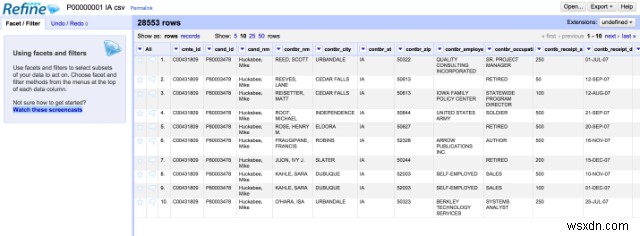
OpenRefine, trước đây được gọi là Google Refine, là một ứng dụng máy tính mạnh mã nguồn mở độc lập hoạt động với dữ liệu lộn xộn. Nó cung cấp tính năng sắp xếp dữ liệu, tức là dọn dẹp dữ liệu và chuyển đổi dữ liệu từ định dạng này sang định dạng khác. Nó tương tự như ứng dụng bảng tính, nhưng hoạt động giống cơ sở dữ liệu hơn.
Nó hoạt động trên dữ liệu tương tự như các bảng cơ sở dữ liệu quan hệ, tức là nó hoạt động trên các hàng dữ liệu có các ô bên dưới các cột. Một dự án OpenRefine là một bảng. Người dùng có thể thay đổi cách hiển thị các hàng bằng các tiêu chí lọc khác nhau. Tất cả các hành động được thực hiện trên một tập dữ liệu được lưu trữ trong một dự án và có thể được phát lại trên một tập dữ liệu khác.
3. Trifacta Wrangler
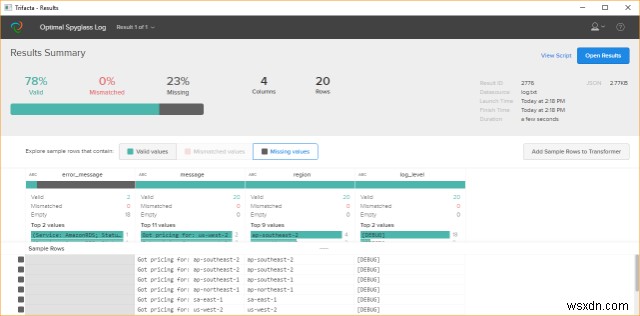
Công cụ này giúp chúng tôi trong quy trình Sắp xếp dữ liệu. Sắp xếp dữ liệu được định nghĩa một cách lỏng lẻo là quá trình chuyển đổi hoặc ánh xạ dữ liệu theo cách thủ công từ một dạng thô sang một định dạng khác cho phép sử dụng dữ liệu thuận tiện hơn với sự trợ giúp của các công cụ bán tự động.
Wrangler cải thiện đáng kể cách các tổ chức thu được giá trị từ dữ liệu đa dạng. Với trifecta wrangler, một cách tiếp cận mới đã được áp dụng cho cách các nhà phân tích làm cho dữ liệu trở nên hữu ích bằng cách tận dụng các kỹ thuật mới nhất trong trực quan hóa dữ liệu, học máy, tương tác giữa người và máy tính và xử lý dữ liệu. Họ có một mục đích đơn giản là dành ít thời gian hơn cho việc định dạng và nhiều thời gian hơn để phân tích dữ liệu. Nó cho phép chuyển đổi tương tác dữ liệu hỗn độn trong thế giới thực thành các bảng dữ liệu cho các công cụ phân tích.
4. Trình dọn dẹp dữ liệu
Trình dọn dẹp dữ liệu là ứng dụng phân tích chất lượng dữ liệu và là nền tảng giải pháp cho Giải pháp chất lượng dữ liệu. Cốt lõi của nó là một công cụ định hình mạnh mẽ, có thể mở rộng và do đó bổ sung thêm tính năng làm sạch, biến đổi, làm giàu, sao chép DE, đối sánh và hợp nhất dữ liệu. Một số tính năng của nó như sau:
- Tìm mẫu, giá trị còn thiếu, bộ ký tự và các đặc điểm khác của giá trị dữ liệu của bạn.
- Xóa chi tiết liên hệ của bạn bằng xác thực tên và địa chỉ.
- Phát hiện các bản sao bằng cách sử dụng logic mờ và các trọng số và ngưỡng có thể định cấu hình. Và cuối cùng là tạo một phiên bản duy nhất của nó.
- Xây dựng các quy tắc làm sạch của riêng bạn và tổng hợp chúng thành một số tình huống sử dụng và cơ sở dữ liệu đích.
5. Winpure Clean and Match
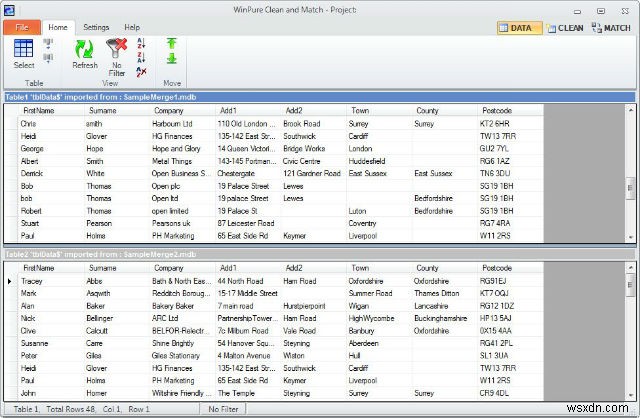
Kiểm soát Chất lượng Dữ liệu là yếu tố quan trọng nhất đằng sau thành công chung của một dự án hoặc chiến dịch. Đây là bộ làm sạch và so khớp dữ liệu, được thiết kế đặc biệt để tăng độ chính xác của dữ liệu doanh nghiệp hoặc người tiêu dùng. Đây là bộ phần mềm từng đoạt giải thưởng, lý tưởng để dọn dẹp, sửa chữa và sao chép danh sách gửi thư, cơ sở dữ liệu, bảng tính và CRM. Nó có thể được sử dụng cho các cơ sở dữ liệu như Access, Dbase, SQL Server, cũng như các bảng Excel và tệp Txt.
6. TIBCO rõ ràng
TIBCO Clarity là một công cụ chuẩn bị dữ liệu cung cấp cho bạn các dịch vụ phần mềm theo yêu cầu từ web dưới dạng Phần mềm dưới dạng dịch vụ. Nó có thể được sử dụng để khám phá, lập hồ sơ, làm sạch và chuẩn hóa dữ liệu thô được đối chiếu từ các nguồn khác nhau và cung cấp dữ liệu chất lượng tốt để phân tích chính xác và ra quyết định thông minh. Các tính năng của TIBCO Clarity để quản lý dữ liệu thô:
- Tích hợp liền mạch
- Khám phá dữ liệu và lập hồ sơ
- Khử trùng lặp
- Chuẩn hóa địa chỉ
- Chuyển đổi dữ liệu
7. Thang dữ liệu
Data Ladder Company là một công ty phần mềm đảm bảo chất lượng dữ liệu, với mục tiêu giúp người dùng doanh nghiệp khai thác tối đa dữ liệu của họ thông qua các công cụ đối sánh, lập hồ sơ, loại bỏ trùng lặp và bổ sung dữ liệu . Bộ Data Match Enterprise là một ứng dụng làm sạch dữ liệu trên máy tính để bàn có tính trực quan cao được thiết kế đặc biệt để giải quyết các vấn đề về chất lượng dữ liệu của khách hàng và liên hệ. Data Match Enterprise bao gồm nhiều thuật toán tiêu chuẩn và độc quyền để phát hiện các biến thể ngữ âm, mờ, viết sai và viết tắt
Phần mềm chống trùng lặp dữ liệu cung cấp một giải pháp hoàn chỉnh cho chất lượng dữ liệu, phần mềm làm sạch, so khớp và loại bỏ trùng lặp trong một bộ phần mềm dễ sử dụng.
8. Ngôi sao DQ Pro
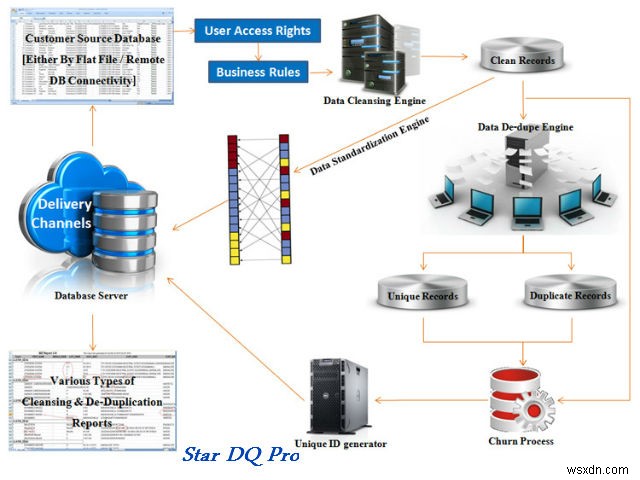
Đảm bảo dữ liệu của bạn chính xác, chân thực và cập nhật. Nó giải quyết các yêu cầu chính về chất lượng dữ liệu như độ chính xác, tính đầy đủ, tính nhất quán, mốc thời gian, tính duy nhất và tính hợp lệ. Các tính năng do nó cung cấp là
- Làm sạch – xác định loại lỗi, tạo nhật ký dữ liệu không sạch kèm theo nhận xét.
- Khử trùng lặp – nhóm và phân cụm, xác định các thông tin sai lệch, liên tục loại bỏ trùng lặp.
- Giám sát – nhật ký giao dịch, cảnh báo trạng thái xử lý qua thư/SMS, xác thực người dùng.
Làm sạch dữ liệu đặc biệt quan trọng khi một lượng lớn dữ liệu được lưu trữ. Sau đó, mục tiêu của hành động khắc phục đối với dữ liệu bẩn là làm cho mọi lỗi trở nên nhỏ nhất có thể. Trừ khi việc làm sạch dữ liệu được thực hiện thường xuyên, các lỗi có thể tích tụ và dẫn đến giảm hiệu quả công việc. Trong blog tiếp theo về Dữ liệu lớn, tôi sẽ liệt kê công cụ làm sạch dữ liệu dựa trên đám mây và các công cụ cho cơ sở dữ liệu Salesforce.