Tensorflow là một khuôn khổ học máy do Google cung cấp. Nó là một khung công tác mã nguồn mở được sử dụng kết hợp với Python để triển khai các thuật toán, ứng dụng học sâu và hơn thế nữa. Nó được sử dụng trong nghiên cứu và cho mục đích sản xuất.
Tập dữ liệu ‘IMDB’ chứa các bài đánh giá hơn 50 nghìn bộ phim. Tập dữ liệu này thường được sử dụng với các hoạt động liên quan đến Xử lý ngôn ngữ tự nhiên.
Chúng tôi đang sử dụng Google Colaboratory để chạy đoạn mã dưới đây. Google Colab hoặc Colaboratory giúp chạy mã Python qua trình duyệt và không yêu cầu cấu hình cũng như quyền truy cập miễn phí vào GPU (Đơn vị xử lý đồ họa). Colaboratory đã được xây dựng trên Jupyter Notebook.
Sau đây là đoạn mã để tạo một biểu đồ trực quan hóa độ chính xác và mất mát theo thời gian trong tập dữ liệu IMDB -
Ví dụ
history_dict = history.history
history_dict.keys()
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, 'ro', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss with respect to time')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show() Mã tín dụng - https://www.tensorflow.org/tutorials/keras/text_classification
Đầu ra
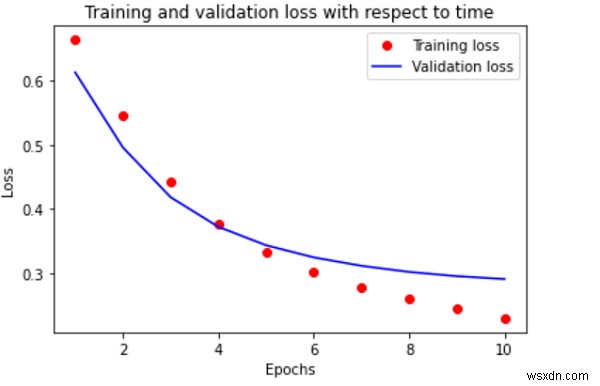
Giải thích
-
Khi dữ liệu đã phù hợp với mô hình, giá trị thực tế và giá trị dự đoán cần được so sánh.
-
Cách tốt nhất để làm điều này là thông qua hình ảnh hóa.
-
Do đó, thư viện ‘matplotlib’ được sử dụng để vẽ biểu đồ tổn thất xảy ra trong quá trình đào tạo và xác thực theo thời gian.
-
Điều này dựa trên số bước (hoặc kỷ nguyên) được thực hiện để huấn luyện dữ liệu cho phù hợp với mô hình.