Redis là một công nghệ nền tảng và như vậy, chúng tôi thỉnh thoảng thấy mọi người đang cân nhắc các kiến trúc thay thế. Một vài năm trước, điều này đã được KeyDB đưa ra và gần đây, một dự án mới, Dragonfly, được tuyên bố là kho dữ liệu trong bộ nhớ tương thích với Redis nhanh nhất. Chúng tôi tin rằng những dự án này mang lại nhiều công nghệ và ý tưởng thú vị đáng để thảo luận và tranh luận. Tại Redis, chúng tôi thích loại thử thách này, vì nó đòi hỏi chúng tôi phải khẳng định lại các nguyên tắc kiến trúc mà Redis đã được thiết kế ban đầu (đầu mũ cho Salvatore Sanfilippo hay còn gọi là antirez).
Mặc dù chúng tôi luôn tìm kiếm cơ hội để đổi mới và nâng cao hiệu suất và khả năng của Redis, chúng tôi muốn chia sẻ quan điểm của mình và một số phản ánh về lý do tại sao kiến trúc của Redis vẫn là tốt nhất trong lớp cho một kho dữ liệu trong bộ nhớ, thời gian thực (bộ nhớ cache , cơ sở dữ liệu và mọi thứ ở giữa).
Vì vậy, trong các phần tiếp theo, chúng tôi nêu bật quan điểm của chúng tôi về tốc độ và sự khác biệt về kiến trúc vì nó liên quan đến các so sánh đang được thực hiện. Ở cuối bài đăng này, chúng tôi cũng đã cung cấp chi tiết về các điểm chuẩn và so sánh hiệu suất so với dự án Dragonfly mà chúng tôi thảo luận bên dưới và mời bạn xem xét và tái tạo những điểm chuẩn này cho chính mình.
Tốc độ
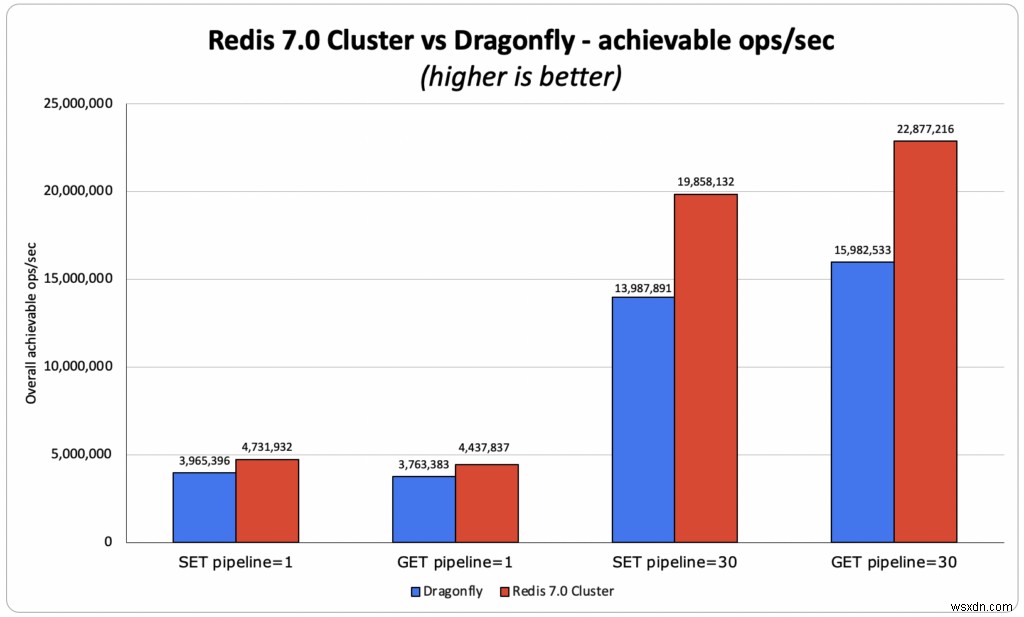
Điểm chuẩn Dragonfly so sánh một phiên bản Redis quy trình đơn lẻ độc lập (chỉ có thể sử dụng một lõi duy nhất) với một phiên bản Dragonfly đa luồng (có thể sử dụng tất cả các lõi có sẵn trên một máy ảo / máy chủ). Thật không may, so sánh này không đại diện cho cách Redis được điều hành trong thế giới thực. Với tư cách là những người xây dựng công nghệ, chúng tôi cố gắng hiểu chính xác cách công nghệ của chúng tôi so sánh với những công nghệ khác, vì vậy chúng tôi đã làm những gì chúng tôi tin là một so sánh công bằng và so sánh 40 phân đoạn Redis 7.0 Cluster (có thể sử dụng hầu hết các lõi phiên bản) với Dragonfly, bằng cách sử dụng tập hợp các bài kiểm tra hiệu suất trên loại phiên bản lớn nhất được nhóm Dragonfly sử dụng trong các điểm chuẩn của họ, AWS c6gn.16xlarge. Trong các thử nghiệm của chúng tôi, chúng tôi thấy Redis đạt được thông lượng lớn hơn 18% - 40% so với Dragonfly, ngay cả khi chỉ sử dụng 40 trong số 64 vCores.
Sự khác biệt về kiến trúc
Một số thông tin cơ bản
Chúng tôi tin rằng rất nhiều quyết định về kiến trúc của những người tạo ra các dự án đa luồng này đã bị ảnh hưởng bởi những điểm đau đớn mà họ đã trải qua trong công việc trước đây của họ. Chúng tôi đồng ý rằng việc chạy một quy trình Redis trên một máy đa lõi, đôi khi có hàng chục lõi và hàng trăm GB bộ nhớ, sẽ không tận dụng được các tài nguyên có sẵn rõ ràng. Nhưng đây không phải là cách Redis được thiết kế để sử dụng; đây chỉ là cách mà nhiều nhà cung cấp Redis đã chọn để chạy dịch vụ của họ.
Redis mở rộng quy mô theo chiều ngang bằng cách chạy đa quy trình (sử dụng Redis Cluster) ngay cả trong bối cảnh của một phiên bản đám mây duy nhất. Tại Redis (công ty), chúng tôi đã phát triển thêm khái niệm này và xây dựng Redis Enterprise cung cấp một lớp quản lý cho phép người dùng của chúng tôi chạy Redis trên quy mô lớn, với tính khả dụng cao, chuyển đổi dự phòng tức thì, dữ liệu liên tục và được bật sao lưu theo mặc định.
Chúng tôi quyết định chia sẻ một số nguyên tắc mà chúng tôi sử dụng ở hậu trường để giúp mọi người hiểu những gì chúng tôi tin là các phương pháp kỹ thuật tốt để chạy Redis trong môi trường sản xuất.
Nguyên tắc kiến trúc
Chạy nhiều phiên bản Redis trên mỗi máy ảo
Chạy nhiều phiên bản Redis trên mỗi máy ảo cho phép chúng tôi:
- Chia tỷ lệ tuyến tính, theo cả chiều dọc và chiều ngang, sử dụng kiến trúc hoàn toàn không chia sẻ. Điều này sẽ luôn mang lại sự linh hoạt hơn so với kiến trúc đa luồng chỉ mở rộng quy mô theo chiều dọc.
- Tăng tốc độ sao chép, vì quá trình sao chép được thực hiện song song trên nhiều quy trình.
- Khôi phục nhanh sau sự cố của máy ảo, do các phiên bản Redis của VM mới sẽ được cung cấp dữ liệu từ nhiều phiên bản Redis bên ngoài đồng thời.
Giới hạn mỗi quy trình Redis ở một kích thước hợp lý
Chúng tôi không cho phép một quy trình Redis nào có kích thước vượt quá 25 GB (và 50 GB khi chạy Redis trên Flash). Điều này cho phép chúng tôi:
- Để tận hưởng những lợi ích của việc sao chép-ghi-ghi mà không phải trả tiền phạt cho chi phí bộ nhớ lớn khi chuyển đổi Redis để sao chép, chụp nhanh và ghi lại Chỉ Thêm tệp (AOF). Và "có" nếu bạn không làm điều đó, bạn (hoặc người dùng của bạn) sẽ phải trả một cái giá đắt, như hình minh họa ở đây.
- Để dễ dàng quản lý các cụm của chúng tôi, di chuyển các phân đoạn, chỉnh sửa lại, mở rộng quy mô và cân bằng lại một cách nhanh chóng, vì mọi phiên bản của Redis đều được giữ nhỏ.
Chia tỷ lệ theo chiều ngang là điều tối quan trọng
Tính linh hoạt để chạy kho dữ liệu trong bộ nhớ của bạn với tỷ lệ theo chiều ngang là cực kỳ quan trọng. Đây chỉ là một vài lý do tại sao:
- Khả năng phục hồi tốt hơn - bạn sử dụng càng nhiều nút trong cụm của mình, thì cụm của bạn càng mạnh. Ví dụ:nếu bạn chạy tập dữ liệu của mình trên một cụm 3 nút và một nút bị xuống cấp, thì đó là 1/3 cụm của bạn không hoạt động; nhưng nếu bạn chạy tập dữ liệu của mình trên một cụm 9 nút và một nút bị giảm chất lượng, thì đó chỉ là 1/9 cụm của bạn không hoạt động.
- Dễ mở rộng quy mô hơn - dễ dàng hơn nhiều khi thêm một nút bổ sung vào cụm của bạn và chỉ di chuyển một phần của tập dữ liệu của bạn sang nó, thay vì mở rộng theo chiều dọc, nơi bạn cần mang một nút lớn hơn và sao chép toàn bộ tập dữ liệu của mình (và hãy nghĩ về tất cả những điều tồi tệ điều đó có thể xảy ra ở giữa quá trình có thể kéo dài này…)
- Mở rộng dần dần sẽ tiết kiệm chi phí hơn nhiều - mở rộng quy mô theo chiều dọc, đặc biệt là trong đám mây, rất tốn kém. Trong nhiều trường hợp, bạn cần tăng gấp đôi kích thước phiên bản của mình ngay cả khi bạn chỉ cần thêm một vài GB vào tập dữ liệu của mình.
- Thông lượng cao - tại Redis, chúng tôi thấy nhiều khách hàng đang chạy khối lượng công việc thông lượng cao trên các tập dữ liệu nhỏ, với băng thông mạng rất cao và / hoặc nhu cầu gói tin trên giây (PPS) cao. Hãy nghĩ về tập dữ liệu 1GB với trường hợp sử dụng 1M + ops / giây. Có hợp lý không khi chạy nó trên một cụm c6gn.16xlarge một nút (128GB với 64 CPU và 100gbps ở mức $ 2,7684 / giờ) thay vì cụm 3 nút c6gn.xlarge (8GB. 4 CPU lên đến 25Gbps với $ 0,1786 / giờ mỗi ) với ít hơn 20% chi phí và theo cách mạnh mẽ hơn nhiều? Có thể tăng thông lượng trong khi duy trì hiệu quả chi phí và cải thiện khả năng phục hồi có vẻ là một câu trả lời dễ dàng cho câu hỏi.
- Thực tế của NUMA - mở rộng quy mô theo chiều dọc cũng có nghĩa là chạy một máy chủ hai ổ cắm với nhiều lõi và DRAM lớn; kiến trúc dựa trên NUMA này rất phù hợp với kiến trúc đa xử lý như Redis vì nó hoạt động giống một mạng lưới các nút nhỏ hơn. Nhưng NUMA thách thức hơn đối với kiến trúc đa luồng và từ kinh nghiệm của chúng tôi với các dự án đa luồng khác, NUMA có thể làm giảm hiệu suất của kho dữ liệu trong bộ nhớ tới 80%.
- Giới hạn lưu lượng bộ nhớ - các đĩa ngoài như AWS EBS, không mở rộng nhanh như bộ nhớ và CPU. Trên thực tế, có những giới hạn thông lượng lưu trữ do các nhà cung cấp dịch vụ đám mây áp đặt dựa trên lớp máy đang được sử dụng. Do đó, cách duy nhất để mở rộng quy mô một cụm hiệu quả để tránh các vấn đề đã được mô tả và đáp ứng các yêu cầu về độ bền dữ liệu cao là sử dụng tính năng mở rộng theo chiều ngang, tức là bằng cách thêm nhiều nút hơn và nhiều đĩa gắn mạng hơn.
- Đĩa phù du - một đĩa tạm thời là một cách tuyệt vời để chạy Redis trên SSD (nơi SSD được sử dụng thay thế DRAM, nhưng không phải là bộ lưu trữ liên tục) và tận hưởng chi phí của cơ sở dữ liệu dựa trên đĩa trong khi duy trì tốc độ Redis (xem cách chúng tôi thực hiện với Redis trên Flash). Một lần nữa, khi đĩa tạm thời đạt đến giới hạn, cách tốt nhất và trong nhiều trường hợp, cách duy nhất để mở rộng cụm của bạn là thêm nhiều nút hơn và nhiều đĩa tạm thời hơn.
- Phần cứng hàng hóa - cuối cùng, chúng tôi có nhiều khách hàng tại chỗ đang chạy trong một trung tâm dữ liệu cục bộ, đám mây riêng và thậm chí trong các trung tâm dữ liệu nhỏ; trong những môi trường này, có thể khó tìm thấy máy có bộ nhớ trên 64 GB và 8 CPU và một lần nữa, cách duy nhất để chia tỷ lệ là theo chiều ngang.
Tóm tắt
Chúng tôi đánh giá cao những ý tưởng và công nghệ mới, thú vị từ cộng đồng của chúng tôi khi được cung cấp bởi làn sóng dự án đa luồng mới. Thậm chí có khả năng một số khái niệm này có thể xuất hiện trên Redis trong tương lai (như io_uring mà chúng tôi đã bắt đầu xem xét, từ điển hiện đại hơn, sử dụng chuỗi chiến thuật hơn, v.v.). Nhưng trong tương lai gần, chúng tôi sẽ không từ bỏ nguyên tắc cơ bản của kiến trúc đa quy trình, không dùng chung mà Redis cung cấp. Thiết kế này cung cấp hiệu suất, khả năng mở rộng và khả năng phục hồi tốt nhất đồng thời hỗ trợ nhiều loại kiến trúc triển khai theo yêu cầu của nền tảng dữ liệu trong bộ nhớ, thời gian thực.
Phụ lục Redis 7.0 so với Chi tiết điểm chuẩn của Dragonfly
Tóm tắt điểm chuẩn
Phiên bản:
- Chúng tôi đã sử dụng Redis 7.0.0 và xây dựng nó từ nguồn
- Dragonfly được tạo từ nguồn vào ngày 3 tháng 6 (hash =e806e6ccd8c79e002f721a1a5ecb847bd7a06489) theo đề xuất trong https://github.com/Dragonfly/dragonfly#building-from-source
Mục tiêu:
- Xác minh rằng kết quả Dragonfly có thể tái tạo và xác định điều kiện đầy đủ mà chúng được truy xuất (do có một số cấu hình bị thiếu trên memtier_benchmark, phiên bản hệ điều hành, v.v.) xem thêm tại đây
- Xác định hiệu suất tốt nhất có thể đạt được của OSS Redis 7.0.0 Cluster qua phiên bản AWS c6gn.16xlarge, phù hợp với điểm chuẩn của Dragonfly
Cấu hình máy khách:
- Giải pháp OSS Redis 7.0 yêu cầu số lượng kết nối mở lớn hơn đến Cụm Redis, với mỗi memtier_benchmark chuỗi được kết nối với tất cả các phân đoạn
- Giải pháp OSS Redis 7.0 cung cấp kết quả tốt nhất với hai memtier_benchmark các quy trình đang chạy điểm chuẩn nhưng trên cùng một máy ảo ứng dụng khách để phù hợp với điểm chuẩn của Dragonfly)
Sử dụng tài nguyên và cấu hình tối ưu:
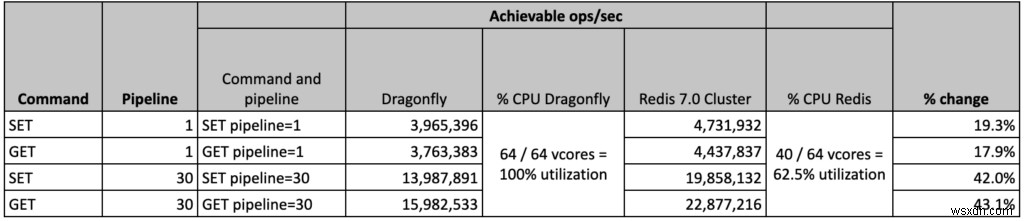
- OSS Redis Cluster đạt được kết quả tốt nhất với 40 phân đoạn chính, nghĩa là có 24 vCPU dự phòng trên VM. Mặc dù máy không được sử dụng đầy đủ, chúng tôi nhận thấy rằng việc tăng số lượng phân đoạn không giúp ích được gì mà ngược lại còn làm giảm hiệu suất tổng thể. Chúng tôi vẫn đang điều tra hành vi này.
- Mặt khác, giải pháp Dragonfly đã vượt qua hoàn toàn máy ảo với tất cả 64 VCPU đạt mức sử dụng 100%.
- Đối với cả hai giải pháp, chúng tôi đã thay đổi cấu hình máy khách để đạt được kết quả tốt nhất có thể. Như có thể thấy bên dưới, chúng tôi đã quản lý để sao chép phần lớn dữ liệu Dragonfly và thậm chí vượt qua kết quả tốt nhất cho một đường dẫn bằng 30.
- Điều này có nghĩa là có tiềm năng tăng hơn nữa những con số mà chúng tôi đã đạt được với Redis.
Cuối cùng, chúng tôi cũng nhận thấy rằng cả Redis và Dragonfly đều không bị giới hạn bởi PPS mạng hoặc băng thông, vì chúng tôi đã xác nhận rằng giữa 2 máy ảo được sử dụng (cho máy khách và máy chủ, bot sử dụng c6gn.16xlarge), chúng tôi có thể đạt> 10 triệu PPS và> 30 Gbps cho TCP với tải trọng ~ 300B.
Phân tích kết quả
- NHẬN đường dẫn 1 mili giây phụ :
- OSS Redis:4,43M ops / giây, trong đó cả trung bình và p50 đều đạt được độ trễ dưới mili giây. Độ trễ trung bình của khách hàng là 0,383 mili giây
- Dragonfly đã xác nhận 4 triệu ops / giây:
- Chúng tôi đã cố gắng tái tạo 3,8 triệu ops / giây, với độ trễ trung bình của khách hàng là 0,390 mili giây
- Redis so với Dragonfly - Thông lượng của Redis lớn hơn 10% so với Dragonfly đã xác nhận kết quả và 18% so với kết quả Dragonfly mà chúng tôi có thể tái tạo.
- NHẬN đường dẫn 30:
- OSS Redis:22,9M ops / giây với độ trễ trung bình của ứng dụng khách là 2,239 mili giây
- Dragonfly đã xác nhận 15 triệu ops / giây:
- Chúng tôi đã cố gắng tái tạo 15,9 triệu ops / giây với độ trễ trung bình của khách hàng là 3,99 mili giây
- Redis so với Dragonfly - Redis tốt hơn 43% (so với kết quả được mô phỏng lại của Dragonfly) và bằng 52% (so với Dragonfly đã xác nhận kết quả)
- ĐẶT đường dẫn 1 mili giây phụ :
- OSS Redis:4,74M ops / giây, trong đó cả trung bình và p50 đều đạt được độ trễ dưới mili giây. Độ trễ trung bình của khách hàng là 0,391 mili giây
- Dragonfly đã xác nhận 4 triệu ops / giây:
- Chúng tôi đã cố gắng tái tạo 4 triệu ops / giây, với độ trễ trung bình của khách hàng là 0,500 mili giây
- Redis so với Dragonfly - Redis tốt hơn 1 9% (chúng tôi đã tái tạo kết quả giống như Dragonfly đã tuyên bố là có)
- ĐẶT đường dẫn 30:
- OSS Redis:19,85M ops / giây, với độ trễ trung bình của ứng dụng khách là 2,879 mili giây
- Dragonfly đã xác nhận 10 triệu ops / giây:
- Chúng tôi đã cố gắng tái tạo 14 triệu ops / giây, với độ trễ trung bình của khách hàng là 4,203 mili giây)
- Redis so với Dragonfly - Redis tốt hơn 42% (so với kết quả được mô phỏng lại Dragonfly) và 99% (so với Dragonfly đã xác nhận kết quả)
memtier_benchmark các lệnh được sử dụng cho mỗi biến thể:
- NHẬN đường dẫn 1 mili giây phụ
- Redis:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinction-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-Maximum 1000000 –hide -biểu đồ
- Chuồn chuồn:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram
- Redis:
- NHẬN đường dẫn 30
- Redis:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinction-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-Maximum 1000000 –hide -histogram –pipeline 30
- Chuồn chuồn:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram –pipeline 30
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram –pipeline 30
- Redis:
- ĐẶT đường dẫn 1 mili giây phụ
- Redis:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinction-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-Maximum 1000000 –hide -biểu đồ
- Chuồn chuồn:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram
- Redis:
- ĐẶT đường dẫn 30
- Redis:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinction-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-Maximum 1000000 –hide -histogram –pipeline 30
- Chuồn chuồn:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinction-client-seed -d 256 -s 10.3.1.6 –key-Maximum 1000000 –hide-histogram –pipeline 30
- Redis:
Chi tiết cơ sở hạ tầng
Chúng tôi đã sử dụng cùng một loại máy ảo cho cả máy khách (để chạy memtier_benchmark) và máy chủ (để chạy Redis và Dragonfly), đây là thông số:
- VM :
- AWS c6gn.16xlarge
- aarch64
- ARM Neoverse-N1
- (Các) lõi trên mỗi ổ cắm:64
- (Các) chuỗi trên mỗi lõi:1
- NUMA nút:1
- AWS c6gn.16xlarge
- Kernel:Arm64 Kernel 5.10
- Installed Memory: 126GB