Nhiều lựa chọn mà chúng tôi đưa ra xoay quanh các mối quan hệ số.
- Chúng ta ăn một số loại thực phẩm vì khoa học nói rằng chúng làm giảm lượng cholesterol của chúng ta
- Chúng tôi nâng cao trình độ học vấn vì chúng tôi có khả năng được tăng lương
- Chúng tôi mua một ngôi nhà trong khu phố mà chúng tôi tin rằng sẽ đánh giá cao nhất về giá trị
Làm thế nào để chúng ta đi đến những kết luận này? Rất có thể, ai đó đã thu thập một lượng lớn dữ liệu và sử dụng nó để hình thành kết luận. Một kỹ thuật phổ biến là hồi quy tuyến tính, là một hình thức học có giám sát. Để biết thêm thông tin về học có giám sát và ví dụ về những gì nó thường được sử dụng, hãy xem Phần 1 của loạt bài này.
Mối quan hệ Tuyến tính
Khi hai giá trị - hãy gọi chúng là x và y - có mối quan hệ tuyến tính, có nghĩa là thay đổi x bởi 1 sẽ luôn gây ra y để thay đổi theo một số tiền cố định. Sẽ dễ dàng hơn để đưa ra các ví dụ:
- 10 chiếc bánh pizza có giá gấp 10 lần giá một chiếc bánh pizza.
- Một bức tường cao 10 foot cần lượng sơn gấp đôi bức tường 5 foot
Về mặt toán học, loại mối quan hệ này được mô tả bằng cách sử dụng phương trình của một đường:
y = mx + b
Toán học có thể khó hiểu một cách đáng sợ, nhưng đôi khi nó giống như một phép thuật đối với tôi. Khi tôi lần đầu tiên học phương trình của một đường thẳng, tôi nhớ mình đã nghĩ rằng thật tuyệt vời như thế nào khi có thể tính khoảng cách, độ dốc và các điểm khác trên một đường chỉ bằng một công thức.
Nhưng làm thế nào để bạn có được công thức này, nếu tất cả những gì bạn có là điểm dữ liệu? Câu trả lời là hồi quy tuyến tính - một công cụ học máy rất phổ biến.
Ví dụ về hồi quy tuyến tính
Trong bài đăng này, chúng ta sẽ khám phá xem liệu nhịp mỗi phút (BPM) trong một bài hát có dự đoán mức độ phổ biến của nó trên Spotify hay không.
Hồi quy tuyến tính mô hình mối quan hệ giữa hai biến. Một được gọi là "biến giải thích" và một được gọi là "biến phụ thuộc".
Trong ví dụ của chúng tôi, chúng tôi muốn xem liệu BPM có thể "giải thích" sự phổ biến hay không. Vì vậy, BPM sẽ là biến giải thích của chúng tôi. Điều đó làm cho mức độ phổ biến trở thành biến phụ thuộc.
Mô hình sẽ sử dụng hồi quy bình phương nhỏ nhất để tìm dòng phù hợp nhất của biểu mẫu, bạn đoán nó, y = mx + b .
Trong khi có thể có nhiều biến giải thích, đối với ví dụ này, chúng tôi sẽ tiến hành hồi quy tuyến tính đơn giản khi chỉ có một biến.
Least-Squares Cái gì?
Có một số cách để thực hiện hồi quy tuyến tính. Một trong số chúng được gọi là "bình phương nhỏ nhất". Nó tính toán dòng phù hợp nhất bằng cách giảm thiểu tổng bình phương của độ lệch dọc từ mỗi điểm dữ liệu đến dòng.
Tôi biết điều đó nghe có vẻ khó hiểu, nhưng về cơ bản tôi chỉ nói rằng, "Hãy xây dựng cho tôi một đường giúp giảm thiểu khoảng cách giữa đường đã nói và các điểm dữ liệu."
Lý do cho bình phương và tổng là vì vậy không có bất kỳ sự hủy bỏ nào giữa các giá trị dương và âm.
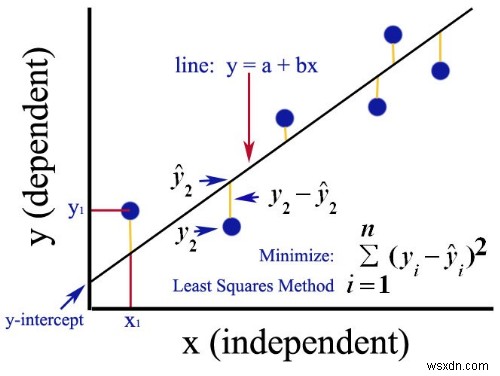
Đây là một hình ảnh tôi tìm thấy trên Quora đã giải thích nó khá tốt.
Tập dữ liệu
chúng tôi sẽ sử dụng tập dữ liệu này từ Kaggle:https://www.kaggle.com/leonardopena/top50spotify2019 Bạn có thể tải xuống dưới dạng CSV.
Tập dữ liệu có 16 cột; tuy nhiên, chúng tôi chỉ quan tâm đến ba - "Tên bản nhạc", "Nhịp đập mỗi phút" và "Mức độ phổ biến". Một trong những bước quan trọng nhất của học máy là làm cho dữ liệu của bạn được định dạng đúng cách, thường được gọi là "munging". Bạn có thể xóa tất cả dữ liệu ngoại trừ ba cột nói trên.
CSV của bạn sẽ trông giống như sau: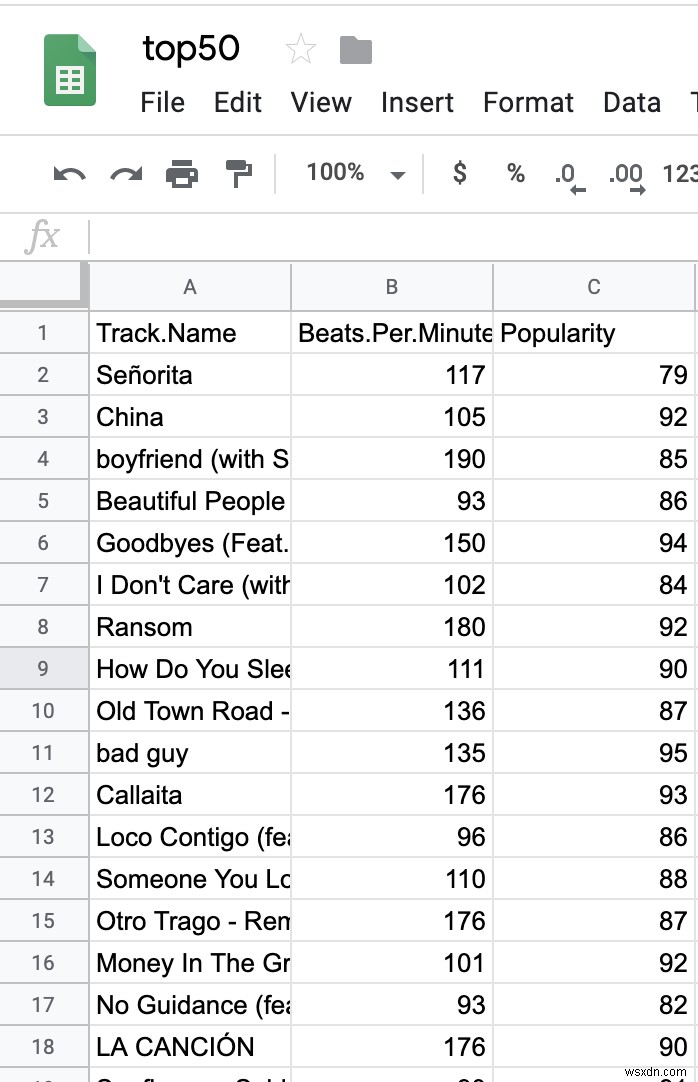
Sử dụng Ruby để thực hiện hồi quy
Trong ví dụ này, chúng tôi sẽ sử dụng ruby_linear_regression đá quý. Để cài đặt, hãy chạy:
gem install ruby_linear_regression
OK, chúng tôi đã sẵn sàng để bắt đầu viết mã! Tạo một tệp Ruby mới và thêm các yêu cầu này:
require "ruby_linear_regression"
require "csv"
Tiếp theo, chúng tôi đọc dữ liệu CSV của mình và gọi #shift , để loại bỏ hàng tiêu đề. Ngoài ra, bạn có thể chỉ cần xóa hàng đầu tiên khỏi tệp CSV.
csv = CSV.read("top50.csv")
csv.shift
Hãy tạo hai mảng trống để chứa các điểm dữ liệu x và điểm dữ liệu y của chúng ta.
x_data = []
y_data = []
... và chúng tôi lặp lại bằng cách sử dụng .each để thêm Beats Per Minute dữ liệu vào mảng x và Popularity của chúng tôi dữ liệu vào mảng y của chúng tôi.
Nếu bạn tò mò muốn xem điều gì đang thực sự xảy ra ở đây, bạn có thể thử nghiệm bằng cách ghi lại
rowcủa mình với mộtputshoặcp. Ví dụ:puts row
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
Bây giờ đã đến lúc sử dụng ruby_linear_regression đá quý. Chúng tôi sẽ tạo một phiên bản mới của mô hình hồi quy, tải dữ liệu và đào tạo mô hình của chúng tôi:
linear_regression = RubyLinearRegression.new
linear_regression.load_training_data(x_data, y_data)
linear_regression.train_normal_equation
Tiếp theo, chúng tôi sẽ in sai số bình phương trung bình (MSE) - một phép đo sự khác biệt giữa các giá trị quan sát và giá trị dự đoán. Sự khác biệt được bình phương để các giá trị âm và dương không triệt tiêu lẫn nhau. Chúng tôi muốn giảm thiểu MSE vì chúng tôi không muốn khoảng cách giữa các giá trị dự đoán và thực tế của chúng tôi lớn.
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
Cuối cùng, hãy để máy tính sử dụng mô hình của chúng ta để đưa ra dự đoán. Cụ thể, một bài hát có 250 BPM sẽ phổ biến như thế nào? Hãy thoải mái thử nghiệm với các giá trị khác nhau trong prediction_data mảng.
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
Kết quả
Hãy chạy chương trình trong bảng điều khiển của chúng tôi và xem những gì chúng tôi nhận được!
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 91
Mát mẻ! Hãy thay đổi "250" thành "50" và xem mô hình của chúng tôi dự đoán những gì.
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 86
Có vẻ như các bài hát có nhiều nhịp mỗi phút hơn phổ biến hơn.
Toàn bộ chương trình
Đây là toàn bộ tệp của tôi trông như thế nào:
require 'csv'
require 'ruby_linear_regression'
x_data = []
y_data = []
csv = CSV.read("top50.csv")
csv.shift
# Load data from CSV file into two arrays -- one for independent variables X (x_data) and one for the dependent variable y (y_data)
# Row[0] = title
# Row[1] = BPM
# Row[2] = Popularity
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
# Create regression model
linear_regression = RubyLinearRegression.new
# Load training data
linear_regression.load_training_data(x_data, y_data)
# Train the model using the normal equation
linear_regression.train_normal_equation
# Output the cost
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
# Predict the popularity of a song with 250 BPM
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
Các bước tiếp theo
Đây là một ví dụ rất đơn giản, nhưng tuy nhiên, bạn vừa chạy hồi quy tuyến tính đầu tiên của mình, đây là một kỹ thuật quan trọng được sử dụng cho học máy. Nếu bạn đang khao khát nhiều hơn, đây là một số điều khác bạn có thể làm tiếp theo:- Kiểm tra mã nguồn của viên ngọc Ruby mà chúng tôi đang sử dụng để xem phép toán đang diễn ra - Quay lại tập dữ liệu ban đầu và thử thêm các biến bổ sung vào mô hình và chạy hồi quy tuyến tính nhiều biến để xem liệu điều đó có thể làm giảm MSE của chúng tôi hay không. Ví dụ, có thể "hóa trị" (mức độ tích cực của bài hát) cũng đóng một vai trò trong sự phổ biến. - Hãy thử mô hình dốc xuống, mô hình này cũng có thể được chạy bằng cách sử dụng ruby_linear_regression đá quý.