Rất nhiều người trong chúng ta đã cảm thấy khó chịu và lo lắng vì cửa sổ bật lên xuất hiện khi bạn cố gắng truy cập một trang web thông qua Google Chrome, yêu cầu bạn xác nhận xem bạn có phải là con người hay không. Câu hỏi lần này có vẻ là điều ngu ngốc nhất, đặc biệt nếu nó cứ hiện lên trên khuôn mặt bạn nhiều lần. Đó là CAPTCHA, một bài kiểm tra phản hồi thử thách cho phép trình duyệt xác định rằng đó không phải là một số máy đang cố gắng truy cập vào các tìm kiếm cá nhân của bạn. CAPTCHA đã trở thành một biện pháp bảo vệ phổ biến để ngăn chặn chương trình thư rác trên internet và ngăn chặn việc lạm dụng. Nhưng trong những năm gần đây, CAPTCHA đã được mở rộng và cũng trở thành một nhiệm vụ phức tạp đòi hỏi chúng tôi phải tập trung vào cái gọi là thử thách ứng phó. Tại sao trình duyệt của bạn yêu cầu bạn xác nhận “Tôi không phải là rô bốt”? Và làm thế nào nó chuyển sang một thử thách khó chịu và tốn thời gian? Hãy đọc cách một thứ khởi đầu như một công cụ để loại bỏ spam bots, giờ đã trở thành một cuộc chạy đua cam go giữa con người và máy móc.
CAPTCHA là gì?
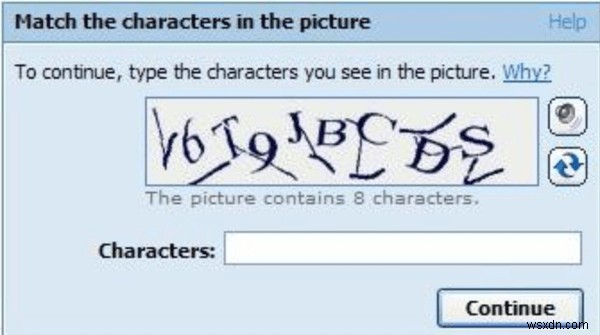
CAPTCHA là viết tắt của Kiểm tra Turing Công cộng Hoàn toàn Tự động. Nó được phát triển vào khoảng đầu những năm 2000 như một thử nghiệm để con người chứng minh rằng họ không phải là máy móc hay chương trình thư rác đang cố gắng vi phạm bảo mật của trình duyệt. Mặc dù việc phát minh ra CAPTCHA là một vấn đề còn tranh luận khác, nhưng phiên bản đầu tiên của nó có từ năm 1997. Khi lần đầu tiên được sử dụng, CAPTCHA từng yêu cầu người dùng chứng minh “tính nhân văn” của họ bằng cách gõ một chuỗi các chữ cái bị bóp méo trong văn bản đơn giản. Trong một số trình tự, các chữ cái bị bóp méo được kết hợp với nhau bằng các số được viết ở dạng méo tương tự. Các ký tự này được viết theo cách mà dường như không có khoảng trống giữa chúng và mã được thay đổi trong mỗi lần đăng nhập. Điều này được thực hiện bởi vì, để giải mã một số lượng gần như vô hạn các chuỗi bị bóp méo, luôn luôn cần một số trí thông minh của con người; trong khi đó, một thuật toán máy tính không thể phát hiện các chuỗi bị méo. Do đó, CAPTCHA ngay lập tức được nhiều nhà cung cấp dịch vụ web và thư chấp nhận.
Nhưng sau đó trong vài năm tới, CAPTCHA trở nên phức tạp.
reCAPTCHA của Google:Nâng cấp phức tạp lên Thử nghiệm ban đầu
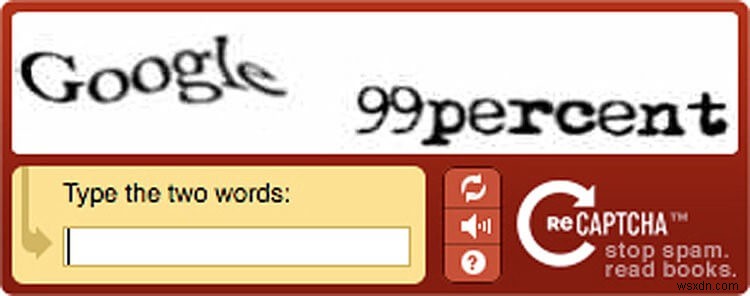
Vào năm 2007, Google đã mua lại chương trình có tên reCAPTCHA từ một nhóm các nhà nghiên cứu ban đầu của hệ thống và bắt đầu sử dụng nó rộng rãi trong Google Scholar và Google Books. Tuy nhiên, từ nơi nó bắt đầu, CAPTCHA ở dạng mới nhất này đã trở thành một vấn đề đau đầu đối với người dùng Google. Khi nghiên cứu về máy học ngày càng phát triển, khả năng của các hệ thống máy tính và các thuật toán của chúng để giải quyết các vấn đề phức tạp cũng tăng theo. Do đó, các chuỗi ký tự ban đầu trở nên quá dễ dàng đối với bot và máy móc để giải quyết. Vì vậy, Google đã đi trước và làm cho những ký tự đó trở nên xoắn hơn và khó hiểu hơn về mặt kỹ thuật đối với mắt người. Điều này thực sự đã bắt đầu cuộc chạy đua thực sự giữa trí thông minh của con người và máy móc, điều này đã chuyển thành sự khó chịu thực sự mà reCAPTCHA đã trở thành đối với người dùng Google. Để đảm bảo rằng người dùng truy cập vào các nền tảng và tìm kiếm của Google không phải là một số bot, Google đã làm cho các chuỗi khó giải quyết hơn.
Thêm hình ảnh vào thử nghiệm:Google's No CAPTCHA reCAPTCHA
Vào năm 2014, rất muộn sau khi Google mua lại reCaptcha, nó đã quyết định hành động vì sự khó chịu mà các chuỗi của nó đã gây ra cho người dùng. Thêm vào đó, trong ngần ấy năm, một lần nữa các nhà nghiên cứu để tạo ra những cỗ máy thông minh hơn đã vượt trội hơn khả năng hiểu các thách thức phản ứng của reCAPTCHA. Trong một thử nghiệm thử nghiệm, các nhà nghiên cứu của Google đã xác định rằng mặc dù rất phức tạp và các cửa sổ bật lên gây phiền nhiễu, các thuật toán học máy có thể nhận được hơn 99% phản hồi chính xác trong khi con người chúng ta hầu như không quản lý được 33%. Vì vậy, đã đến lúc phải thay đổi.

Google đã quyết định giảm bớt sự khó chịu của người dùng. “NoCAPTCHA reCAPTCHA” mới cho phép người dùng vượt qua bài kiểm tra bằng cách nhấp vào hộp đánh dấu. Lần này, Google đã đi trước với công nghệ API và sử dụng các tùy chọn của người dùng để xác định xem đó là người hay rô bốt. ReCAPTCHA mới của Google đã phân tích các tìm kiếm của người dùng cũng như chuyển động của con trỏ chuột. Bot không thể mô phỏng một cú nhấp chuột như đối với bot, phân tích mã cho bài kiểm tra CAPTCHA cụ thể đó sẽ thấy hộp đánh dấu ảo đó dưới dạng hình ảnh đồ họa và sẽ không phản hồi điều đó. Nhưng một lần nữa, nếu bot có thể đọc JavaScript, thì nó có thể dễ dàng mô phỏng điều đó và tùy chọn theo dõi chuyển động của chuột sẽ không thành công.
Vì vậy, làm thế nào bạn giải quyết vấn đề đó đúng? Và, điều gì sẽ xảy ra nếu bạn thực hiện một tìm kiếm khác với tùy chọn của mình?

Vâng, trong trường hợp đó, chào mừng bạn đến với một bài kiểm tra khác. ReCAPTCHA mới của Google đưa bạn đến một loạt "bài kiểm tra bằng mắt" để xem bạn là người hay rô bốt. Vì vậy, trong trường hợp bạn thực hiện một tìm kiếm không mong muốn hoặc đáng ngờ, Google sẽ yêu cầu bạn chọn một số hình ảnh cụ thể từ toàn bộ nhóm chúng. Tất cả chúng ta đều nhận thấy Google yêu cầu chúng ta xác định hình ảnh với đèn giao thông, ô tô, công viên hoặc biển báo đường bộ, phải không? NoCAPTCHA reCAPTCHA là như vậy.
Đây là phiên bản cập nhật nhất và được sử dụng rộng rãi nhất của CAPTCHA, được sử dụng như một phương tiện phân biệt giữa con người và AI bởi không chỉ Google mà các nền tảng như Twitter, Facebook và Craigslist để ngăn chặn spam và lạm dụng hồ sơ mạng xã hội của người dùng. Nhưng một lần nữa, những hình ảnh trong phiên bản này trở nên mờ hơn đối với mắt người, làm tăng độ phức tạp của câu đố và một lần nữa lại đi đúng con đường mà reCAPTCHA đã đi trước đó.
Nhưng tại sao?
Tại sao Câu đố CAPTCHA lại phức tạp đến vậy?

CAPTCHA được bắt đầu như một phương tiện để ngăn chặn bot và máy móc bắt chước như người dùng của con người và truy cập bất kỳ loại dữ liệu nào với mục đích sai trái. Nhưng khi các nghiên cứu và thử nghiệm về học máy và trí tuệ nhân tạo đã đi quá xa và thậm chí đã thành công, chúng tôi đã tạo ra những cỗ máy có khả năng giải quyết nhiều phép tính phức tạp và CAPTCHA đã trở thành một miếng bánh. Khoa học đã ban cho máy móc những khả năng sâu rộng đến mức bây giờ nếu chúng ta cố gắng tạo ra thứ gì đó khó cho phần mềm hoặc bot, con người sẽ khó giải mã hơn.
Có quá ngạc nhiên rằng CAPTCHA bằng cách nào đó không thành công không?

Chắc chắn không phải. Chúng tôi đã tạo ra các máy tính lượng tử chức năng. Chúng tôi đã giải quyết hàng trăm câu đố và vấn đề tính toán liên quan đến phân tích tài chính, quyết định kinh doanh và khoa học y tế. Chúng tôi đã sử dụng rất nhiều ứng dụng và công cụ dựa trên máy móc để giảm bớt cuộc sống của chúng tôi và giúp chúng tôi trong các lĩnh vực nghiên cứu phức tạp hơn. Và trong khi đó, chúng tôi đã cung cấp cho các cỗ máy trí thông minh của riêng chúng để tăng tốc độ và hiệu quả tác vụ. Vì cuộc sống của chúng ta phụ thuộc rất nhiều vào AI và máy học, nên việc nó vượt qua chúng ta chỉ là vấn đề thời gian.
CAPTCHA có thể tiến xa hơn trong khoảng thời gian nào?

Theo những gì các nhà nghiên cứu đang làm với cơ chế phản ứng-thách thức này, đây mới chỉ là bước khởi đầu. Đã có nhiều thử nghiệm khác nhau để nâng cấp các công cụ CAPTCHA hiện tại và thay đổi cách thức tiến hành các thử nghiệm thử thách phản ứng này. Vào năm 2017, PayPal đã nhận được bằng sáng chế cho một loại kỹ thuật CAPTCHA mới. Ở đây, các câu đố và câu hỏi được đặt ra cho người dùng để chứng minh tính nhân văn của họ sẽ khác nhau tùy theo dân tộc, vị trí và giới tính của họ. Tương tự, Amazon Technologies đã được cấp bằng sáng chế cho phong cách giải đố CAPTCHA, nơi mọi người sẽ được yêu cầu giải các ảo ảnh quang học và các câu đố logic điển hình, vốn không quen thuộc với họ. Bây giờ, ở đây Amazon đã cố gắng đảo ngược câu đố. Amazon Technologies đã tuyên bố rằng hầu hết con người sẽ nhận được những phản hồi như vậy sai, trong khi AI hiện đại, với khả năng của nó, sẽ làm đúng và do đó, phản ứng với phản hồi sai sẽ là người dùng. Các bằng sáng chế khác bao gồm câu đố giống trò chơi cho CAPTCHA, trong đó người dùng sẽ yêu cầu giải các loại hình ảnh câu đố trên bảng để chứng minh tính nhân văn của họ. Đây là một số ý tưởng ban đầu đang tìm cách cập nhật CAPTCHA.
Nhưng chúng có thực sự hiệu quả không?

Theo nhiều cách, chúng không phải vậy. Thứ nhất, trong thế hệ “thời đại không gian” này, nơi học máy thực sự là bước tiếp theo trong quá trình tiến hóa của loài người, không có CAPTCHA nào sẽ không bị gián đoạn. -Thứ hai, những ý tưởng này quá phức tạp đối với con người. Nếu bạn luôn mong đợi một anh chàng trả lời đúng câu hỏi đa dạng về văn hóa, thì bạn đã nhầm. Mọi người khác nhau về dân tộc, ngôn ngữ và tính cách ở quy mô rất lớn và gần như không thể phát triển một loạt các thách thức đối phó dựa trên nền tảng văn hóa như vậy. Hơn nữa, Internet là một thứ gì đó, bất kỳ ai từ bất cứ đâu đều có thể truy cập được bất kể chỉ số IQ, độ tuổi và mức độ thông minh của người đó. Vì vậy, thật khó tin rằng mọi người ở mọi lứa tuổi đều có sẵn trong mình khả năng giải câu đố trò chơi trên bàn cờ để vượt qua một trang web. Có thể, các nhà nghiên cứu, để duy trì khả năng chống lại sự can thiệp của máy móc đã quên mất con người là như thế nào và đã loại bỏ yếu tố đó khỏi những phát triển gần đây của họ.
Có thể làm gì để CAPTCHA đáng tin cậy hơn?
Chà, đó là một chủ đề của một cuộc thảo luận và nghiên cứu lớn trước khi chúng ta có thể đưa ra một thứ gì đó có thể giúp con người dễ dàng hơn. Tuy nhiên, cần phải tìm kiếm một số khía cạnh của hành vi con người mà một bot AI có thể không bắt chước được. Có thể chuyển hướng tập trung hơn sang phát triển các công cụ CAPTCHA để tìm kiếm các “hành động” trên trang web. Gần đây, Google đã kích hoạt Phiên bản 3 của reCAPTCHA được gọi là reCAPTCHA v3. The new version of the response-challenge test by Google use what’s called “Adaptive Risk Analysis”, which do not push users to any sort of test and don’t ask them for ticking up the virtual box. It’s completely friction-free for users and allows them to access webpages directly. To carry out bot detection for preventing spam abuse, Google’s new reCAPTCHA would allow website owners to determine whether their site users are a bot or not, via scores that Google would give them based on its risk analysis algorithm. The score would detect if the traffic on the site is suspicious or not. Owners can then present suspicious users with a response test to cross-check reCAPTCHA’s detection. While Google won’t tell how their new algorithm would assign these scores to users, it can be considered as a welcoming medium of filtering traffic, where users’ annoyance and difficulty to solve the earlier tests has been considered.
Final Opinion

It’s too early to say that Google’s new reCAPTCHA v3 is the best and most user-friendly way to avoid bot traffic on webpages. Moreover, the pace at which AI and machine learning research are moving ahead, we cannot know of implications that would have on any new CAPTCHA technique.
Since people are putting more stakes at machine learning and not on surveillance on machine activities, all these new patents of CAPTCHA techniques may become non-viable in the near future. For now, CAPTCHA remains the most widely used response-challenge test for bot detection on the web. But to have it that way for more and more years, it is important that methods of the distinction between AI and humans are discovered before we pass on everything we have and whatever defines our legacy to the smart machines we are being dependent on.