RedisTimeSeries là một mô-đun Redis mang lại cấu trúc dữ liệu chuỗi thời gian gốc cho Redis. Các giải pháp chuỗi thời gian, trước đó đã được xây dựng trên các Bộ được sắp xếp (hoặc Luồng Redis), có thể được hưởng lợi từ các tính năng của RedisTimeSeries như chèn khối lượng lớn, đọc có độ trễ thấp, ngôn ngữ truy vấn linh hoạt, lấy mẫu giảm và hơn thế nữa!
Nói chung, dữ liệu chuỗi thời gian (tương đối) đơn giản. Đã nói rằng, chúng ta cũng cần tính đến các đặc điểm khác:
- Tốc độ dữ liệu:ví dụ:Nghĩ đến hàng trăm chỉ số từ hàng nghìn thiết bị mỗi giây
- Khối lượng (Dữ liệu lớn):Hãy nghĩ đến việc tích lũy dữ liệu qua nhiều tháng (thậm chí nhiều năm)
Do đó, các cơ sở dữ liệu như RedisTimeSeries chỉ là một phần của giải pháp tổng thể. Bạn cũng cần nghĩ về cách thu thập (nhập), quy trình, và gửi tất cả dữ liệu của bạn vào RedisTimeSeries. Những gì bạn thực sự cần là một đường dẫn dữ liệu có thể mở rộng có thể hoạt động như một bộ đệm để tách nhà sản xuất và người tiêu dùng.
Đó là nơi Apache Kafka bước vào! Ngoài nhà môi giới cốt lõi, nó có một hệ sinh thái phong phú của các thành phần, bao gồm Kafka Connect (là một phần của kiến trúc giải pháp được trình bày trong bài đăng trên blog này), thư viện khách hàng bằng nhiều ngôn ngữ, Kafka Streams, Mirror Maker, v.v.
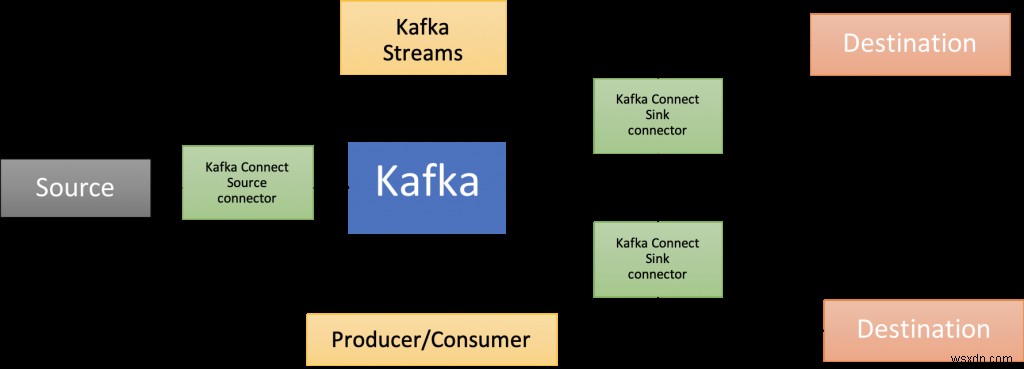
Bài đăng trên blog này cung cấp một ví dụ thực tế về cách sử dụng RedisTimeSeries với Apache Kafka để phân tích dữ liệu chuỗi thời gian.
Mã có sẵn trong repo GitHub này https://github.com/abhirockzz/redis-timeseries-kafka
Hãy bắt đầu bằng cách khám phá trường hợp sử dụng trước. Xin lưu ý rằng nó đã được giữ đơn giản cho các mục đích của bài đăng trên blog và sau đó được giải thích thêm trong các phần tiếp theo.
Tình huống:Giám sát thiết bị
Hãy tưởng tượng có nhiều địa điểm, mỗi địa điểm có nhiều thiết bị và bạn được giao trách nhiệm theo dõi các chỉ số của thiết bị — bây giờ chúng ta sẽ xem xét nhiệt độ và áp suất. Các chỉ số này sẽ được lưu trữ trong RedisTimeSeries (tất nhiên!) Và sử dụng quy ước đặt tên sau cho các khóa—
Dưới đây là một số ví dụ để cung cấp cho bạn ý tưởng về cách bạn sẽ thêm các điểm dữ liệu bằng lệnh TS.ADD:
# nhiệt độ cho thiết bị 2 ở vị trí 3 cùng với nhãn:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
# áp suất cho thiết bị 2 ở vị trí 3:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
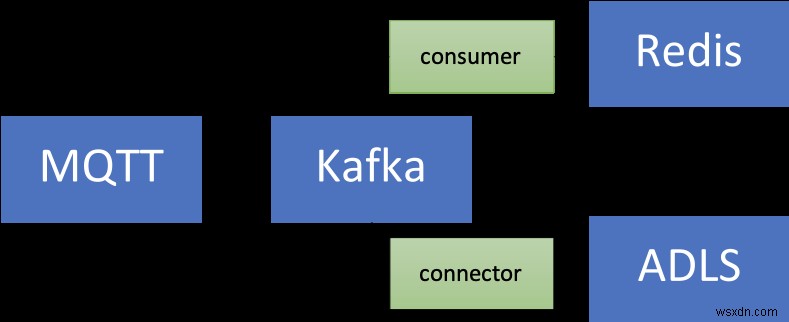
Kiến trúc giải pháp
Đây là giải pháp trông như thế nào ở cấp độ cao:
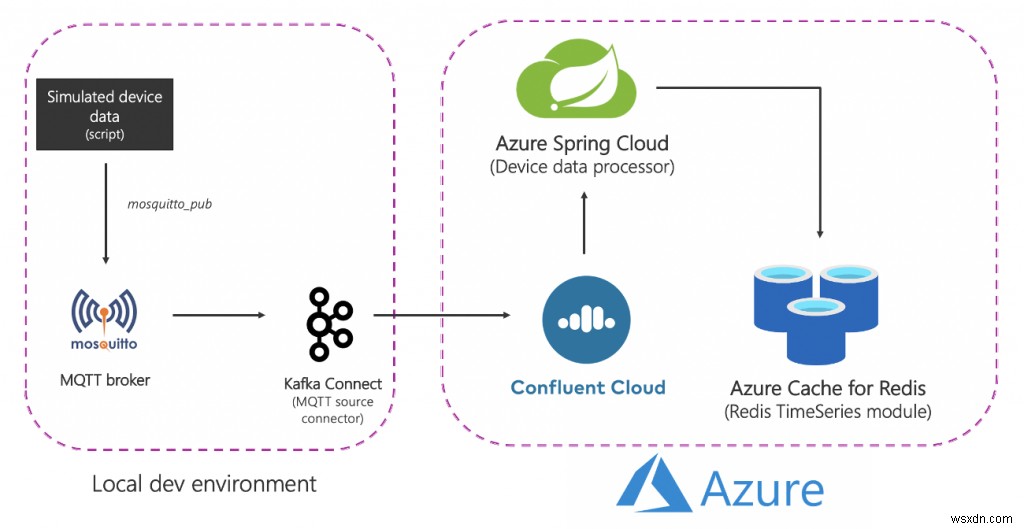
Hãy chia nhỏ nó:
Thành phần nguồn (cục bộ)
- Nhà môi giới MQTT (mosquitto):MQTT là một giao thức phi thực tế cho các trường hợp sử dụng IoT. Kịch bản mà chúng tôi sẽ sử dụng là sự kết hợp giữa IoT và Chuỗi thời gian - sẽ nói thêm về điều này sau.
- Kết nối Kafka:Trình kết nối nguồn MQTT được sử dụng để truyền dữ liệu từ nhà môi giới MQTT sang một cụm Kafka.
Dịch vụ Azure
- Azure Cache cho các cấp Redis Enterprise:Các cấp Enterprise dựa trên Redis Enterprise, một biến thể thương mại của Redis từ Redis. Ngoài RedisTimeSeries, cấp Enterprise cũng hỗ trợ RediSearch và RedisBloom. Khách hàng không cần phải lo lắng về việc mua lại giấy phép cho các cấp Doanh nghiệp. Azure Cache dành cho Redis sẽ tạo điều kiện thuận lợi cho quá trình này, trong đó khách hàng có thể lấy và trả tiền để có giấy phép cho phần mềm này thông qua ưu đãi của Azure Marketplace.
- Đám mây hợp lưu trên Azure:Một dịch vụ được quản lý hoàn toàn cung cấp Apache Kafka dưới dạng dịch vụ, nhờ vào lớp cung cấp tích hợp từ Azure đến Đám mây hợp lưu. Nó làm giảm gánh nặng của việc quản lý đa nền tảng và mang lại trải nghiệm hợp nhất để sử dụng Confluent Cloud trên cơ sở hạ tầng Azure, do đó cho phép bạn dễ dàng tích hợp Confluent Cloud với các ứng dụng Azure của mình.
- Azure Spring Cloud:Việc triển khai các vi dịch vụ Spring Boot cho Azure dễ dàng hơn nhờ Azure Spring Cloud. Azure Spring Cloud giúp giảm bớt những lo lắng về cơ sở hạ tầng, cung cấp quản lý cấu hình, khám phá dịch vụ, tích hợp CI / CD, triển khai xanh lam và hơn thế nữa. Dịch vụ này thực hiện tất cả các công việc nặng nhọc để các nhà phát triển có thể tập trung vào mã của họ.
Xin lưu ý rằng một số dịch vụ được lưu trữ cục bộ chỉ để giữ mọi thứ đơn giản. Trong triển khai cấp sản xuất, bạn cũng muốn chạy chúng trong Azure. Ví dụ:bạn có thể vận hành cụm Kafka Connect cùng với trình kết nối MQTT trong Dịch vụ Azure Kubernetes.
Tóm lại, đây là quy trình end-to-end:
- Một tập lệnh tạo ra dữ liệu thiết bị mô phỏng được gửi đến nhà môi giới MQTT địa phương.
- Dữ liệu này được thu thập bởi trình kết nối nguồn MQTT Kafka Connect và được gửi đến một chủ đề trong cụm Kafka đám mây hợp lưu đang chạy trong Azure.
- Nó được xử lý thêm bởi ứng dụng Spring Boot được lưu trữ trong Azure Spring Cloud, sau đó lưu trữ nó vào Azure Cache cho phiên bản Redis.
Đã đến lúc bắt đầu với những thứ thiết thực! Trước đó, hãy đảm bảo bạn có những điều sau đây.
Điều kiện tiên quyết:
- Tài khoản Azure —bạn có thể nhận một tài khoản miễn phí tại đây
- Cài đặt Azure CLI
- JDK 11 cho ví dụ:OpenJDK
- Phiên bản gần đây của Maven và Git
Thiết lập các thành phần cơ sở hạ tầng
Làm theo tài liệu để cung cấp Azure Cache cho Redis (Cấp doanh nghiệp) đi kèm với mô-đun RedisTimeSeries.
Cung cấp cụm Đám mây hợp lưu trên Azure Marketplace. Đồng thời tạo chủ đề Kafka (sử dụng tên mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

Bạn có thể cung cấp một phiên bản của Azure Spring Cloud bằng cách sử dụng cổng Azure hoặc sử dụng Azure CLI:
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
Trước khi tiếp tục, hãy đảm bảo sao chép repo GitHub:
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafkaThiết lập các dịch vụ cục bộ
Các thành phần bao gồm:
- Nhà môi giới MQTT của Mosquitto
- Kết nối Kafka với đầu nối nguồn MQTT
- Grafana để theo dõi dữ liệu chuỗi thời gian trong trang tổng quan
Nhà môi giới MQTT
Tôi đã cài đặt và khởi động nhà môi giới mosquitto cục bộ trên Mac.
brew install mosquitto
brew services start mosquittoBạn có thể làm theo các bước tương ứng với hệ điều hành của mình hoặc sử dụng hình ảnh Docker này.
Grafana
Tôi đã cài đặt và khởi động Grafana cục bộ trên Mac.
brew install grafana
brew services start grafanaBạn có thể làm điều tương tự cho hệ điều hành của mình hoặc thoải mái sử dụng hình ảnh Docker này.
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafanaKafka Connect
Bạn sẽ có thể tìm thấy tệp connect-distributed.properties trong repo mà bạn vừa sao chép. Thay thế các giá trị cho các thuộc tính như bootstrap.servers, sasl.jaas.config, v.v.
Đầu tiên, tải xuống và giải nén Apache Kafka cục bộ.
Bắt đầu một cụm Kafka Connect cục bộ:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesĐể cài đặt trình kết nối nguồn MQTT theo cách thủ công:
- Tải xuống tệp ZIP của trình kết nối / plugin từ liên kết này và,
- Giải nén nó vào một trong các thư mục được liệt kê trên thuộc tính cấu hình plugin.path của Connect worker
Nếu bạn đang sử dụng cục bộ Nền tảng hợp lưu, chỉ cần sử dụng CLI của Trung tâm hợp lưu: confluent-hub install confluentinc/kafka-connect-mqtt:latest
Tạo phiên bản trình kết nối nguồn MQTT
Đảm bảo kiểm tra tệp mqtt-source-config.json. Đảm bảo bạn nhập đúng tên chủ đề cho kafka.topic và giữ nguyên mqtt.topics.
curl -X POST -H 'Content-Type: application/json'
http://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl http://localhost:8083/connectors/mqtt-source/statusTriển khai ứng dụng bộ xử lý dữ liệu thiết bị
Trong repo GitHub mà bạn vừa sao chép, hãy tìm tệp application.yaml trong thư mục consumer/src/resources folder and replace the values for:
- Azure Cache cho máy chủ, cổng và khóa truy cập chính của Redis
- Khóa và bí mật của Confluent Cloud trên Azure API
Xây dựng tệp JAR của ứng dụng:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageTạo ứng dụng Azure Spring Cloud và triển khai tệp JAR cho nó:
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jarKhởi động trình tạo dữ liệu thiết bị được mô phỏng
Bạn có thể sử dụng tập lệnh trong repo GitHub mà bạn vừa sao chép:
./gen-timeseries-data.shLưu ý — tất cả những gì nó làm là sử dụng lệnh mosquitto_pub CLI để gửi dữ liệu.
Dữ liệu được gửi đến chủ đề MQTT thống kê thiết bị (đây không phải chủ đề Kafka). Bạn có thể kiểm tra kỹ bằng cách sử dụng thuê bao CLI:
mosquitto_sub -h localhost -t device-statsKiểm tra chủ đề Kafka trong cổng Đám mây hợp lưu. Bạn cũng nên kiểm tra nhật ký cho ứng dụng xử lý dữ liệu thiết bị trong Azure Spring Cloud:
az spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>Tận hưởng trang tổng quan Grafana!
Duyệt đến giao diện người dùng Grafana tại localhost:3000.
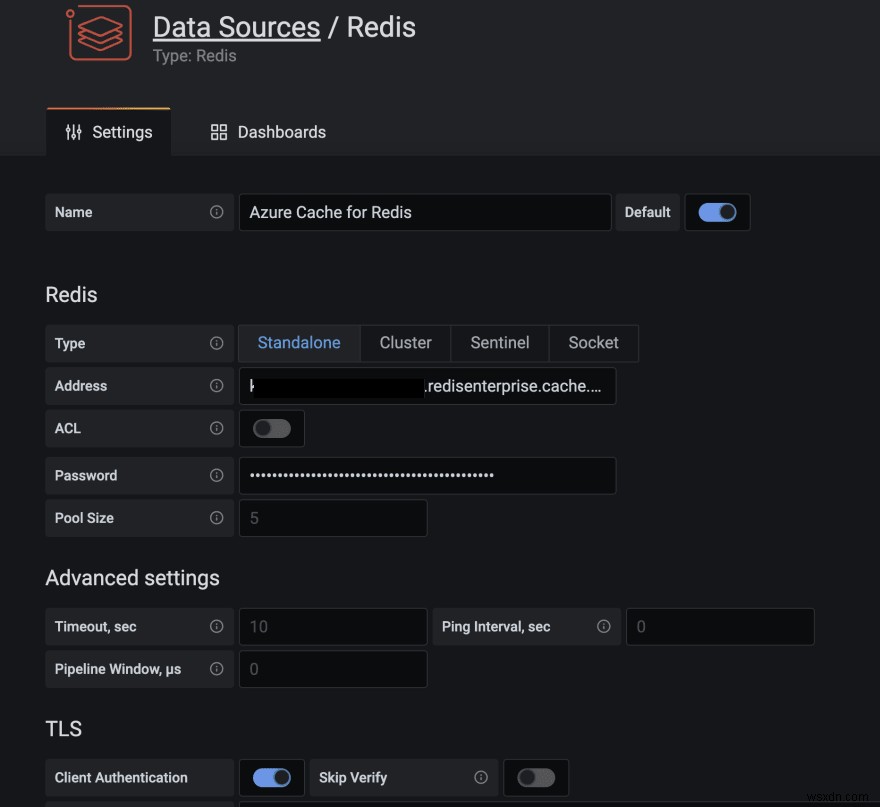
Plugin Nguồn dữ liệu Redis cho Grafana hoạt động với bất kỳ cơ sở dữ liệu Redis nào, bao gồm Azure Cache cho Redis. Làm theo hướng dẫn trong bài đăng blog này để định cấu hình nguồn dữ liệu.
Nhập trang tổng quan vào thư mục grafana_dashboards trong kho GitHub mà bạn đã sao chép (tham khảo tài liệu Grafana nếu bạn cần hỗ trợ về cách nhập trang tổng quan).
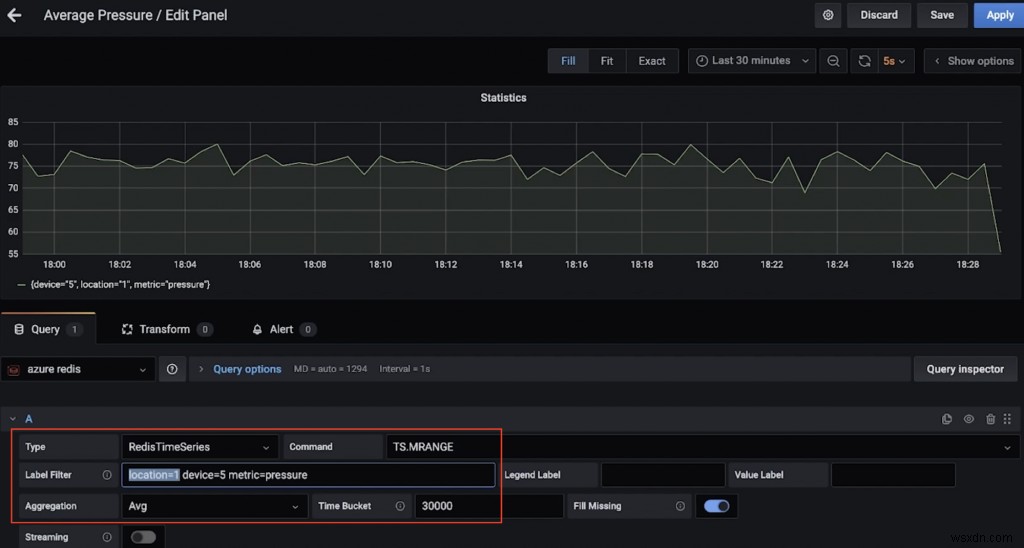
Ví dụ:đây là bảng điều khiển hiển thị áp suất trung bình (trên 30 giây) cho thiết bị 5 ở vị trí 1 (sử dụng TS.MRANGE).
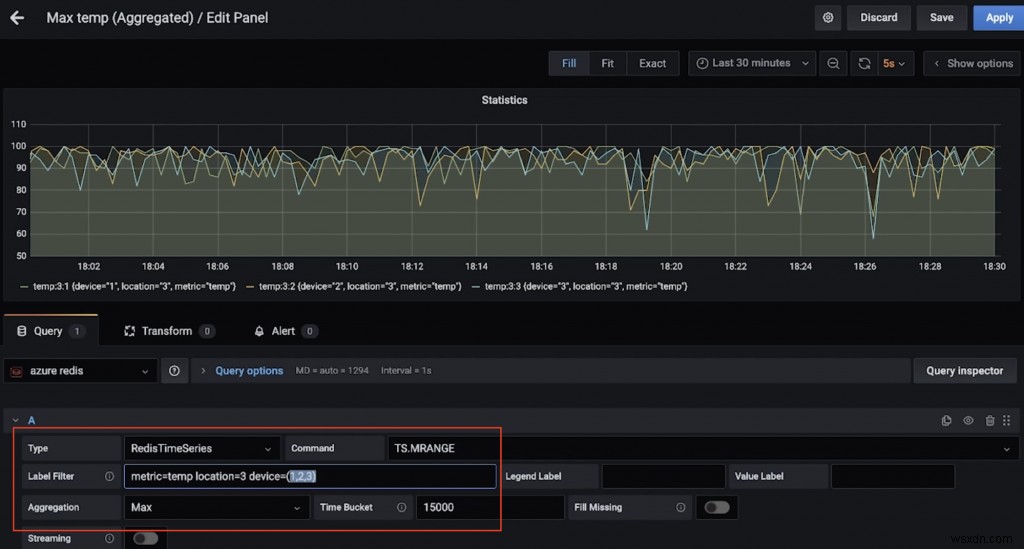
Đây là một bảng điều khiển khác hiển thị nhiệt độ tối đa (trên 15 giây) cho nhiều thiết bị ở vị trí 3 (một lần nữa, nhờ TS.MRANGE).
Vì vậy, bạn muốn chạy một số lệnh RedisTimeSeries?
Thu thập redis-cli và kết nối với Azure Cache cho phiên bản Redis:
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tlsBắt đầu với các truy vấn đơn giản:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5Lọc theo vị trí và nhận nhiệt độ và áp suất cho tất cả thiết bị:
TS.MGET WITHLABELS FILTER location=3Trích xuất nhiệt độ và áp suất cho tất cả các thiết bị ở một hoặc nhiều vị trí trong một phạm vi thời gian cụ thể:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)- + đề cập đến mọi thứ từ đầu cho đến dấu thời gian mới nhất, nhưng bạn có thể cụ thể hơn.
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=tempTất cả những thứ này có thể được kết hợp với nhau.
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=tempBạn cũng có thể tạo quy tắc để thực hiện việc tổng hợp này và lưu trữ nó trong một chuỗi thời gian khác.
Sau khi hoàn tất, đừng quên xóa tài nguyên để tránh các chi phí không mong muốn.
Xóa tài nguyên
- Làm theo các bước trong tài liệu để xóa nhóm Đám mây hợp lưu — tất cả những gì bạn cần là xóa tổ chức Đám mây hợp lưu.
- Tương tự, bạn cũng nên xóa Azure Cache cho phiên bản Redis.
Trên máy cục bộ của bạn:
- Dừng cụm Kafka Connect
- Ngăn chặn môi giới muỗi (ví dụ:dịch vụ nấu bia ngăn muỗi)
- Dừng dịch vụ Grafana (ví dụ:dịch vụ nấu bia ngừng grafana)
Chúng tôi đã khám phá một đường dẫn dữ liệu để nhập, xử lý và truy vấn dữ liệu chuỗi thời gian bằng Redis và Kafka. Khi nghĩ về các bước tiếp theo và hướng tới giải pháp cấp sản xuất, bạn nên cân nhắc thêm một số điều.
Cân nhắc bổ sung
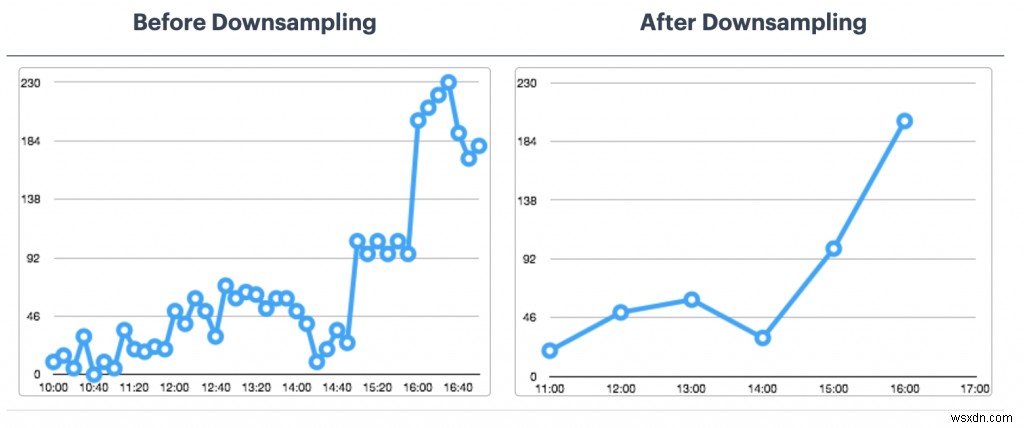
Tối ưu hóa RedisTimeSeries
- Chính sách lưu giữ:Hãy nghĩ về điều này vì các điểm dữ liệu chuỗi thời gian của bạn không được cắt hoặc xóa theo mặc định.
- Quy tắc lấy mẫu rút gọn và tổng hợp:Bạn không muốn lưu trữ dữ liệu mãi mãi, phải không? Đảm bảo định cấu hình các quy tắc thích hợp để xử lý vấn đề này (ví dụ:TS.CREATERULE temp:1:2 temp:avg:30 AGGREGATION trung bình 30000).
- Chính sách dữ liệu trùng lặp:Bạn muốn xử lý các mẫu trùng lặp như thế nào? Đảm bảo rằng chính sách mặc định (BLOCK) thực sự là những gì bạn cần. Nếu không, hãy xem xét các lựa chọn khác.
Đây không phải là một danh sách đầy đủ. Để biết các tùy chọn cấu hình khác, vui lòng tham khảo tài liệu RedisTimeSeries
Còn việc lưu giữ dữ liệu lâu dài thì sao?
Dữ liệu là quý giá, bao gồm cả chuỗi thời gian! Bạn có thể muốn xử lý thêm (ví dụ:chạy máy học để trích xuất thông tin chi tiết, bảo trì dự đoán, v.v.). Để có thể thực hiện được điều này, bạn sẽ cần lưu giữ dữ liệu này trong một khung thời gian dài hơn và để tiết kiệm chi phí và hiệu quả, bạn sẽ muốn sử dụng một dịch vụ lưu trữ đối tượng có thể mở rộng như Azure Data Lake Storage Gen2 (ADLS Gen2) .
Có một đầu nối cho điều đó! Bạn có thể nâng cao đường truyền dữ liệu hiện có bằng cách sử dụng Trình kết nối bồn chứa Azure Data Lake Gen2 được quản lý đầy đủ cho Đám mây hợp lưu để xử lý và lưu trữ dữ liệu trong ADLS, sau đó chạy máy học bằng Azure Synapse Analytics hoặc Azure Databricks.
Khả năng mở rộng
Khối lượng dữ liệu chuỗi thời gian của bạn chỉ có thể tăng một chiều — tăng lên! Điều quan trọng để giải pháp của bạn có thể mở rộng:
- Cơ sở hạ tầng cốt lõi:Các dịch vụ được quản lý cho phép các nhóm tập trung vào giải pháp hơn là thiết lập và duy trì cơ sở hạ tầng, đặc biệt là khi nói đến các hệ thống phân tán phức tạp như cơ sở dữ liệu và nền tảng phát trực tuyến như Redis và Kafka.
- Kafka Connect:Liên quan đến đường ống dữ liệu, bạn đang ở trong tay tốt vì nền tảng Kafka Connect vốn không có trạng thái và có thể mở rộng theo chiều ngang. Bạn có rất nhiều lựa chọn về cách bạn muốn kiến trúc và kích thước các cụm công nhân Kafka Connect của mình.
- Ứng dụng tùy chỉnh:Như trường hợp của giải pháp này, chúng tôi đã xây dựng một ứng dụng tùy chỉnh để xử lý dữ liệu trong các chủ đề Kafka. May mắn thay, các đặc điểm khả năng mở rộng tương tự cũng áp dụng cho chúng. Về quy mô ngang, nó chỉ bị giới hạn bởi số lượng phân vùng chủ đề Kafka mà bạn có.
Tích hợp :Đó không chỉ là Grafana! RedisTimeSeries cũng tích hợp với Prometheus và Telegraf. Tuy nhiên, không có trình kết nối Kafka tại thời điểm bài đăng blog này được viết — đây sẽ là một tiện ích bổ sung tuyệt vời!
Kết luận

Chắc chắn, bạn có thể sử dụng Redis cho (hầu hết) mọi thứ, bao gồm cả khối lượng công việc theo chuỗi thời gian! Hãy chắc chắn suy nghĩ về kiến trúc end-to-end cho đường ống dữ liệu và tích hợp từ các nguồn dữ liệu chuỗi thời gian, cho đến Redis và hơn thế nữa.