RediSearch, một chỉ mục phụ thời gian thực với khả năng tìm kiếm toàn văn cho Redis, là một trong những mô-đun Redis hoàn thiện và giàu tính năng nhất. Nó cũng đang trở nên phổ biến hơn mỗi ngày — trong vài tháng qua, lượt kéo RediSearch Docker đã tăng 500%! Sự phổ biến tăng vọt đó đã khiến khách hàng đưa ra nhiều trường hợp sử dụng thú vị khác nhau, từ quản lý khoảng không quảng cáo theo thời gian thực đến tìm kiếm tạm thời.
Để kéo dài động lực đó, chúng tôi hiện đang giới thiệu bản xem trước công khai của RediSearch 2.0, được thiết kế để cải thiện trải nghiệm của nhà phát triển và là phiên bản Redisearch có thể mở rộng nhất . RediSearch 2.0 hỗ trợ công nghệ phân phối địa lý Active-Active của Redis, có thể mở rộng mà không cần thời gian ngừng hoạt động và bao gồm hỗ trợ Redis trên Flash (hiện đang ở chế độ xem trước riêng tư). Để đạt được những mục tiêu đó mà không ảnh hưởng tiêu cực đến hiệu suất, chúng tôi đã tạo một kiến trúc hoàn toàn mới cho RediSearch 2.0 — và nó đã hoạt động: RediSearch 2.0 nhanh hơn 2,4 lần hơn RediSearch 1.6.
Kiến trúc mới của Inside RediSearch 2.0
Có một công cụ tổng hợp và truy vấn phong phú trong cơ sở dữ liệu Redis của bạn cho phép nhiều trường hợp sử dụng mới mở rộng ra ngoài bộ nhớ đệm. RediSearch cho phép bạn sử dụng Redis làm cơ sở dữ liệu chính của mình trong các tình huống mà bạn cần truy cập dữ liệu bằng các truy vấn phức tạp. Thậm chí tốt hơn, nó duy trì tốc độ, độ tin cậy và khả năng mở rộng đẳng cấp thế giới của Redis và không yêu cầu bạn thêm độ phức tạp vào mã để cho phép bạn cập nhật và lập chỉ mục dữ liệu.
Đối với RediSearch 2.0, chúng tôi đã tái cấu trúc cách các chỉ số được giữ đồng bộ với dữ liệu. Thay vì phải ghi dữ liệu thông qua chỉ mục (sử dụng lệnh FT.ADD), RediSearch giờ đây theo dõi dữ liệu được viết trong các hàm băm và lập chỉ mục đồng bộ. Kiến trúc lại này đi kèm với một số thay đổi trong API, mà chúng ta đã thảo luận trong một bài đăng trước khi RediSearch 2.0 đạt được cột mốc quan trọng đầu tiên.
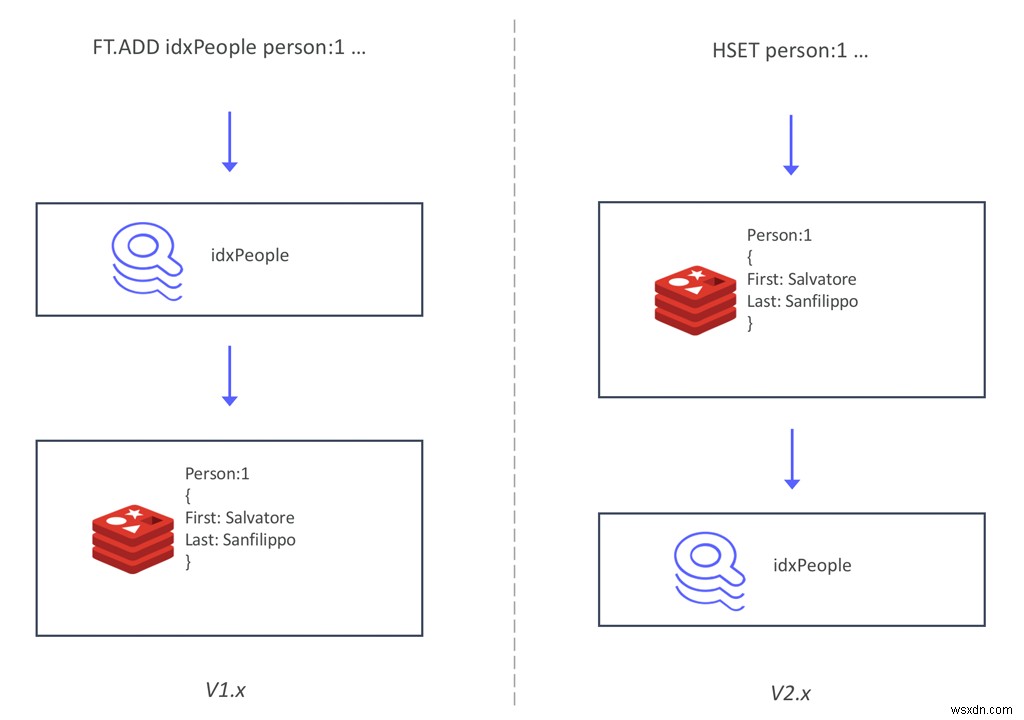
Kiến trúc mới này mang lại hai lợi ích chính. Đầu tiên, giờ đây, việc tạo chỉ mục phụ trên dữ liệu hiện có của bạn trở nên dễ dàng hơn bao giờ hết. Bạn chỉ có thể thêm RediSearch vào cơ sở dữ liệu Redis hiện có của mình, tạo chỉ mục và bắt đầu truy vấn nó , mà không cần phải di chuyển dữ liệu của bạn hoặc sử dụng các lệnh mới để thêm dữ liệu vào chỉ mục. Điều này làm giảm đáng kể đường cong học tập cho người dùng RediSearch mới và cho phép bạn tạo chỉ mục trên cơ sở dữ liệu Redis hiện có của mình — mà thậm chí không cần phải khởi động lại chúng.
Ngoài việc triển khai một cách mới để lập chỉ mục dữ liệu, chúng tôi cũng đưa chỉ mục ra khỏi không gian khóa. Điều này cho phép công nghệ Active-Active của Redis Enterprise dựa trên các loại dữ liệu được sao chép không có xung đột (CRDT). Việc hợp nhất hai chỉ số đảo ngược mà không có xung đột là rất khó, nhưng Redis đã có triển khai CRDTs đã được chứng minh của Hashes. Vì vậy, lợi ích lớn thứ hai của kiến trúc mới này là làm cho RediSearch 2.0 có thể mở rộng hơn nữa . Vì RediSearch hiện theo sau Hashes và chỉ mục đã được di chuyển ra khỏi keyspace, giờ đây bạn có thể chạy RediSearch trong cơ sở dữ liệu địa lý được phân phối Active-Active.
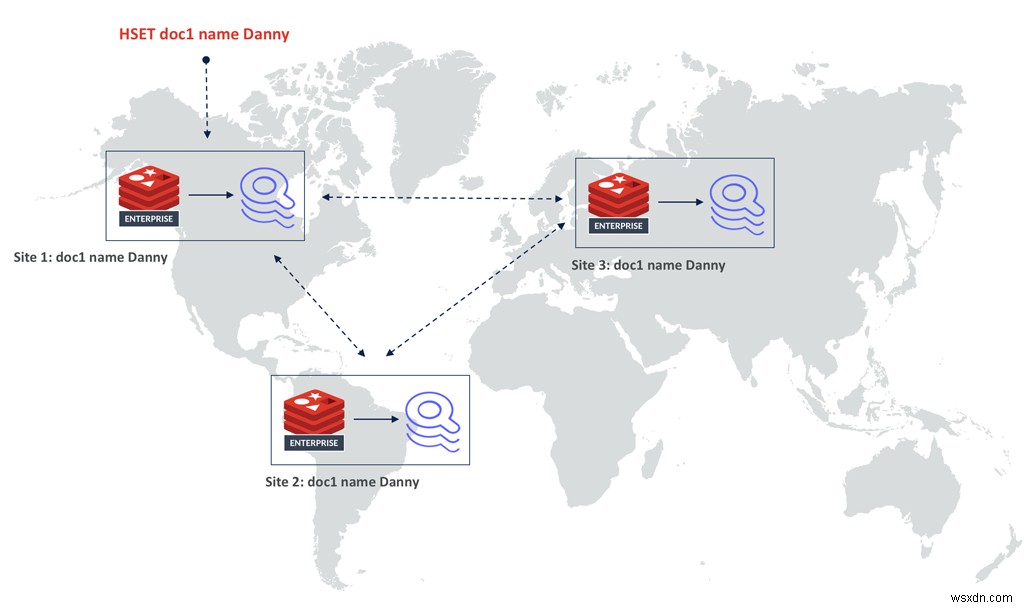
Một tài liệu sẽ được sao chép tới tất cả các cơ sở dữ liệu trong bộ sao chép theo cách thức nhất quán mạnh mẽ cuối cùng. Trong mỗi bản sao, RediSearch sẽ chỉ theo dõi tất cả các cập nhật trên Hashes, có nghĩa là tất cả các chỉ số cuối cùng cũng nhất quán.
Hỗ trợ cụm OSS cho nguồn mở Redis
Chúng tôi không muốn giới hạn việc tăng khả năng mở rộng cho chỉ người dùng Redis Enterprise, vì vậy, chúng tôi đã thêm hỗ trợ mở rộng một chỉ mục duy nhất trên nhiều phân đoạn bằng API cụm Redis mã nguồn mở. Trước đây, một chỉ mục RediSearch và các tài liệu của nó phải nằm trên một phân đoạn duy nhất. Điều này có nghĩa là kích thước tập dữ liệu và thông lượng cho OSS Redis bị ràng buộc với những gì mà một quy trình Redis duy nhất có thể xử lý. Redis Enterprise cung cấp khả năng phân phối tài liệu trong cơ sở dữ liệu nhóm và tổng hợp kết quả tại thời điểm truy vấn. Fan-out và tổng hợp này được xử lý bởi một thành phần được gọi là “điều phối viên” hiện cũng được cung cấp công khai theo Giấy phép Nguồn sẵn có của Redis, vì vậy nó sẽ hoạt động với các cụm Redis nguồn mở cũng như Redis Enterprise. Kết quả là phiên bản RediSearch có khả năng mở rộng cao nhất.
Cho tôi xem các con số!
Để đánh giá hiệu suất nhập của RediSearch 2.0, chúng tôi đã mở rộng bộ tiêu chuẩn tìm kiếm toàn văn (FTSB) với bộ dữ liệu NYC Taxi có sẵn công khai. Tập dữ liệu này được sử dụng trong toàn ngành do tập hợp các kiểu dữ liệu phong phú (văn bản, thẻ, địa lý và số) và một số lượng lớn tài liệu.
Tiêu chuẩn này tập trung vào hiệu suất ghi, sử dụng dữ liệu ghi lại chuyến đi của các chuyến đi bằng xe taxi màu vàng ở Thành phố New York. Cụ thể đối với điểm chuẩn này, chúng tôi đã sử dụng tập dữ liệu tháng 1 năm 2015, tập dữ liệu này tải hơn 12 triệu tài liệu với kích thước trung bình là 500 byte cho mỗi tài liệu. Để biết thông số kỹ thuật điểm chuẩn đầy đủ, vui lòng tham khảo FTSB trên GitHub.
Tất cả các biến thể điểm chuẩn đều được chạy trên các phiên bản Dịch vụ Web của Amazon, được cung cấp thông qua cơ sở hạ tầng kiểm tra điểm chuẩn của chúng tôi. Các bài kiểm tra được thực hiện trên một cụm 3 nút với 15 phân đoạn, với phiên bản RediSearch Enterprise 1.6 và 2.0. Cả ứng dụng khách đo điểm chuẩn và 3 nút bao gồm cơ sở dữ liệu có bật RediSearch đều đang chạy trên các phiên bản c5.9xlarge riêng biệt.
Do RediSearch 2.0 đi kèm với khả năng theo dõi các thay đổi trong Hash trong Redis và tự động lập chỉ mục chúng, chúng tôi đã thêm các biến thể cho lệnh FT.ADD và HSET. Để nâng cấp dễ dàng hơn, chúng tôi đã ánh xạ lại lệnh FT.ADD hiện không được dùng nữa thành các lệnh HSET trong RediSearch 2.0. Hai biểu đồ bên dưới hiển thị độ trễ và tốc độ nhập tổng thể cho cả RediSearch 1.6 và RediSearch 2.0, đồng thời giữ lại độ trễ dưới mili giây.
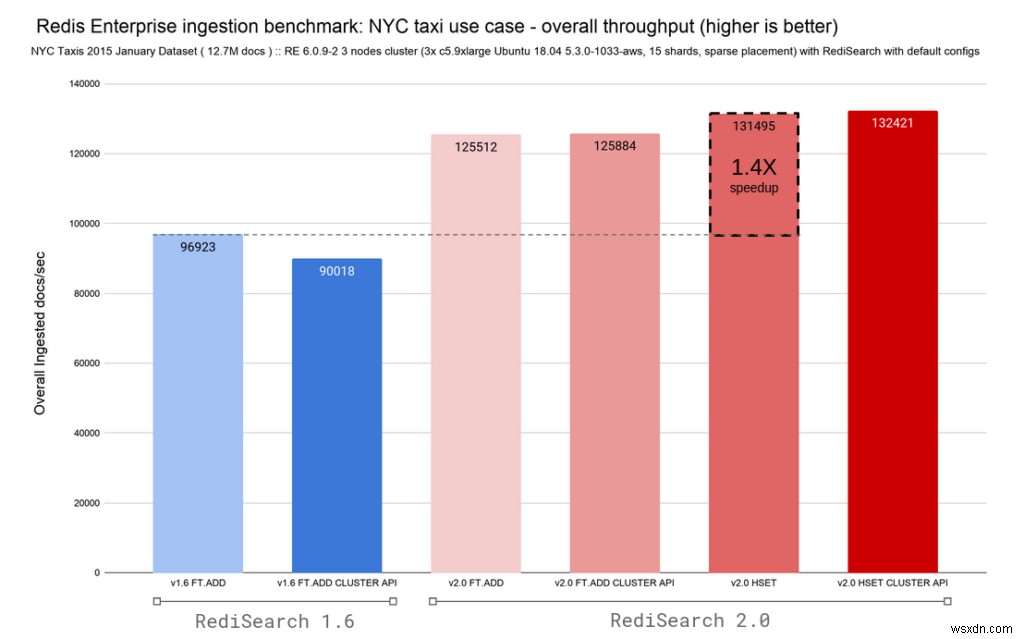
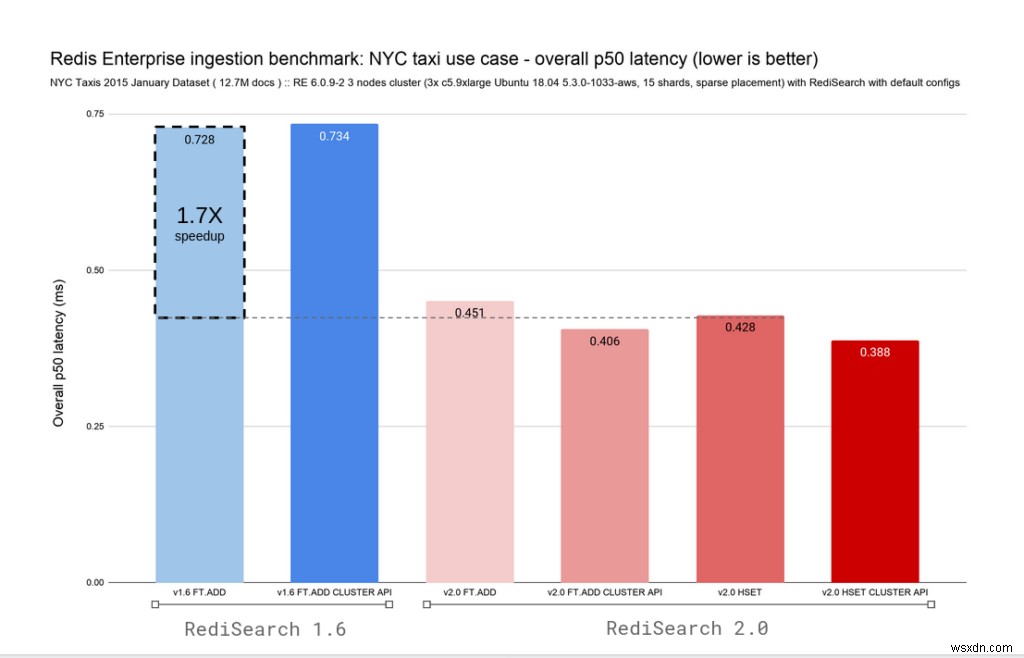
RediSearch luôn nhanh chóng, nhưng với sự thay đổi kiến trúc này, chúng tôi đã chuyển từ lập chỉ mục 96 nghìn tài liệu mỗi giây thành 132 nghìn tài liệu / giây với độ trễ nhập p50 tổng thể là 0,4 mili giây, cải thiện đáng kể tỷ lệ ghi.
Bạn không chỉ được hưởng lợi từ việc tăng thông lượng mà mỗi lần nhập cũng trở nên nhanh hơn. Ngoài việc cải thiện quá trình nhập tổng thể do những thay đổi trong kiến trúc, giờ đây bạn cũng có thể dựa vào các khả năng của API OSS Redis Cluster để mở rộng quy mô tuyến tính cho việc nhập cơ sở dữ liệu tìm kiếm của mình.
Kết hợp các cải tiến về lưu lượng và độ trễ, RediSearch 2.0 mang đến tốc độ tăng gấp 2,4 lần so với RediSearch 1.6.
Điều gì tiếp theo cho RediSearch 2.0
Tóm lại, RediSearch 2.0 là phiên bản nhanh nhất và có khả năng mở rộng cao nhất cho tất cả người dùng Redis mà chúng tôi đã từng phát hành. Ngoài ra, kiến trúc mới của RediSearch 2.0 cải thiện trải nghiệm của nhà phát triển trong việc tạo chỉ số cho dữ liệu hiện có trong Redis một cách liền mạch và loại bỏ nhu cầu di chuyển dữ liệu Redis của bạn sang một cơ sở dữ liệu hỗ trợ RediSearch khác. Kiến trúc mới này cho phép RediSearch theo dõi và tự động lập chỉ mục các cấu trúc dữ liệu khác, chẳng hạn như Luồng hoặc Chuỗi. Trong các bản phát hành sắp tới, nó sẽ cho phép bạn làm việc với các cấu trúc dữ liệu bổ sung, chẳng hạn như cấu trúc dữ liệu lồng nhau trong RedisJSON.
Chúng tôi dự định tiếp tục bổ sung thêm nhiều tính năng để nâng cao hơn nữa trải nghiệm của nhà phát triển. Tiếp theo, hãy tìm một lệnh mới cho phép bạn lập hồ sơ các truy vấn tìm kiếm của mình để hiểu rõ hơn về vị trí xảy ra tắc nghẽn hiệu suất trong quá trình thực thi truy vấn.
Sẵn sàng để bắt đầu? Xem blog của Tug Grall trên… Bắt đầu với RediSearch 2.0! Sau đó, làm theo các bước trong hướng dẫn này trên GitHub hoặc tạo cơ sở dữ liệu miễn phí trong Redis Enterprise Cloud Essentials. (Lưu ý rằng bản xem trước công khai của RediSearch 2.0 có sẵn ở hai khu vực Redis Enterprise Cloud Essentials:Mumbai và Oregon.)