Trí tuệ nhân tạo đã phát triển qua nhiều năm và Facebook đã tích hợp các khái niệm và phát triển AI vào nhiều tính năng của mình, bao gồm cả máy ảnh và phân tích nguồn cấp tin tức. Trí tuệ nhân tạo được cho là giúp cuộc sống của mọi người dễ dàng hơn bằng cách tối ưu hóa việc sử dụng tài nguyên và đơn giản hóa trải nghiệm của họ. Trong phương tiện truyền thông xã hội, AI đã được sử dụng để giới thiệu cho người dùng một phương tiện giao tiếp và tương tác thế hệ tiếp theo, do đó, giúp họ kết nối với những người thân yêu của mình một cách thông minh. Nhưng một lần nữa, AI của Facebook đã thất bại thảm hại trong việc lọc nguồn cấp tin tức, bảo vệ quyền riêng tư của người dùng và đã vi phạm đạo đức khi để ngôn từ kích động thù địch lan truyền tự do trên nền tảng truyền thông xã hội lớn nhất thế giới. Vào Ngày thứ 2 của Sự kiện phát biểu quan trọng F8 của Facebook, trí tuệ nhân tạo và bảo mật trí tuệ nhân tạo bao trùm phần lớn sự kiện, do Giám đốc công nghệ Facebook Mike Schroepfer dẫn đầu. Hãy cùng xem Facebook dự định làm gì với AI trong tương lai.
Trí tuệ nhân tạo tại Facebook

Công dụng cốt lõi của Trí tuệ nhân tạo của Facebook là kiểm tra nguồn cấp tin tức. Công nghệ AI được sử dụng để đảm bảo rằng mọi nội dung thể hiện ngôn từ kích động thù địch, bạo lực, phân biệt chủng tộc, thông tin chính trị và bất kỳ nội dung nào khác vi phạm các giá trị của Facebook cũng như luật pháp trên toàn cầu. AI cũng được sử dụng để đọc các tìm kiếm, tùy chọn và cập nhật của người dùng, cho phép Facebook thu hút người dùng bằng loại quảng cáo phù hợp và lọc các đề xuất kết bạn cũng như bài đăng được tài trợ để thêm vào nguồn cấp dữ liệu của họ. Đây là thứ hỗ trợ mô hình kinh doanh của Facebook.
Cách Facebook sử dụng AI

Facebook đã và đang sử dụng Xử lý ngôn ngữ tự nhiên (NLP) nâng cao để đào tạo AI của mình và giúp nó hiểu được sự khác biệt giữa các loại nội dung khác nhau ở tất cả các loại định dạng. NLP sử dụng tính năng nhúng đa ngôn ngữ cho phép AI hiểu nội dung bằng các ngôn ngữ khác nhau và xóa nội dung có hại khỏi Bảng tin trên toàn cầu.
Khó khăn

Mặc dù có khả năng nhúng đa ngôn ngữ nhưng Facebook AI rất khó nắm bắt được tất cả nội dung. Có hơn sáu nghìn ngôn ngữ trên thế giới được viết và nói bởi những người có nguồn gốc dân tộc gần như bằng nhau. Việc đào tạo AI với lượng kiến thức hiểu ngôn ngữ rộng lớn như vậy là rất khó. Trí tuệ nhân tạo được Facebook sử dụng học hỏi từ dữ liệu được dán nhãn được tải lên hệ thống và học hỏi từ dữ liệu đó. Dữ liệu có số lượng lớn và việc gắn nhãn dữ liệu để đào tạo AI hiệu quả là một nhiệm vụ khó khăn đối với các nhà phát triển. Và lượng dữ liệu càng lớn thì khả năng xảy ra lỗi của con người càng nhiều.
Tìm hiểu các dạng dữ liệu ảnh và video là một vấn đề đau đầu khác

Facebook đã phát triển rộng rãi khi hiểu về ảnh, đặc biệt là sau khi mua lại Instagram. Facebook đã nhúng các khái niệm về Thị giác máy tính và Mạng kim tự tháp tính năng toàn cảnh (Panoptic FPN) để hiểu kiến trúc của tất cả các khía cạnh của hình ảnh. Panoptic FPN thậm chí đã phát triển để hiểu bất kỳ cấu trúc hình ảnh nào cùng với nền hình ảnh, giúp AI của Facebook thậm chí có nhiều khả năng hơn trong việc lọc nội dung độc hại có sẵn trên web dưới dạng hình ảnh.
Nhưng việc hiểu nội dung video là một nhược điểm lớn đối với AI của Facebook và việc học máy của nó đã thất bại ở nhiều cấp độ khi tránh ngôn từ kích động thù địch và bạo lực thông qua các video được tải lên và chia sẻ trên Facebook. Mặc dù Facebook tuyên bố rằng họ đã cố gắng sử dụng thẻ bắt đầu bằng # làm nhãn dữ liệu để giúp AI học hỏi từ nội dung video hoặc ít nhất là xác định mức độ liên quan của dữ liệu từ thông tin do thẻ bắt đầu bằng # cung cấp; tuy nhiên, nó vẫn chưa được đánh dấu.
Trí tuệ nhân tạo của Facebook thất bại ở đâu?

Trí tuệ nhân tạo của Facebook chạy trên Học có giám sát framework, theo đó AI học hỏi từ các bộ dữ liệu được các nhà phát triển con người gắn nhãn. Trong vài năm gần đây, dân số trên Facebook đã gần đạt tới một phần ba tổng dân số trên hành tinh. Điều này có nghĩa là lượng dữ liệu dư thừa ở định dạng văn bản, âm thanh và video được tải lên Facebook trong một phần giây. Trong khi đó, AI có nhiệm vụ đánh giá nội dung này theo thời gian thực. Vì có sự tham gia của con người nên việc nghiên cứu kỹ lưỡng cũng có thể dẫn đến độ trễ trong việc ghi nhãn dữ liệu hoặc sai sót trong bộ dữ liệu do AI đọc. Điều này có thể dẫn đến lỗi phát hiện nội dung và AI có thể không hoạt động theo cách giống nhau đối với tất cả nội dung người dùng tải lên Bảng tin.
AI tự giám sát:Kế hoạch dự phòng của Facebook để xóa nội dung có hại
Vào ngày thứ 2 của F8 2019, CTO Mike Schroepfer đã thông báo rằng Facebook đang dẫn dắt các nhà nghiên cứu và nhà phát triển thiết kế các hệ thống hỗ trợ học tập tự giám sát. Một hệ thống AI như vậy sẽ có thể hiểu thông tin mà không cần bộ dữ liệu và ghi nhãn, do đó làm cho nó trở nên tự tin và tự nhận thức. AI tự giám sát có thể được cung cấp khối lượng dữ liệu khổng lồ. Tuy nhiên, không nhất thiết toàn bộ dữ liệu phải ở dạng thô và sẽ được cung cấp như hiện tại. Để thiết kế các mô-đun đào tạo cho các máy AI, người dùng cần phải loại bỏ một số bit thông tin khỏi nội dung hoặc dữ liệu và sau đó để máy tự nhận ra các bit còn thiếu. Loại hình đào tạo này sẽ cho phép cỗ máy tăng mức độ liên quan của nội dung đang diễn ra trên Facebook và sẽ cho phép cỗ máy xem xét kỹ lưỡng nội dung đó trước các chính sách và luật pháp theo cách tốt hơn.
Đào tạo toàn diện về AI:Làm cho hoạt động kinh doanh AR của Facebook trở nên đạo đức và an toàn hơn
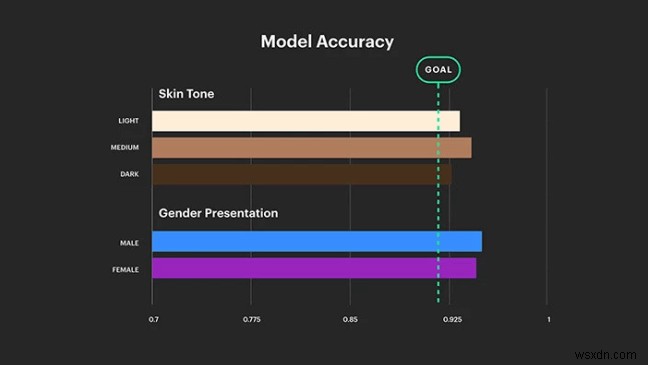
Với Portal và Spark AR, Facebook lên kế hoạch cho các dự án lớn trong lĩnh vực kinh doanh công nghệ AR và VR. Tuy nhiên, công nghệ thông minh yêu cầu AI thông minh để mang lại trải nghiệm thịnh vượng cho người dùng. Portal Camera được thiết kế dựa trên các khái niệm thực tế tăng cường và là chìa khóa để giới thiệu các nền tảng trò chuyện video thông minh và nhận dạng khuôn mặt thế hệ tiếp theo. Tuy nhiên, người ta phát hiện ra rằng những máy ảnh và tai nghe AR/VR này đã thiên vị trong việc hiểu mệnh lệnh từ mọi người. Các ống kính đã được tìm thấy để phân biệt giữa tông màu da và giới tính trong khi không cung cấp trải nghiệm người dùng tương tự cho tất cả người dùng. Thêm vào đó, điều này khuyến khích phân biệt chủng tộc và giới tính. Sau tất cả những lời chỉ trích trên toàn cầu, đây là điều cuối cùng mà Facebook muốn.

Vì vậy, Facebook đã thông báo rằng họ sẽ xây dựng một AI toàn diện để loại bỏ vấn đề này. Đối với điều này, họ có người Mỹ gốc Nigeria, Lade Obamehinti đứng đầu bộ phận chiến lược của bộ phận AR/VR của Facebook. Các nhà nghiên cứu sẽ thử nghiệm máy ảnh AI ở các cài đặt ánh sáng khác nhau với những người có tông màu da khác nhau, để đảm bảo rằng AI có tính toàn diện được nhúng trong các mô-đun học tập của nó mà không có bất kỳ lỗi hoặc dao động nào.
Tại sao Facebook cần hoạt động trên AI?

Facebook để dữ liệu của mọi người bị lạm dụng và dữ liệu đó đã được bán cho các nhà tiếp thị và nhà quảng cáo ngay dưới mũi quan chức của mình. Sau đó, Facebook bị đột biến quyền lực và nó cũng có mật khẩu của hàng triệu người dùng bị lộ dưới dạng văn bản thuần túy. Và sau đó, mức độ kém cỏi của AI và sự thiếu hiểu biết của các nhà phát triển đã vượt quá khi một người đàn ông ở Christchurch, NZ phát trực tiếp một video trên Facebook khi anh ta bắn chết nhiều người trong nhà thờ Hồi giáo nhiều lần. Video đã được phát trực tuyến và nó nằm trong nguồn cấp tin tức FB trong một khoảng thời gian đủ để cho phép mọi người tải xuống.
Facebook đã phải chịu rất nhiều phản ứng dữ dội và đã mất hàng tỷ đô la trong quá trình này. Đây là lý do mà Mark Zuckerberg đã sử dụng từ “riêng tư” hàng triệu lần vào Ngày đầu tiên của Sự kiện F8 năm nay. Facebook đã mất đòn bẩy và đã vượt qua giới hạn kiên nhẫn của cả người dùng và các nhà hoạch định chính sách trên toàn cầu. Nếu Facebook không làm cho trí tuệ nhân tạo của mình hiểu được nội dung, nó có thể phải ngừng hoạt động trong những năm tới.
Có lẽ, đó là lý do duy nhất mà Facebook có CTO của mình trên sân khấu cả ngày, đảm bảo với người dùng bằng cách cho họ biết Facebook đang cố gắng làm gì để bảo vệ họ bằng mọi cách.
Liệu bước đi này có thành công không?

Zuckerberg tự nhận rằng những thay đổi này sẽ không xảy ra trong một sớm một chiều. Facebook có thể phải thay đổi mô hình kinh doanh của mình để loại bỏ hoàn toàn các lỗ hổng trong AI và xóa vĩnh viễn nội dung thù địch khỏi Facebook. Nghiên cứu đang được tiến hành và việc phát triển các mô-đun đào tạo như vậy đang ở giai đoạn đầu. Tuy nhiên, có một điều có thể nói là Facebook đã bắt đầu coi trọng những vấn đề như vậy. Và nếu nó được ưu tiên, công ty có thể thực hiện được những lời hứa mà các quan chức của họ đã đưa ra trong F8 năm nay.
Đã đến lúc Facebook đưa ra công nghệ mới và các mô-đun đào tạo AI tốt hơn để hiểu nội dung trên FB. Đặc biệt là người dùng trên Facebook cũng như các nền tảng và sản phẩm thuộc sở hữu hoàn toàn khác có xu hướng tăng lên từng ngày. Vì Facebook đã trở thành một cổng thông tin quảng cáo và gây ảnh hưởng cùng với dịch vụ trò chuyện và liên lạc, nên dữ liệu trên các máy chủ của nó đã vượt quá giới hạn phân loại và ghi nhãn dữ liệu. Liệu những động thái này của Facebook Inc. có giúp ích gì cho công ty hay không? Câu trả lời cho điều này có thể không quá đơn giản. Cho đến lúc đó, điều chúng ta có thể làm là chờ xem ông Zuckerberg thực hiện lời nói của mình như thế nào.