Chạy một truy vấn SQL Redis không phải là điều khó khăn. Tôi thực sự đã nêu ra quan điểm này cách đây vài năm khi nói chuyện với một người bạn quản lý các giải pháp lưu trữ dữ liệu tại một công ty bán lẻ. Chúng tôi bắt đầu nói về các truy vấn của Redis sau khi anh ấy giải thích một vấn đề mà anh ấy đang gặp phải.
“ Chúng tôi gặp khó khăn với các giải pháp lưu trữ dữ liệu của mình. Chúng tôi có các trường hợp sử dụng mà chúng tôi cần ghi lại dữ liệu và thực hiện các hoạt động phân tích trong thời gian thực. Tuy nhiên, đôi khi phải mất vài phút để có được kết quả. Redis có thể giúp gì ở đây không? Hãy nhớ rằng chúng tôi không thể tách và thay thế tất cả giải pháp dựa trên SQL của chúng tôi cùng một lúc. Chúng ta chỉ có thể tiến một bước nhỏ tại một thời điểm. ”
Bây giờ, nếu bạn đang ở trong hoàn cảnh giống như bạn của tôi, chúng tôi có tin tốt cho bạn. Có một số cách bạn có thể chạy truy vấn Redis và giới thiệu Redis vào kiến trúc của bạn mà không có làm gián đoạn giải pháp dựa trên SQL hiện tại của bạn.
Hãy khám phá cách bạn có thể làm điều này. Nhưng trước khi đi xa hơn, chúng tôi có một thí sinh Redis Hackathon đã tạo ứng dụng của riêng mình cho phép bạn truy vấn dữ liệu trong Redis bằng SQL.
Xem video bên dưới.
Sửa lại bảng của bạn dưới dạng cấu trúc dữ liệu Redis
Việc ánh xạ bảng của bạn tới các cấu trúc dữ liệu của Redis khá đơn giản. Các cấu trúc dữ liệu hữu ích nhất cần tuân theo là:
- Băm
- Nhóm đã sắp xếp
- Đặt
Một cách bạn có thể thực hiện là lưu trữ mọi hàng dưới dạng Hash với một khóa dựa trên khóa chính của bảng và lưu trữ khóa trong Tập hợp hoặc Tập hợp đã sắp xếp.
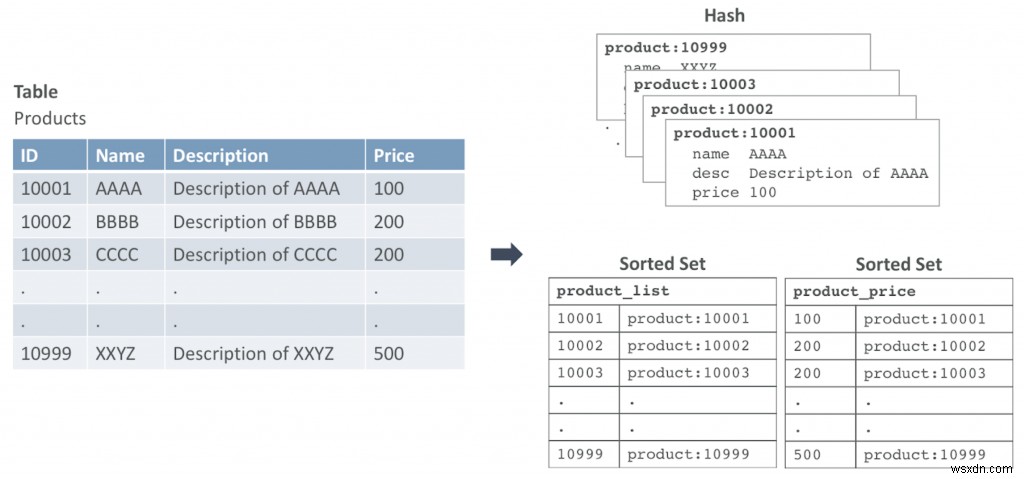
Hình 1 cho thấy một ví dụ về cách bạn có thể ánh xạ một bảng vào các cấu trúc dữ liệu Redis. Trong ví dụ này, chúng ta có một bảng được gọi là Sản phẩm. Mọi hàng được ánh xạ tới cấu trúc dữ liệu băm.
Hàng có id chính, 10001 sẽ được chuyển thành Hash với khóa:product:10001. Chúng tôi có hai Tập hợp được sắp xếp trong ví dụ này:tập hợp đầu tiên lặp lại qua tập dữ liệu theo khóa chính và tập hợp thứ hai để truy vấn dựa trên giá.
Với tùy chọn này, bạn cần thực hiện các thay đổi đối với mã của mình để sử dụng các truy vấn Redis thay vì các lệnh SQL. Dưới đây là một số ví dụ về các lệnh tương đương của SQL và Redis:
A. Chèn dữ liệu
SQL: insert into Products (id, name, description, price) values = (10200, “ZXYW”,“Description for ZXYW”, 300);
Redis: MULTI HMSET product:10200 name ZXYW desc “Description for ZXYW” price 300 ZADD product_list 10200 product:10200 ZADD product_price 300 product:10200 EXEC
B. Truy vấn theo id sản phẩm
SQL: select * from Products where id = 10200
Redis: HGETALL product:10200
C. Truy vấn theo giá
SQL: select * from Product where price < 300
Redis: ZRANGEBYSCORE product_price 0 300
Thao tác này trả về các khóa:product:10001, product:10002, product:10003. Bây giờ chạy HGETALL cho mỗi khóa.
HGETALL product:10001 HGETALL product:10002 HGETALL product:10003
Sử dụng DataFrames để tự động ánh xạ bảng của bạn với cấu trúc dữ liệu Redis
Bây giờ, nếu bạn muốn duy trì giao diện SQL trong các giải pháp của mình và chỉ thay đổi kho dữ liệu cơ bản thành Redis để làm cho nó nhanh hơn, thì bạn có thể làm như vậy bằng cách sử dụng Apache Spark và thư viện Spark-Redis.
Thư viện Spark-Redis cho phép bạn sử dụng API DataFrame để lưu trữ và truy cập dữ liệu Redis. Nói cách khác, bạn có thể chèn, cập nhật và truy vấn dữ liệu bằng các lệnh SQL, nhưng dữ liệu được ánh xạ nội bộ tới cấu trúc dữ liệu Redis.
Đầu tiên, bạn cần tải xuống spark-redis và xây dựng thư viện để lấy tệp jar. Ví dụ:với spark-redis 2.3.1, bạn nhận được spark-redis-2.3.1-SNAPSHOT-jar-with- dependencies.jar.
Tiếp theo, bạn phải đảm bảo rằng bạn có phiên bản Redis của mình đang chạy. Trong ví dụ của chúng tôi, chúng tôi sẽ chạy Redis trên máy chủ cục bộ và cổng mặc định 6379.
Bạn cũng có thể chạy các truy vấn của mình trên Apache Spark engine. Dưới đây là một ví dụ về cách bạn có thể làm điều này:
$ spark-shell --jars spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession
.builder()
.appName("redis-sql")
.master("local[*]")
.config("spark.redis.host","localhost")
.config("spark.redis.port","6379").getOrCreate()
scala> import spark.sql
scala> import spark.implicits._
scala> sql("create table if not exists products(id string, name string, description string, price int) using org.apache.spark.sql.redis options (table 'product')")
scala> sql("insert into products values = ('10200','ZXYW','Description of ZXYW', 300)")
scala> val results = sql("select * from products")
scala> results.show()
+-----+----+-------------------+-----+
| id|name| description|price|
+-----+----+-------------------+-----+
|10200|ZXYW|Description of ZXYW| 300|
+-----+----+-------------------+-----+ Giờ đây, bạn cũng có thể sử dụng ứng dụng Redis của mình để truy cập dữ liệu này dưới dạng cấu trúc dữ liệu Redis:
127.0.0.1:6379> keys product* 1) "product:2e3f8611dbe94a588706a2aaea547caa"
Một cách tiếp cận hiệu quả hơn sẽ là sử dụng lệnh quét vì nó cho phép bạn phân trang khi bạn điều hướng qua dữ liệu.
127.0.0.1:6379> scan 0 match product* 1) "3" 2) 1) "product:2e3f8611dbe94a588706a2aaea547caa" 127.0.0.1:6379> hgetall product:2e3f8611dbe94a588706a2aaea547caa 1) "name" 2) "ZXYW" 3) "price" 4) "300" 5) "description" 6) "Description of ZXYW" 7) "id" 8) "10200"
Và chúng tôi đã có nó - hai cách đơn giản để bạn có thể chạy truy vấn SQL Redis mà không bị gián đoạn. Đi thêm một bước nữa, bạn có thể muốn tìm hiểu Tại sao Máy chủ SQL của Bạn cần Redis trong sách trắng mới của chúng tôi.
Nhưng liên quan đến dữ liệu thời gian thực với Redis, đây chỉ là một trong nhiều cách bạn có thể sử dụng để cung cấp trải nghiệm thời gian thực.
Nếu bạn muốn khám phá cách Redis có thể đảm bảo cho bạn truyền dữ liệu theo thời gian thực, hãy liên hệ với chúng tôi.