Redis được phát triển rất chú trọng vào hiệu suất. Chúng tôi cố gắng hết sức với mọi bản phát hành để đảm bảo bạn sẽ trải nghiệm một sản phẩm rất ổn định và nhanh chóng.
Tuy nhiên, nếu bạn đang tìm thấy chỗ để cải thiện hiệu quả của Redis hoặc đang theo đuổi điều tra hồi quy hiệu suất, bạn sẽ cần một cách theo dõi và phân tích hiệu suất của Redis có phương pháp ngắn gọn. Đây là câu chuyện về một trong những cách tối ưu hóa đó.
Cuối cùng, chúng tôi đã cải thiện hiệu suất nhập của luồng lên khoảng 20%, một cải tiến mà bạn có thể tận dụng trên Redis v7.0.
Một đặc điểm kỹ thuật tiêu chuẩn
Trước khi bắt đầu tối ưu hóa, chúng tôi muốn cung cấp cho bạn ý tưởng cấp cao về cách chúng tôi đạt được nó.
Như đã nêu trước đây, chúng tôi muốn xác định các hồi quy hiệu suất của Redis và / hoặc các cải tiến hiệu suất tiềm năng trên CPU. Để làm như vậy, chúng tôi thấy cần phải thúc đẩy một bộ tiêu chuẩn giữa các công ty và cộng đồng về tất cả các vấn đề liên quan đến các yêu cầu và kỳ vọng về hiệu suất và khả năng quan sát.
Tóm lại, chúng tôi liên tục chạy các điểm chuẩn của SPEC bằng cách chia nhỏ chúng theo nhánh / thẻ và diễn giải dữ liệu hiệu suất kết quả bao gồm đầu ra của công cụ / chuyên gia lập hồ sơ và đầu ra của khách hàng ở chế độ hoàn toàn tự động “không chạm”.
Các công cụ được sử dụng đều là mã nguồn mở và dựa trên các công cụ / khuôn khổ phổ biến như memtier_benchmark, redis-benchmark, Linux perf_events, công cụ theo dõi bcc / BPF và kho lưu trữ FlameGraph của Brendan Greg.
Nếu bạn muốn biết thêm thông tin chi tiết về cách chúng tôi sử dụng trình tiểu sử với Redis, chúng tôi khuyên bạn nên xem qua “ cực kỳ chi tiết của chúng tôi Hướng dẫn kỹ thuật hiệu suất để lập hồ sơ và theo dõi trên CPU . ”
Tránh tính toán trùng lặp để cải thiện hiệu suất
Ngay sau khi bước đầu tiên này được đưa ra, chúng tôi đã bắt đầu diễn giải các công cụ lập hồ sơ / đầu ra của chuyên gia. Một trong những điểm chuẩn thể hiện một mô hình thú vị là điểm chuẩn đã nhập của Luồng, chỉ cần nhập dữ liệu vào một luồng bằng lệnh tương tự như lệnh bên dưới:
`XADD key * field value`.
Chúng tôi đã quan sát thấy rằng khi thêm vào một luồng mà không có ID, nó sẽ tạo ra công việc trùng lặp về tạo / giải phóng / sdslen SDS, tiêu tốn khoảng 10% chu kỳ CPU, như được trình bày chi tiết trong hai bản in báo cáo hoàn thiện tiếp theo.
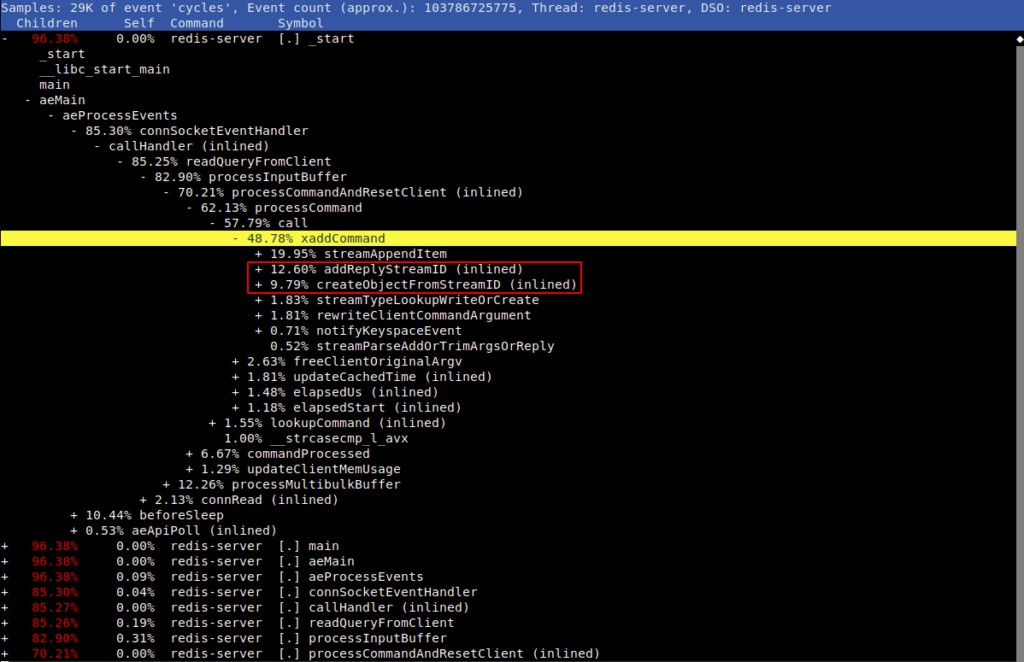
Đối với các đầu vào giống nhau, sdscatfmt và _sdsnewlen đã được gọi hai lần:

Điều này cho phép chúng tôi tối ưu hóa quá trình nhập Luồng trong khoảng 9-10% như đã xác nhận sau kết quả điểm chuẩn:
Đường cơ sở về nhánh không ổn định ( 6b403f5 ):
Cam kết đầu tiên về PR này (tránh công việc trùng lặp):

Tránh phân bổ trùng lặp để cải thiện hiệu suất
Trọng tâm ban đầu của việc cải thiện ca sử dụng này dẫn đến phân tích sâu hơn từ Oran (một trong những thành viên cốt lõi của nhóm) nhận thấy có một sự lãng phí khác về chu kỳ CPU. Lần này, đó là do quản lý bộ nhớ không tối ưu trong cùng một khối mã. Chúng tôi đã phân bổ một SDS trống và sau đó phân bổ lại nó. Giảm số lượng cuộc gọi sẽ cung cấp cho chúng tôi một cải tiến tốc độ khác, như được hiển thị bên dưới.
Cam kết thứ hai (tránh reallocs):

Cải tiến được đo lường
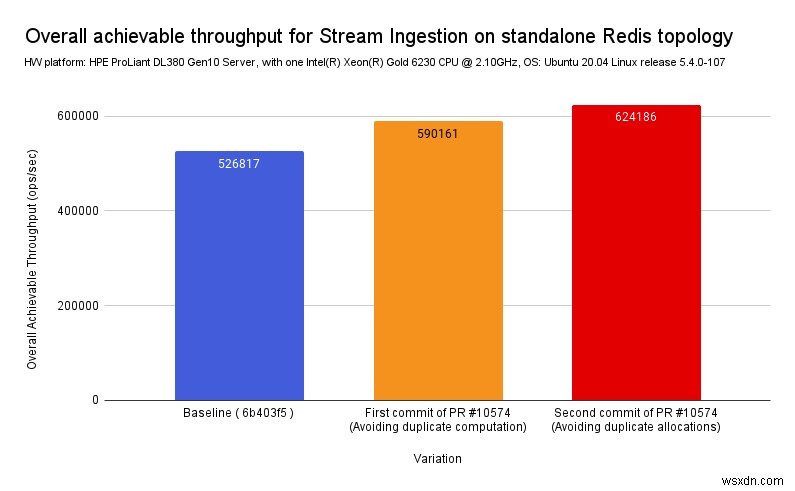
Như mong đợi, bằng cách chỉ sử dụng lại tính toán trung gian và do đó giảm tính toán và phân bổ dư thừa trong các chức năng được gọi nội bộ, chúng tôi đã đo được mức giảm thời gian tổng thể của CPU là ~ =20% của Redis Streams.
Chúng tôi tin rằng đây là một ví dụ về cách những cải tiến đơn giản có phương pháp có thể dẫn đến những thay đổi đáng kể trong hiệu suất, ngay cả đối với mã đã được tối ưu hóa sâu như Redis.
Mục tiêu của chúng tôi là mở rộng khả năng hiển thị hiệu suất của Redis và các thành viên từ cả ngành và học viện, bao gồm các tổ chức và cá nhân, được khuyến khích đóng góp. Nếu chúng tôi không đo lường nó, chúng tôi không thể cải thiện nó.