Trong bài đăng này, chúng ta sẽ tìm hiểu những điều cơ bản về mạng nơ-ron và cách chúng ta có thể triển khai chúng bằng Ruby! Nếu bạn bị hấp dẫn bởi trí tuệ nhân tạo và học sâu nhưng không chắc chắn về cách bắt đầu, thì bài đăng này là dành cho bạn! Chúng tôi sẽ đi qua một ví dụ đơn giản để làm nổi bật các khái niệm chính. Rất ít khả năng bạn đã từng sử dụng Ruby để viết mạng nơ-ron nhiều lớp, nhưng để đơn giản và dễ đọc, đó là một cách tuyệt vời để hiểu những gì đang xảy ra. Đầu tiên, chúng ta hãy lùi lại một bước và xem xét cách chúng ta đến đây.
 Ảnh tĩnh từ bộ phim Ex Machnia. Tín dụng hình ảnh
Ảnh tĩnh từ bộ phim Ex Machnia. Tín dụng hình ảnh
Ex Machina là một bộ phim được phát hành vào năm 2014. Nếu bạn tra cứu tiêu đề trên Google, nó sẽ phân loại thể loại phim là "Chính kịch / Giả tưởng". Và, khi tôi lần đầu tiên xem bộ phim, nó có vẻ giống như khoa học viễn tưởng.
Nhưng, còn bao lâu nữa?
Nếu bạn hỏi Ray Kurzweil, một nhà tương lai học nổi tiếng làm việc tại Google, năm 2029 có thể là năm trí tuệ nhân tạo sẽ vượt qua bài kiểm tra Turing hợp lệ (đây là một thử nghiệm để xem liệu con người có thể phân biệt giữa máy móc / máy tính và con người khác hay không. ) Ông cũng dự đoán rằng điểm kỳ dị (khi máy tính vượt qua trí thông minh của con người) sẽ xuất hiện vào năm 2045.
Điều gì khiến Kurzweil tự tin đến vậy?
Sự xuất hiện của học sâu
Nói một cách đơn giản, học sâu là một tập hợp con của học máy sử dụng mạng thần kinh để trích xuất thông tin chi tiết từ lượng lớn dữ liệu. Các ứng dụng trong thế giới thực của học sâu bao gồm:- Xe tự lái- Phát hiện ung thư- Trợ lý ảo, chẳng hạn như Siri và Alexa - Dự đoán các hiện tượng thời tiết khắc nghiệt, chẳng hạn như động đất
Nhưng, "mạng thần kinh" là gì?
Mạng lưới thần kinh lấy tên từ các tế bào thần kinh, là các tế bào não xử lý và truyền thông tin thông qua các tín hiệu điện và hóa học. Sự thật thú vị:bộ não con người được tạo thành từ hơn 80 tỷ tế bào thần kinh!
Trong máy tính, mạng nơ-ron trông giống như sau:
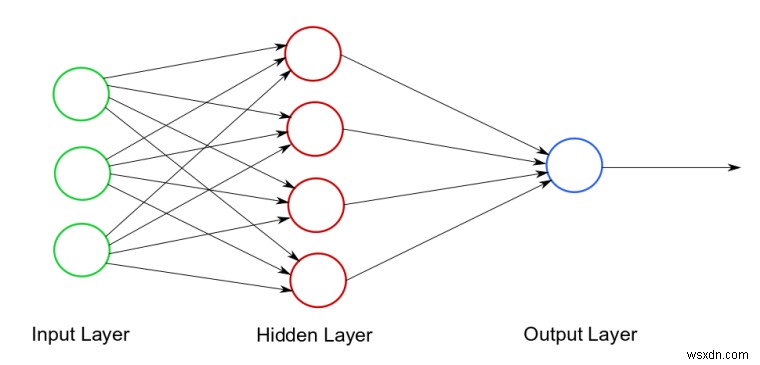 Ví dụ về sơ đồ mạng nơ-ron. Tín dụng hình ảnh
Ví dụ về sơ đồ mạng nơ-ron. Tín dụng hình ảnh
Như bạn thấy, có ba phần:1) Lớp đầu vào - Dữ liệu ban đầu 2) (Các) lớp ẩn - Một mạng nơ-ron có thể có 1 (hoặc nhiều) lớp ẩn. Đây là nơi tất cả các tính toán được thực hiện! 3) Lớp đầu ra - Kết quả cuối cùng / dự đoán
Bài học lịch sử nhanh
Mạng nơ-ron không phải là mới. Trên thực tế, mạng nơ-ron có thể huấn luyện đầu tiên (Perceptron) đã được phát triển tại Đại học Cornell vào những năm 1950. Tuy nhiên, có rất nhiều điều bi quan xung quanh khả năng ứng dụng của mạng nơ-ron, chủ yếu là do mô hình ban đầu chỉ bao gồm một lớp ẩn. Một cuốn sách xuất bản năm 1969 đã chỉ ra rằng việc sử dụng Perceptron để tính toán khá đơn giản sẽ không thực tế.
Sự trỗi dậy của mạng nơ-ron có thể là do các trò chơi máy tính, hiện nay đòi hỏi các đơn vị xử lý đồ họa (GPU) được hỗ trợ cực cao, có kiến trúc gần giống với mạng nơ-ron. Sự khác biệt là số lớp ẩn. Thay vì một, các mạng thần kinh được đào tạo ngày nay đang sử dụng 10, 15 hoặc thậm chí hơn 50 lớp!
Giờ mẫu!
Để hiểu cách hoạt động của điều này, hãy xem một ví dụ. Bạn sẽ cần cài đặt ruby-fann đá quý. Mở thiết bị đầu cuối của bạn và chuyển đến thư mục làm việc của bạn. Sau đó, chạy như sau:
gem install ruby-fann
Tạo một tệp Ruby mới (Tôi đặt tên là neural-net.rb của tôi ).
Tiếp theo, chúng tôi sẽ sử dụng tập dữ liệu "Mức tiêu thụ rượu của sinh viên" từ Kaggle. Bạn có thể tải về tại đây. Mở tệp "student-mat.csv" trong Google Trang tính (hoặc trình soạn thảo mà bạn chọn.) Xóa tất cả các cột ngoại trừ các cột sau:- Dalc (Mức tiêu thụ rượu trong ngày làm việc trong đó 1 là rất thấp và 5 là rất cao) - Walc (Mức tiêu thụ rượu vào cuối tuần trong đó 1 là rất thấp và 5 là rất cao) - G3 (Hạng cuối cùng từ 0 đến 20)
Chúng ta cần thay đổi cột cấp cuối cùng của mình thành nhị phân - 0 hoặc 1 - để đá quý ruby-fann hoạt động. Đối với ví dụ này, chúng tôi sẽ giả định rằng bất kỳ thứ gì nhỏ hơn hoặc bằng 10 là "0" và lớn hơn 10 là "1". Tùy thuộc vào chương trình bạn đang sử dụng, bạn có thể viết công thức trong ô để tự động thay đổi giá trị thành 1 hoặc 0 dựa trên giá trị của ô. Trong Google Trang tính, nó trông giống như sau:
=IF(C3 >= 10, 1, 0)
Lưu dữ liệu này dưới dạng tệp .CSV (Tôi đã đặt tên là students.csv của mình ) trong cùng thư mục với tệp Ruby của bạn.
Mạng nơ ron của chúng tôi sẽ có các lớp sau:- Lớp đầu vào:2 nút (mức tiêu thụ rượu trong ngày làm việc và mức tiêu thụ rượu vào cuối tuần) - Lớp ẩn:6 nút ẩn (điều này hơi tùy ý để bắt đầu; bạn có thể sửa đổi điều này sau khi bạn kiểm tra) - Đầu ra Lớp:1 nút (0 hoặc 1)
Đầu tiên, chúng ta cần yêu cầu ruby-fann gem, cũng như csv tích hợp sẵn thư viện. Thêm điều này vào dòng đầu tiên trong chương trình Ruby của bạn:
require 'ruby-fann'
require 'csv'
Tiếp theo, chúng ta cần tải dữ liệu từ tệp CSV của mình vào các mảng.
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
Tiếp theo, chúng ta cần chia dữ liệu của mình thành dữ liệu đào tạo và thử nghiệm. Sự phân chia 80/20 là khá phổ biến, trong đó 20% dữ liệu của bạn được sử dụng để thử nghiệm và 80% để đào tạo. "Đào tạo" ở đây có nghĩa là mô hình sẽ học dựa trên dữ liệu này và sau đó chúng tôi sẽ sử dụng dữ liệu "thử nghiệm" của mình để xem mô hình dự đoán kết quả tốt như thế nào.
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
Mát mẻ! Chúng tôi có sẵn dữ liệu của mình. Tiếp theo là điều kỳ diệu!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
Chúng tôi sử dụng đối tượng RubyFann ::TrainData và chuyển vào x_train_data, là mức tiêu thụ rượu trong ngày làm việc và cuối tuần của chúng tôi và y_train_data, của chúng tôi là 0 hoặc 1 dựa trên điểm cuối cùng của khóa học.
Bây giờ, hãy thiết lập mô hình mạng nơ-ron thực tế của chúng tôi với số lượng nơ-ron ẩn mà chúng ta đã thảo luận trước đó.
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
OK, đến lúc tập luyện!
model.train_on_data(train, 1000, 10, 0.01)
Ở đây, chúng tôi vượt qua train biến chúng tôi đã tạo trước đó. 1000 đại diện cho số lượng max_epochs, 10 đại diện cho số lỗi giữa các báo cáo và 0,1 là sai số trung bình mong muốn của chúng tôi. Một kỷ nguyên là khi toàn bộ tập dữ liệu được chuyển qua mạng nơ-ron. Sai số trung bình bình phương là những gì chúng tôi đang cố gắng giảm thiểu. Bạn có thể đọc thêm về ý nghĩa của điều này tại đây.
Tiếp theo, chúng tôi muốn biết mô hình của chúng tôi đã hoạt động tốt như thế nào bằng cách so sánh những gì mô hình dự đoán cho dữ liệu thử nghiệm của chúng tôi với kết quả thực tế. Chúng tôi có thể thực hiện điều này bằng cách sử dụng mã này:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
Hãy chạy chương trình của chúng tôi và xem điều gì sẽ xảy ra!
ruby neural-net.rb
Bạn sẽ thấy rất nhiều đầu ra cho Epochs, nhưng ở dưới cùng, bạn sẽ thấy một cái gì đó như sau:
Accuracy: 56.82% - test set of size 20.0%
Oof, điều đó không tốt lắm! Tuy nhiên, hãy đưa ra các điểm dữ liệu của riêng chúng tôi và chạy mô hình.
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
Ở đây, chúng tôi có hai ví dụ. Đầu tiên, chúng tôi sẽ vượt qua trong 1 giây cho việc uống rượu vào các ngày trong tuần và cuối tuần của chúng tôi. Nếu tôi là một người cá cược, tôi sẽ đoán rằng học sinh này sẽ có điểm tổng kết trên 10 (tức là 1). Ví dụ thứ hai chuyển các giá trị cao (5 và 4) cho việc uống rượu, vì vậy tôi đoán rằng học sinh này sẽ có điểm tổng kết bằng hoặc dưới 10 (tức là 0). Hãy chạy lại chương trình của chúng tôi và xem điều gì sẽ xảy ra!
Đầu ra của bạn sẽ giống như sau:
Algorithm predicted class: [1]
Algorithm predicted class: [0]
Mô hình của chúng tôi dường như thực hiện những gì chúng tôi mong đợi đối với các con số ở đầu thấp hơn hoặc cao hơn của quang phổ. Tuy nhiên, nó gặp khó khăn khi các con số đối lập nhau (hãy thử các kết hợp khác nhau - 1 và 5, hoặc 2 và 3 làm ví dụ) hoặc ở giữa. Chúng tôi cũng có thể thấy từ dữ liệu Epoch của mình rằng, mặc dù lỗi không giảm, nhưng nó vẫn rất cao (giữa 20%). Điều này có nghĩa là có thể không có mối quan hệ giữa mức tiêu thụ rượu và điểm khóa học. Tôi khuyến khích bạn sử dụng tập dữ liệu gốc từ Kaggle - có những biến số độc lập nào khác mà chúng ta có thể sử dụng để dự đoán kết quả khóa học không?
Kết thúc
Có rất nhiều điều phức tạp (chủ yếu là liên quan đến toán học) xảy ra để thực hiện tất cả các công việc này. Nếu bạn tò mò và muốn tìm hiểu thêm, tôi thực sự khuyên bạn nên xem qua tài liệu trên FANN hoặc xem mã nguồn của ruby-fann đá quý. Tôi cũng khuyên bạn nên xem phim tài liệu "AlphaGo" trên Netflix - nó không đòi hỏi nhiều kiến thức kỹ thuật để thưởng thức nó và đưa ra một ví dụ thực tế tuyệt vời về việc học sâu đang đẩy giới hạn những gì máy tính có thể đạt được.
Liệu Kurzweil có đúng với dự đoán của mình? Chỉ có thời gian sẽ trả lời!