
Một trong những tính năng mới thú vị nhất trong Elasticsearch 5 là nút nhập, bổ sung một số xử lý kiểu Logstash vào cụm Elasticsearch, vì vậy dữ liệu có thể được chuyển đổi trước khi được lập chỉ mục mà không cần dịch vụ và / hoặc cơ sở hạ tầng khác để thực hiện. Cách đây ít lâu, chúng tôi đã đăng một blog nhanh về cách phân tích cú pháp tệp csv bằng Logstash, vì vậy, tôi muốn cung cấp phiên bản đường dẫn nhập của nó để tiện so sánh.
Những gì chúng tôi sẽ hiển thị ở đây là một ví dụ sử dụng Filebeat để chuyển dữ liệu đến một đường dẫn nhập, lập chỉ mục và trực quan hóa nó bằng Kibana.
Dữ liệu
Có rất nhiều nguồn tuyệt vời cho dữ liệu miễn phí, nhưng vì hầu hết chúng tôi tại ObjectRocket đều ở Austin, TX, chúng tôi sẽ sử dụng một số dữ liệu từ data.austintexas.gov. Tập dữ liệu kiểm tra nhà hàng là một tập dữ liệu có kích thước tốt có đủ thông tin liên quan để cung cấp cho chúng tôi một ví dụ thực tế.
Dưới đây là một vài dòng từ tập dữ liệu này để cung cấp cho bạn ý tưởng về cấu trúc của dữ liệu:
Restaurant Name,Zip Code,Inspection Date,Score,Address,Facility ID,Process Description
Westminster Manor,78731,07/21/2015,96,"4100 JACKSON AVE
AUSTIN, TX 78731
(30.314499, -97.755166)",2800365,Routine Inspection
Wieland Elementary,78660,10/02/2014,100,"900 TUDOR HOUSE RD
AUSTIN, TX 78660
(30.422862, -97.640183)",10051637,Routine Inspection
DOH… Đây sẽ không phải là một dòng đơn đẹp, thân thiện cho mỗi mục nhập, nhưng điều đó ổn. Như bạn sắp thấy, Filebeat có một số khả năng tích hợp để xử lý các mục nhập nhiều dòng và giải quyết các dòng mới bị chôn vùi trong dữ liệu.
Biên tập viên:Tôi đã lên kế hoạch về một ví dụ đơn giản hay với một vài "lỗi", nhưng cuối cùng, tôi nghĩ có thể thú vị khi xem một số công cụ mà Elastic Stack cung cấp cho bạn để giải quyết các tình huống này.
Thiết lập Filebeat
Bước đầu tiên là chuẩn bị sẵn sàng cho Filebeat để bắt đầu chuyển dữ liệu đến cụm Elasticsearch của bạn. Sau khi bạn đã tải xuống Filebeat (hãy thử sử dụng cùng một phiên bản với cụm ES của bạn) và được giải nén, việc thiết lập cực kỳ đơn giản thông qua tệp cấu hình filebeat.yml đi kèm. Đối với tình huống của chúng tôi, đây là cấu hình mà tôi đang sử dụng.
filebeat.prospectors:
- input_type: log
paths:
- /Path/To/logs/*.csv
# Ignore the first line with column headings
exclude_lines: ["^Restaurant Name,"]
# Identifies the last two columns as the end of an entry and then prepends the previous lines to it
multiline.pattern: ',\d+,[^\",]+$'
multiline.negate: true
multiline.match: before
#================================ Outputs =====================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["https://dfw-xxxxx-0.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-1.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-2.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-3.es.objectrocket.com:xxxxx"]
pipeline: "inspectioncsvs"
# Optional protocol and basic auth credentials.
username: "esuser"
password: "supersecretpassword"
Mọi thứ khá đơn giản ở đây; bạn có một phần để chỉ định vị trí và cách lấy các tệp đầu vào và một phần để chỉ định nơi gửi dữ liệu. Phần duy nhất tôi sẽ gọi cụ thể là bit đa dòng và phần cấu hình Elasticsearch.
Vì định dạng cho tập dữ liệu này không quá nghiêm ngặt, với việc sử dụng dấu ngoặc kép không nhất quán và một số dòng mới được rắc vào, tùy chọn tốt nhất là tìm kiếm phần cuối của một mục nhập, bao gồm một ID số, sau đó là một loại kiểm tra mà không có nhiều biến thể hoặc dấu ngoặc kép / dòng mới. Từ đó, Filebeat sẽ chỉ xếp hàng bất kỳ dòng nào chưa khớp và thêm chúng vào dòng cuối cùng khớp với mẫu. Nếu dữ liệu của bạn sạch hơn và dính vào một dòng đơn giản cho mỗi mục nhập, bạn có thể bỏ qua cài đặt nhiều dòng.
Nhìn vào phần đầu ra của Elasticsearch, đó là cài đặt Elasticsearch tiêu chuẩn với phần bổ sung nhỏ tên của đường dẫn mà bạn muốn sử dụng với chỉ thị:đường ống. Nếu đang sử dụng dịch vụ ObjectRocket, bạn chỉ có thể lấy đoạn mã đầu ra từ tab “Kết nối” trong giao diện người dùng, sẽ được tích hợp sẵn với tất cả các máy chủ phù hợp và chỉ cần thêm đường dẫn và điền vào người dùng và mật khẩu của bạn. . Ngoài ra, hãy đảm bảo rằng bạn đã thêm IP của hệ thống vào ACL của cụm nếu bạn chưa làm như vậy.
Tạo đường dẫn nhập
Bây giờ chúng tôi đã có dữ liệu đầu vào và Filebeat đã sẵn sàng, chúng tôi có thể tạo và điều chỉnh đường dẫn nhập của mình. Các nhiệm vụ chính mà đường ống cần thực hiện là:
- Chia nội dung csv thành các trường chính xác
- Chuyển đổi điểm kiểm tra thành số nguyên
- Đặt
@timestamplĩnh vực - Xóa một số định dạng dữ liệu khác
Dưới đây là một quy trình có thể thực hiện tất cả những điều đó:
PUT _ingest/pipeline/inspectioncsvs
{
"description" : "Convert Restaurant inspections csv data to indexed data",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["%{REST_NAME:RestaurantName},%{REST_ZIP:ZipCode},%{MONTHNUM2:InspectionMonth}/%{MONTHDAY:InspectionDay}/%{YEAR:InspectionYear},%{NUMBER:Score},\"%{DATA:StreetAddress}\n%{DATA:City},?\\s+%{WORD:State}\\s*%{NUMBER:ZipCode2}\\s*\n\\(?%{DATA:Location}\\)?\",%{NUMBER:FacilityID},%{DATA:InspectionType}$"],
"pattern_definitions": {
"REST_NAME": "%{DATA}|%{QUOTEDSTRING}",
"REST_ZIP": "%{QUOTEDSTRING}|%{NUMBER}"
}
}
},
{
"grok": {
"field": "ZipCode",
"patterns": [".*%{ZIP:ZipCode}\"?$"],
"pattern_definitions": {
"ZIP": "\\d{5}"
}
}
},
{
"convert": {
"field" : "Score",
"type": "integer"
}
},
{
"set": {
"field" : "@timestamp",
"value" : "//"
}
},
{
"date" : {
"field" : "@timestamp",
"formats" : ["yyyy/MM/dd"]
}
}
],
"on_failure" : [
{
"set" : {
"field" : "error",
"value" : " - Error processing message - "
}
}
]
}
Không giống như Logstash, quy trình nhập không (tại thời điểm viết bài này) có bộ xử lý / plugin csv, vì vậy bạn sẽ cần phải tự mình chuyển đổi csv. Tôi đã sử dụng một bộ xử lý rãnh để thực hiện việc nâng nặng, vì mỗi hàng chỉ có một vài cột. Đối với dữ liệu có nhiều cột hơn, bộ xử lý rãnh có thể trở nên khá phức tạp, vì vậy một tùy chọn khác là sử dụng bộ xử lý phân tách và một số tập lệnh đơn giản để xử lý dòng theo kiểu lặp đi lặp lại nhiều hơn. Bạn cũng có thể nhận thấy bộ xử lý thứ hai, bộ xử lý này chỉ ở đó để xử lý hai cách khác nhau mà mã zip được nhập vào tập dữ liệu này.
Đối với mục đích gỡ lỗi, tôi đã bao gồm một phần on_failure chung sẽ bắt tất cả các lỗi và in ra loại bộ xử lý nào bị lỗi và thông báo đã phá vỡ đường ống là gì. Điều này làm cho cách gỡ lỗi dễ dàng hơn. Tôi chỉ có thể truy vấn chỉ mục của mình cho bất kỳ tài liệu nào đã đặt lỗi và sau đó có thể gỡ lỗi bằng API mô phỏng. Nhiều hơn về điều đó ngay bây giờ…
Kiểm tra đường ống
Bây giờ chúng ta đã định cấu hình đường dẫn nhập của mình, hãy thử nghiệm và chạy nó với API mô phỏng. Trước tiên, bạn sẽ cần một tài liệu mẫu. Bạn có thể làm điều này theo một số cách. Bạn có thể chạy Filebeat mà không cần cài đặt đường dẫn và sau đó chỉ cần lấy tài liệu chưa xử lý từ Elasticsearch hoặc bạn có thể chạy Filebeat với đầu ra bảng điều khiển được bật, bằng cách nhận xét phần Elasticsearch và thêm phần sau vào tệp yml:
output.console:
pretty: true
Đây là tài liệu mẫu mà tôi lấy được từ môi trường của mình:
POST _ingest/pipeline/inspectioncsvs/_simulate
{
"docs" : [
{
"_index": "inspections",
"_type": "log",
"_id": "AVpsUYR_du9kwoEnKsSA",
"_score": 1,
"_source": {
"@timestamp": "2017-03-31T18:22:25.981Z",
"beat": {
"hostname": "systemx",
"name": "RestReviews",
"version": "5.1.1"
},
"input_type": "log",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"offset": 2109798,
"source": "/Path/to/my/logs/Restaurant_Inspection_Scores.csv",
"tags": [
"debug",
"reviews"
],
"type": "log"
}
}
]
}
Và câu trả lời (tôi đã cắt nó xuống các trường chúng tôi đang cố gắng đặt):
{
"docs": [
{
"doc": {
"_id": "AVpsUYR_du9kwoEnKsSA",
"_type": "log",
"_index": "inspections",
"_source": {
"InspectionType": "Routine Inspection",
"ZipCode": "78660",
"InspectionMonth": "10",
"City": "AUSTIN",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"RestaurantName": "Wieland Elementary",
"FacilityID": "10051637",
"Score": 100,
"StreetAddress": "900 TUDOR HOUSE RD",
"State": "TX",
"InspectionDay": "02",
"InspectionYear": "2014",
"ZipCode2": "78660",
"Location": "30.422862, -97.640183"
},
"_ingest": {
"timestamp": "2017-03-31T20:36:59.574+0000"
}
}
}
]
}
Quy trình chắc chắn đã thành công, nhưng quan trọng nhất, tất cả dữ liệu dường như ở đúng vị trí.
Đang chạy filebeat
Trước khi chạy Filebeat, chúng tôi sẽ làm một việc cuối cùng. Phần này là hoàn toàn tùy chọn nếu bạn chỉ muốn làm quen với đường dẫn nhập, nhưng nếu bạn muốn sử dụng trường Vị trí mà chúng tôi đặt trong bộ xử lý hàng hóa làm Điểm địa lý, bạn sẽ cần thêm ánh xạ vào filebeat. tệp template.json, bằng cách thêm phần sau vào phần thuộc tính:
"Location": {
"type": "geo_point"
},
Bây giờ không còn cách nào khác, chúng ta có thể kích hoạt Filebeat bằng cách chạy ./filebeat -e -c filebeat.yml -d “asticsearch ”.
Sử dụng dữ liệu
GET /filebeat-*/_count
{}
{
"count": 25081,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
Đó là một dấu hiệu tốt! Hãy xem chúng tôi có gặp lỗi nào không:
GET /filebeat-*/_search
{
"query": {
"exists" : { "field" : "error" }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
Một dấu hiệu tốt nữa!
Bây giờ, chúng tôi đã sẵn sàng để trực quan hóa và hiển thị dữ liệu của mình trong Kibana. Chúng ta có thể hướng dẫn cách tạo trang tổng quan Kibana vào lần khác, nhưng vì chúng ta đã có ngày tháng, tên nhà hàng, điểm số và địa điểm, chúng ta có nhiều quyền tự do để tạo một số hình ảnh trực quan thú vị.
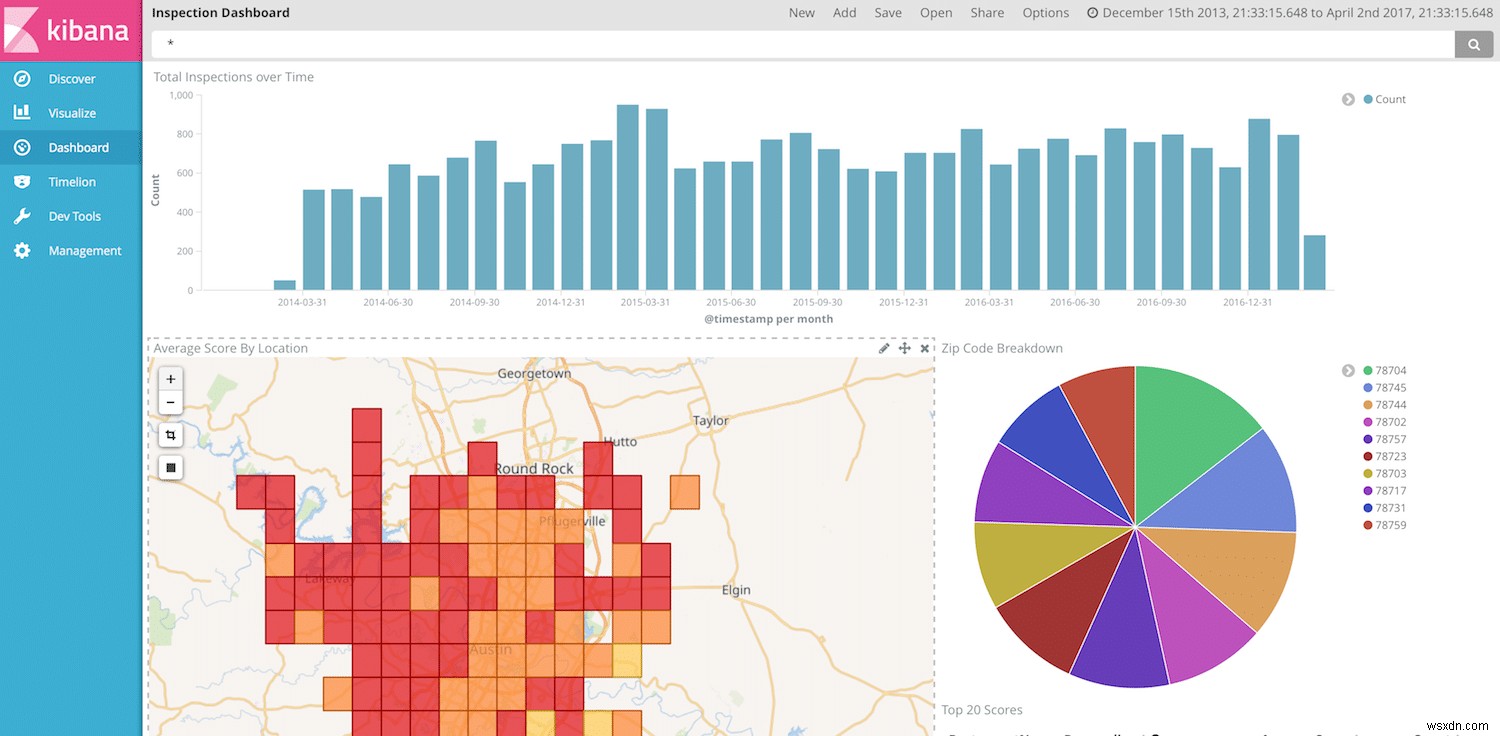
Ghi chú cuối cùng
Một lần nữa, đường dẫn nhập khá mạnh mẽ và có thể xử lý các chuyển đổi khá dễ dàng. Bạn có thể di chuyển tất cả quá trình xử lý của mình sang Elasticsearch và chỉ sử dụng Beats nhẹ trên máy chủ của mình mà không yêu cầu Logstash ở đâu đó trong đường dẫn. Tuy nhiên, vẫn còn một số khoảng cách trong nút nhập so với Logstash. Ví dụ:số lượng bộ xử lý có sẵn trong đường dẫn nhập vẫn còn hạn chế, vì vậy các tác vụ đơn giản như phân tích cú pháp CSV không dễ dàng như trong Logstash. Nhóm Elasticsearch dường như thường xuyên tung ra các bộ xử lý mới, vì vậy, hy vọng rằng danh sách các điểm khác biệt sẽ ngày càng nhỏ hơn.