Hôm nay, chúng tôi rất vui mừng thông báo về tính khả dụng chung của RediSearch 2.0, mang đến công cụ tìm kiếm toàn văn, lập chỉ mục và truy vấn mạnh mẽ của nó cho tất cả người dùng Redis. Trong bản xem trước công khai kể từ tháng 9 năm 2020, RediSearch 2.0 đã thu hút được một danh sách ngày càng tăng những khách hàng dựa vào nó trong vô số trường hợp sử dụng, từ tạo các ứng dụng hiện đại đến tìm kiếm toàn văn cho đến phân tích thời gian thực. RediSearch 2.0 giới thiệu một kiến trúc hoàn toàn mới giúp nó nhanh hơn gấp đôi so với RediSearch 1.6 và RediSearch hiện hỗ trợ phân phối địa lý Active-Active của Redis và Redis trên Flash.
Tại sao RediSearch lại quan trọng
Các tổ chức hiện đại đang nắm bắt một lượng lớn dữ liệu có cấu trúc và phi cấu trúc. Tuy nhiên, quá thường xuyên, dữ liệu này bị khóa trong cơ sở dữ liệu chậm, dựa trên đĩa không hỗ trợ trải nghiệm thời gian thực cho các ứng dụng hiện đại. RediSearch loại bỏ những tắc nghẽn hiệu suất này bằng cách cho phép người dùng dễ dàng lập chỉ mục bộ dữ liệu Redis của họ, sau đó truy vấn và tổng hợp dữ liệu theo cách được phân phối đầy đủ trong thời gian thực, với tốc độ của Redis.
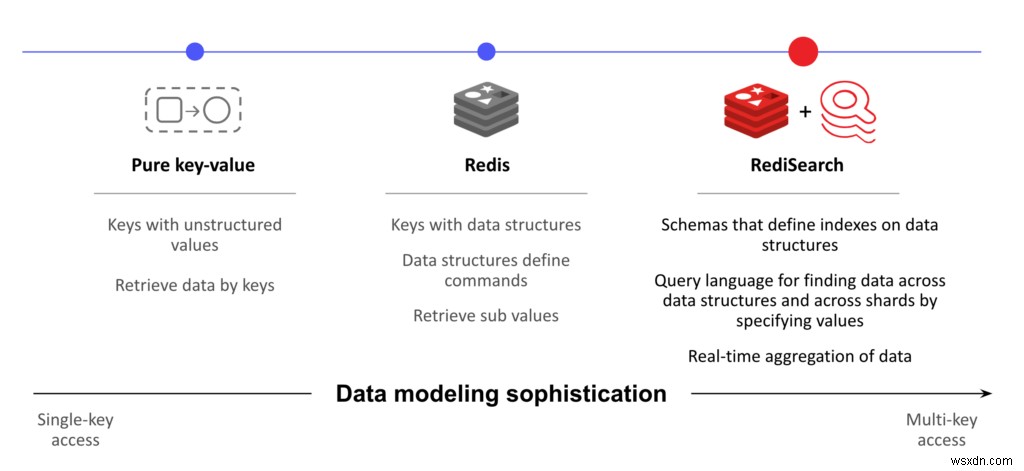
Như được minh họa trong sơ đồ trên, RediSearch mang lại mô hình dữ liệu phức tạp hơn cho Redis bằng cách cung cấp một số chiến lược lập chỉ mục cho phần giá trị của khóa, bao gồm toàn văn bản, vị trí địa lý, số và thẻ. Nếu không có chỉ mục, Redis phải thực hiện thao tác QUÉT cho mọi truy vấn, điều này có thể cực kỳ chậm và kém hiệu quả. Và việc tạo và duy trì các chỉ mục này theo cách thủ công rất phức tạp và dễ xảy ra lỗi. RediSearch duy trì các chỉ mục này cho người dùng và cho phép bạn truy vấn trên các cấu trúc dữ liệu trong cơ sở dữ liệu được phân nhóm.
Việc bổ sung RediSearch vào ngăn xếp công nghệ của bạn sẽ đơn giản hóa cơ sở hạ tầng dữ liệu, mở rộng các ứng dụng với trải nghiệm tìm kiếm phong phú và mở ra sức mạnh của phân tích trong Redis. Các nhà phát triển không còn cần phải chuyển đổi qua lại giữa nhiều công nghệ, ngôn ngữ truy vấn, mô hình dữ liệu và công cụ tìm kiếm bắt kịp để tạo ra các ứng dụng hiện đại.
Sử dụng RediSearch
Được viết bằng C, RediSearch được xây dựng có lưu ý đến hiệu suất bằng cách sử dụng các cấu trúc dữ liệu trong bộ nhớ như Trie và tận dụng các thuật toán truy vấn và lập chỉ mục phân tán hiện đại. Điều này làm cho nó nhanh hơn gấp 5 - 10 lần so với các công cụ tìm kiếm hiện có (để biết thêm về tốc độ của RediSearch, hãy xem Đo điểm chuẩn tìm kiếm:RediSearch so với Elasticsearch). Truy vấn dữ liệu và lập chỉ mục có độ trễ thấp của RediSearch làm cho nó phù hợp với các tập dữ liệu được cập nhật thường xuyên. Và RediSearch 2.0 mới nhanh hơn 2,4 lần so với phiên bản trước.
RediSearch cho phép bạn nhanh chóng tạo chỉ mục trên tập dữ liệu ở nhiều kiểu dữ liệu trong Redis. (Hàm băm hiện đang được hỗ trợ và chúng tôi dự định sẽ sớm phát hành hỗ trợ cho JSON, sau đó là Luồng.) RediSearch sử dụng phương pháp lập chỉ mục gia tăng để tạo và xóa chỉ mục nhẹ. Ngôn ngữ truy vấn phong phú của nó cho phép bạn truy vấn dữ liệu của mình với tốc độ cực nhanh, thực hiện các tổng hợp phức tạp và lọc theo thuộc tính, phạm vi số và khoảng cách địa lý.
RediSearch hỗ trợ lập chỉ mục toàn văn bản và mở rộng truy vấn dựa trên gốc ở nhiều ngôn ngữ, bao gồm tiếng Trung, tiếng Tây Ban Nha, tiếng Nga, tiếng Pháp, tiếng Đức và nhiều ngôn ngữ khác. Hơn nữa, bạn có thể làm phong phú thêm trải nghiệm tìm kiếm của người dùng bằng cách triển khai các đề xuất tự động hoàn thành bằng công nghệ tìm kiếm 'mờ'.
Bản phát hành mới nhất này cũng giúp RediSearch dễ dàng mở rộng quy mô hơn bao giờ hết. Với RediSearch 2.0, khách hàng hiện có thể nhanh chóng truy vấn và lập chỉ mục hàng tỷ tài liệu trên hàng trăm máy chủ. Và với sự hỗ trợ cho Redis trên Flash, điều đó có thể được thực hiện theo cách tiết kiệm chi phí hơn bao giờ hết. RediSearch cũng có thể được triển khai theo cách phân phối trên toàn cầu bằng cách tận dụng công nghệ Active-Active của Redis Enterprise để cung cấp tính khả dụng năm nines (99,999%) trên nhiều bản sao được phân phối theo địa lý, cho phép hoạt động đọc (như truy vấn và tổng hợp) và hoạt động ghi (ví dụ:lập chỉ mục) được thực thi với tốc độ triển khai RediSearch cục bộ mà không phải lo lắng về việc giải quyết xung đột ..
Tìm kiếm lại trong thế giới thực
Bật lập chỉ mục, truy vấn và tìm kiếm toàn văn trên các loại dữ liệu và cấu trúc dữ liệu khác nhau là điều cần thiết để giúp người dùng khai thác sức mạnh của dữ liệu của họ. Khả năng của RediSearch để chạy các truy vấn này theo cách được phân phối đầy đủ mà không có giới hạn về tỷ lệ và ở độ trễ dưới mili giây thực sự là một yếu tố thay đổi cuộc chơi.
Khách hàng của chúng tôi đang sử dụng RediSearch để không chỉ tăng tốc các ứng dụng cũ của họ mà còn để tạo các ứng dụng thời gian thực thế hệ tiếp theo của họ. GoMechanic, chẳng hạn, sử dụng RediSearch để tìm kiếm trên cơ sở dữ liệu gồm 10 triệu phụ tùng thay thế (để biết thêm, hãy xem thông cáo báo chí RediSearch 2.0). Nhiều ứng dụng thương mại điện tử đang sử dụng RediSearch để cung cấp tìm kiếm tương tác trên hàng triệu sản phẩm trong danh mục của họ và sử dụng tìm kiếm mờ để cung cấp cho người dùng các đề xuất tự động hoàn thành.
Ví dụ:Với khả năng tìm kiếm tạm thời của RediSearch, việc tạo chỉ số rất nhẹ, cho phép hàng nghìn chỉ số trong cùng một cơ sở dữ liệu để các nhà phát triển có thể nhanh chóng tạo và hết hạn các chỉ số dựa trên lịch sử mua hàng của khách hàng. Trong khi đó, một công ty bảo hiểm sức khỏe đang sử dụng RediSearch để cho phép người dùng chạy các truy vấn không gian địa lý trên các trang web và ứng dụng của họ để tìm các nhà cung cấp dịch vụ chăm sóc sức khỏe thích hợp trong khu vực lân cận của họ. Tất cả những ứng dụng này đã được triển khai trên quy mô lớn trong môi trường sản xuất.
Bắt đầu với RediSearch 2.0
Tìm hiểu cách bạn có thể sử dụng RediSearch 2.0 để tăng tốc hành trình hiện đại hóa ứng dụng của mình. Hoặc để bắt đầu ngay lập tức, hãy truy cập trang Bắt đầu nhanh RediSearch.