Nhiệm vụ của chúng ta là thu thập thông tin một trang web và đếm tần suất xuất hiện của từ đó. Và cuối cùng là truy xuất các từ thường gặp nhất.
Đầu tiên, chúng tôi đang sử dụng mô-đun request và súp đẹp và với sự trợ giúp của mô-đun này, tạo trình thu thập thông tin web và trích xuất dữ liệu từ trang web và lưu trữ trong một danh sách.
Mã mẫu
import requests
from bs4 import BeautifulSoup
import operator
from collections import Counter
def my_start(url):
my_wordlist = []
my_source_code = requests.get(url).text
my_soup = BeautifulSoup(my_source_code, 'html.parser')
for each_text in my_soup.findAll('div', {'class':'entry-content'}):
content = each_text.text
words = content.lower().split()
for each_word in words:
my_wordlist.append(each_word)
clean_wordlist(my_wordlist)
# Function removes any unwanted symbols
def clean_wordlist(wordlist):
clean_list =[]
for word in wordlist:
symbols = '!@#$%^&*()_-+={[}]|\;:"<>?/., '
for i in range (0, len(symbols)):
word = word.replace(symbols[i], '')
if len(word) > 0:
clean_list.append(word)
create_dictionary(clean_list)
def create_dictionary(clean_list):
word_count = {}
for word in clean_list:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
c = Counter(word_count)
# returns the most occurring elements
top = c.most_common(10)
print(top)
# Driver code
if __name__ == '__main__':
my_start("https://www.tutorialspoint.com/python3/python_overview.htm/")
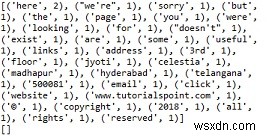
Đầu ra