Tensorflow là một khuôn khổ học máy do Google cung cấp. Nó là một khung công tác mã nguồn mở được sử dụng cùng với Python để triển khai các thuật toán, ứng dụng học sâu và hơn thế nữa. Nó được sử dụng trong nghiên cứu và cho mục đích sản xuất. Nó có các kỹ thuật tối ưu hóa giúp thực hiện các phép toán phức tạp một cách nhanh chóng. Điều này là do nó sử dụng NumPy và các mảng đa chiều. Các mảng đa chiều này còn được gọi là 'tensors'. Khung hỗ trợ làm việc với mạng nơ-ron sâu. Nó có khả năng mở rộng cao và đi kèm với nhiều bộ dữ liệu phổ biến.
Tensor là một cấu trúc dữ liệu được sử dụng trong TensorFlow. Nó giúp kết nối các cạnh trong một sơ đồ luồng. Sơ đồ luồng này được gọi là 'Biểu đồ luồng dữ liệu'. Tensors không là gì ngoài mảng nhiều chiều hoặc một danh sách.
Mục đích đằng sau bài toán hồi quy là dự đoán đầu ra của một biến số liên tục hoặc rời rạc, chẳng hạn như giá cả, xác suất, liệu trời có mưa hay không, v.v.
Tập dữ liệu chúng tôi sử dụng được gọi là tập dữ liệu ‘Auto MPG’. Nó chứa hiệu suất nhiên liệu của ô tô những năm 1970 và 1980. Nó bao gồm các thuộc tính như trọng lượng, mã lực, dịch chuyển, v.v. Với điều này, chúng ta cần dự đoán hiệu quả sử dụng nhiên liệu của các loại xe cụ thể.
Chúng tôi đang sử dụng Google Colaboratory để chạy đoạn mã dưới đây. Google Colab hoặc Colaboratory giúp chạy mã Python qua trình duyệt và không yêu cầu cấu hình cũng như quyền truy cập miễn phí vào GPU (Đơn vị xử lý đồ họa). Colaboratory đã được xây dựng trên Jupyter Notebook.
Sau đây là đoạn mã, trong đó chúng ta sẽ xem cách dữ liệu có thể được phân tách và kiểm tra để dự đoán hiệu suất nhiên liệu với bộ dữ liệu MPG tự động sử dụng TensorFlow -
Ví dụ
print("Splitting the training and testing dataset")
train_dataset = dataset.sample(frac=0.7, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
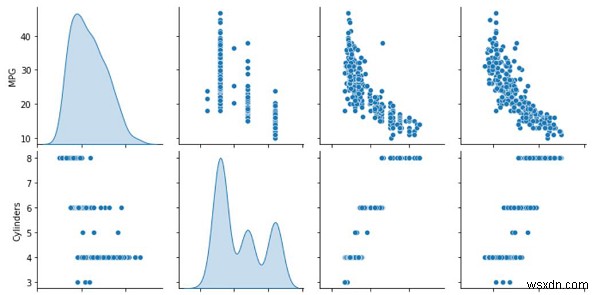
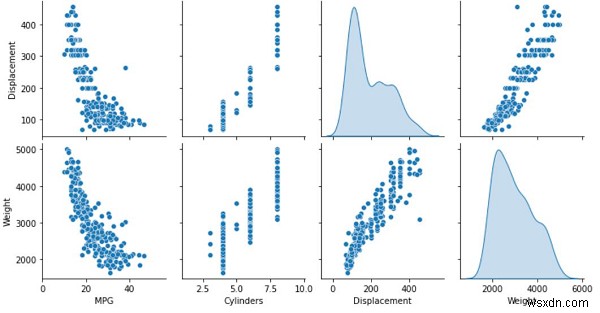
print("Plotting the training data as a visualization")
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
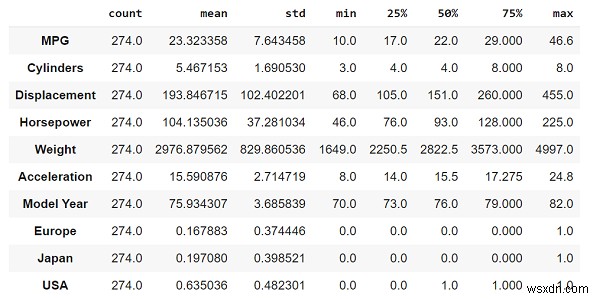
print("Understanding the statistics associated with the data")
train_dataset.describe().transpose() Mã tín dụng - https://www.tensorflow.org/tutorials/keras/regression
Đầu ra
Splitting the training and testing dataset Plotting the training data as a visualization Understanding the statistics associated with the data
Giải thích
-
Sau khi dữ liệu đã được làm sạch, dữ liệu được chia thành tập dữ liệu đào tạo và kiểm tra.
-
70 phần trăm dữ liệu được sử dụng để đào tạo và 30 phần trăm còn lại được sử dụng để thử nghiệm.
-
Dữ liệu đào tạo này được hiển thị trực quan trên bảng điều khiển bằng gói seaborn.
-
Thống kê của dữ liệu, chẳng hạn như số lượng, giá trị trung bình, giá trị trung bình, v.v. được hiển thị bằng cách sử dụng hàm "description".